 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAGPPI: RAG Benchmark for Protein-Protein Interactions in Drug Discovery
May 28, 2025Retrieving the biological impacts of protein-protein interactions (PPIs) is essential for target identification (Target ID) in drug development. Given the vast number of proteins involved, this process remains time-consuming and challenging. Large Language Models (LLMs) and Retrieval-Augmented Generation (RAG) frameworks have supported Target ID; however, no benchmark currently exists for identifying the biological impacts of PPIs. To bridge this gap, we introduce the RAG Benchmark for PPIs (RAGPPI), a factual question-answer benchmark of 4,420 question-answer pairs that focus on the potential biological impacts of PPIs. Through interviews with experts, we identified criteria for a benchmark dataset, such as a type of QA and source. We built a gold-standard dataset (500 QA pairs) through expert-driven data annotation. We developed an ensemble auto-evaluation LLM that reflected expert labeling characteristics, which facilitates the construction of a silver-standard dataset (3,720 QA pairs). We are committed to maintaining RAGPPI as a resource to support the research community in advancing RAG systems for drug discovery QA solutions.
DeTra: A Unified Model for Object Detection and Trajectory Forecasting
Jun 06, 2024The tasks of object detection and trajectory forecasting play a crucial role in understanding the scene for autonomous driving. These tasks are typically executed in a cascading manner, making them prone to compounding errors. Furthermore, there is usually a very thin interface between the two tasks, creating a lossy information bottleneck. To address these challenges, our approach formulates the union of the two tasks as a trajectory refinement problem, where the first pose is the detection (current time), and the subsequent poses are the waypoints of the multiple forecasts (future time). To tackle this unified task, we design a refinement transformer that infers the presence, pose, and multi-modal future behaviors of objects directly from LiDAR point clouds and high-definition maps. We call this model DeTra, short for object Detection and Trajectory forecasting. In our experiments, we observe that \ourmodel{} outperforms the state-of-the-art on Argoverse 2 Sensor and Waymo Open Dataset by a large margin, across a broad range of metrics. Last but not least, we perform extensive ablation studies that show the value of refinement for this task, that every proposed component contributes positively to its performance, and that key design choices were made.
Nucleus subtype classification using inter-modality learning
Jan 29, 2024Understanding the way cells communicate, co-locate, and interrelate is essential to understanding human physiology. Hematoxylin and eosin (H&E) staining is ubiquitously available both for clinical studies and research. The Colon Nucleus Identification and Classification (CoNIC) Challenge has recently innovated on robust artificial intelligence labeling of six cell types on H&E stains of the colon. However, this is a very small fraction of the number of potential cell classification types. Specifically, the CoNIC Challenge is unable to classify epithelial subtypes (progenitor, endocrine, goblet), lymphocyte subtypes (B, helper T, cytotoxic T), or connective subtypes (fibroblasts, stromal). In this paper, we propose to use inter-modality learning to label previously un-labelable cell types on virtual H&E. We leveraged multiplexed immunofluorescence (MxIF) histology imaging to identify 14 subclasses of cell types. We performed style transfer to synthesize virtual H&E from MxIF and transferred the higher density labels from MxIF to these virtual H&E images. We then evaluated the efficacy of learning in this approach. We identified helper T and progenitor nuclei with positive predictive values of $0.34 \pm 0.15$ (prevalence $0.03 \pm 0.01$) and $0.47 \pm 0.1$ (prevalence $0.07 \pm 0.02$) respectively on virtual H&E. This approach represents a promising step towards automating annotation in digital pathology.
Inter-vendor harmonization of Computed Tomography (CT) reconstruction kernels using unpaired image translation
Sep 22, 2023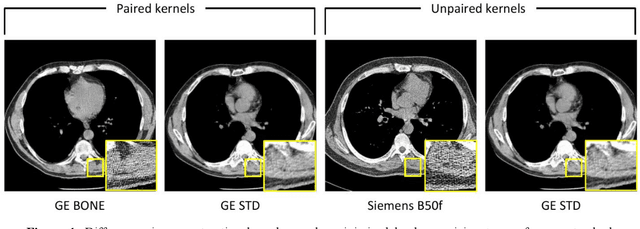
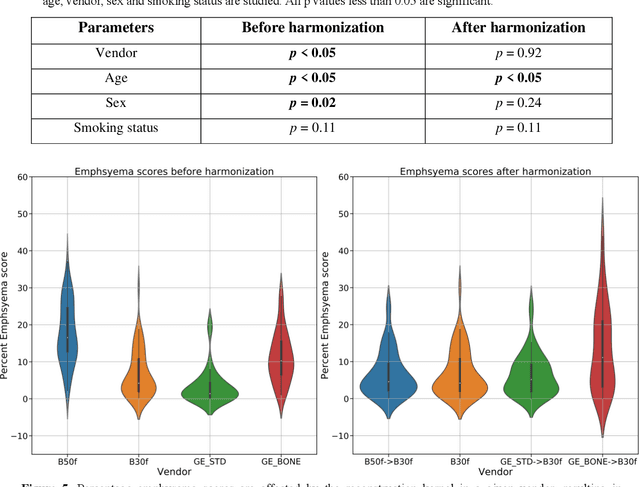
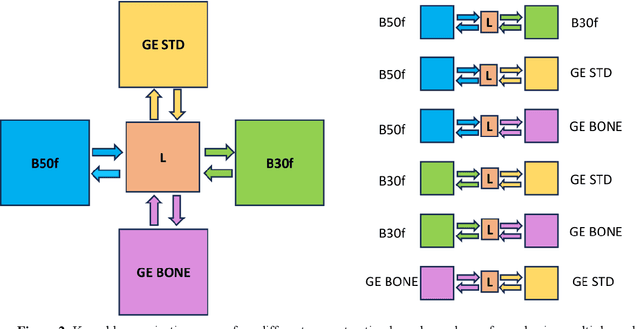
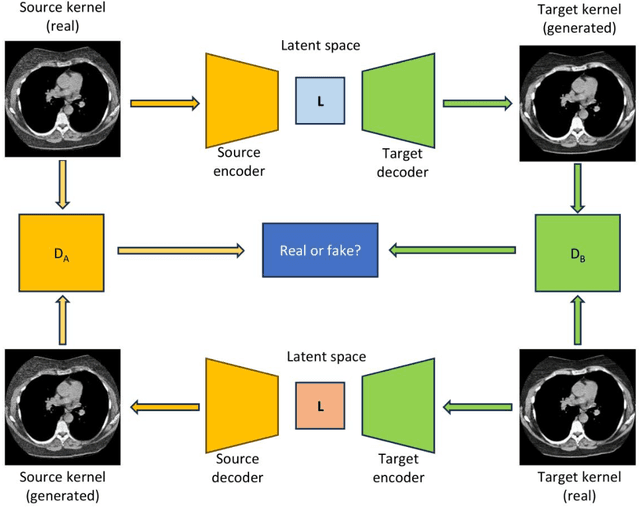
The reconstruction kernel in computed tomography (CT) generation determines the texture of the image. Consistency in reconstruction kernels is important as the underlying CT texture can impact measurements during quantitative image analysis. Harmonization (i.e., kernel conversion) minimizes differences in measurements due to inconsistent reconstruction kernels. Existing methods investigate harmonization of CT scans in single or multiple manufacturers. However, these methods require paired scans of hard and soft reconstruction kernels that are spatially and anatomically aligned. Additionally, a large number of models need to be trained across different kernel pairs within manufacturers. In this study, we adopt an unpaired image translation approach to investigate harmonization between and across reconstruction kernels from different manufacturers by constructing a multipath cycle generative adversarial network (GAN). We use hard and soft reconstruction kernels from the Siemens and GE vendors from the National Lung Screening Trial dataset. We use 50 scans from each reconstruction kernel and train a multipath cycle GAN. To evaluate the effect of harmonization on the reconstruction kernels, we harmonize 50 scans each from Siemens hard kernel, GE soft kernel and GE hard kernel to a reference Siemens soft kernel (B30f) and evaluate percent emphysema. We fit a linear model by considering the age, smoking status, sex and vendor and perform an analysis of variance (ANOVA) on the emphysema scores. Our approach minimizes differences in emphysema measurement and highlights the impact of age, sex, smoking status and vendor on emphysema quantification.
Scaling Up 3D Kernels with Bayesian Frequency Re-parameterization for Medical Image Segmentation
Mar 10, 2023



With the inspiration of vision transformers, the concept of depth-wise convolution revisits to provide a large Effective Receptive Field (ERF) using Large Kernel (LK) sizes for medical image segmentation. However, the segmentation performance might be saturated and even degraded as the kernel sizes scaled up (e.g., $21\times 21\times 21$) in a Convolutional Neural Network (CNN). We hypothesize that convolution with LK sizes is limited to maintain an optimal convergence for locality learning. While Structural Re-parameterization (SR) enhances the local convergence with small kernels in parallel, optimal small kernel branches may hinder the computational efficiency for training. In this work, we propose RepUX-Net, a pure CNN architecture with a simple large kernel block design, which competes favorably with current network state-of-the-art (SOTA) (e.g., 3D UX-Net, SwinUNETR) using 6 challenging public datasets. We derive an equivalency between kernel re-parameterization and the branch-wise variation in kernel convergence. Inspired by the spatial frequency in the human visual system, we extend to vary the kernel convergence into element-wise setting and model the spatial frequency as a Bayesian prior to re-parameterize convolutional weights during training. Specifically, a reciprocal function is leveraged to estimate a frequency-weighted value, which rescales the corresponding kernel element for stochastic gradient descent. From the experimental results, RepUX-Net consistently outperforms 3D SOTA benchmarks with internal validation (FLARE: 0.929 to 0.944), external validation (MSD: 0.901 to 0.932, KiTS: 0.815 to 0.847, LiTS: 0.933 to 0.949, TCIA: 0.736 to 0.779) and transfer learning (AMOS: 0.880 to 0.911) scenarios in Dice Score.
UNesT: Local Spatial Representation Learning with Hierarchical Transformer for Efficient Medical Segmentation
Sep 28, 2022



Transformer-based models, capable of learning better global dependencies, have recently demonstrated exceptional representation learning capabilities in computer vision and medical image analysis. Transformer reformats the image into separate patches and realize global communication via the self-attention mechanism. However, positional information between patches is hard to preserve in such 1D sequences, and loss of it can lead to sub-optimal performance when dealing with large amounts of heterogeneous tissues of various sizes in 3D medical image segmentation. Additionally, current methods are not robust and efficient for heavy-duty medical segmentation tasks such as predicting a large number of tissue classes or modeling globally inter-connected tissues structures. Inspired by the nested hierarchical structures in vision transformer, we proposed a novel 3D medical image segmentation method (UNesT), employing a simplified and faster-converging transformer encoder design that achieves local communication among spatially adjacent patch sequences by aggregating them hierarchically. We extensively validate our method on multiple challenging datasets, consisting anatomies of 133 structures in brain, 14 organs in abdomen, 4 hierarchical components in kidney, and inter-connected kidney tumors). We show that UNesT consistently achieves state-of-the-art performance and evaluate its generalizability and data efficiency. Particularly, the model achieves whole brain segmentation task complete ROI with 133 tissue classes in single network, outperforms prior state-of-the-art method SLANT27 ensembled with 27 network tiles, our model performance increases the mean DSC score of the publicly available Colin and CANDI dataset from 0.7264 to 0.7444 and from 0.6968 to 0.7025, respectively.
Body Composition Assessment with Limited Field-of-view Computed Tomography: A Semantic Image Extension Perspective
Jul 13, 2022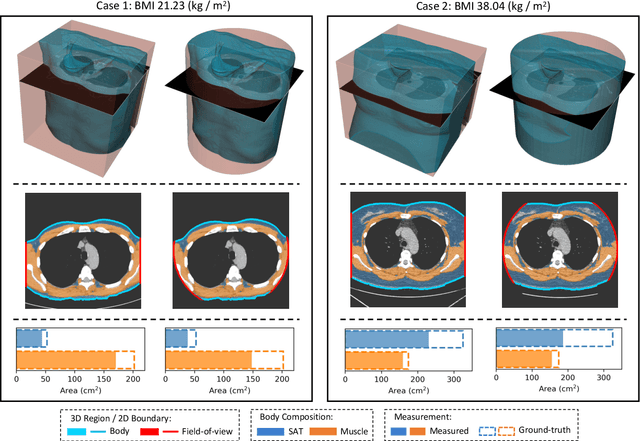
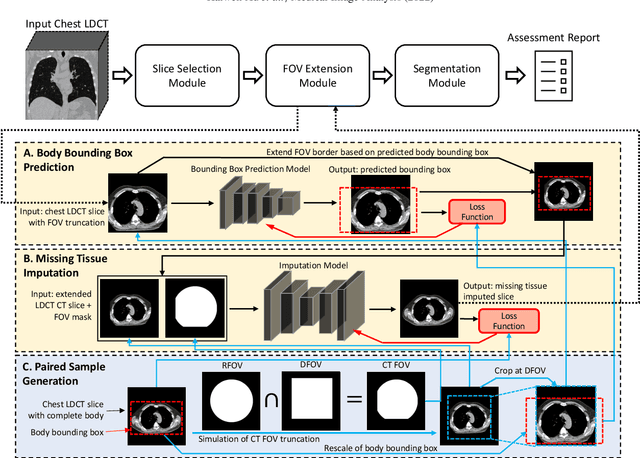
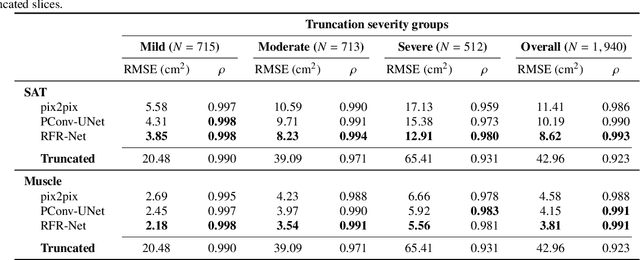
Field-of-view (FOV) tissue truncation beyond the lungs is common in routine lung screening computed tomography (CT). This poses limitations for opportunistic CT- based body composition (BC) assessment as key anatomical structures are missing. Traditionally, extending the FOV of CT is considered as a CT reconstruction problem using limited data. However, this approach relies on the projection domain data which might not be available in application. In this work, we formulate the problem from the semantic image extension perspective which only requires image data as inputs. The proposed two-stage method identifies a new FOV border based on the estimated extent of the complete body and imputes missing tissues in the truncated region. The training samples are simulated using CT slices with complete body in FOV, making the model development self-supervised. We evaluate the validity of the proposed method in automatic BC assessment using lung screening CT with limited FOV. The proposed method effectively restores the missing tissues and reduces BC assessment error introduced by FOV tissue truncation. In the BC assessment for a large-scale lung screening CT dataset, this correction improves both the intra-subject consistency and the correlation with anthropometric approximations. The developed method is available at https://github.com/MASILab/S-EFOV.
A Comparative Study of Confidence Calibration in Deep Learning: From Computer Vision to Medical Imaging
Jun 17, 2022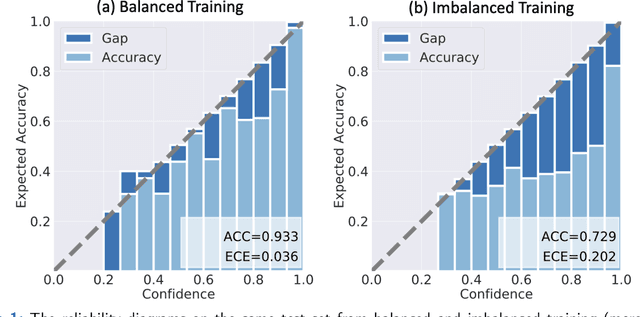
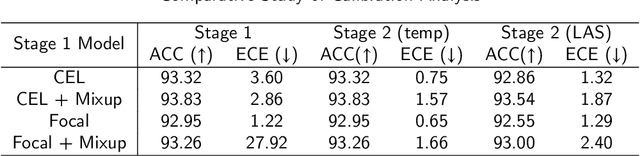
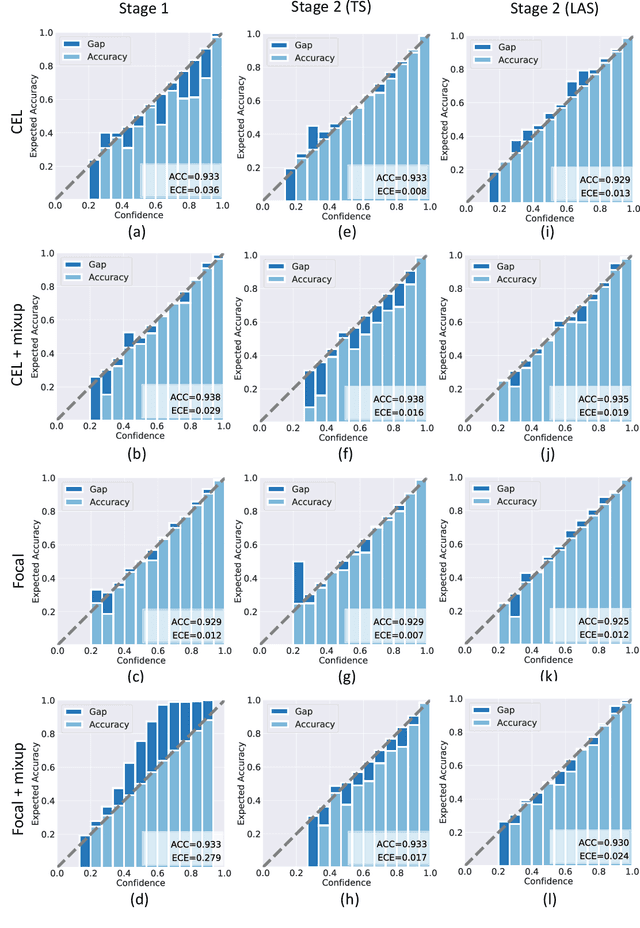
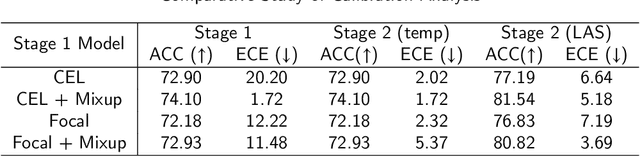
Although deep learning prediction models have been successful in the discrimination of different classes, they can often suffer from poor calibration across challenging domains including healthcare. Moreover, the long-tail distribution poses great challenges in deep learning classification problems including clinical disease prediction. There are approaches proposed recently to calibrate deep prediction in computer vision, but there are no studies found to demonstrate how the representative models work in different challenging contexts. In this paper, we bridge the confidence calibration from computer vision to medical imaging with a comparative study of four high-impact calibration models. Our studies are conducted in different contexts (natural image classification and lung cancer risk estimation) including in balanced vs. imbalanced training sets and in computer vision vs. medical imaging. Our results support key findings: (1) We achieve new conclusions which are not studied under different learning contexts, e.g., combining two calibration models that both mitigate the overconfident prediction can lead to under-confident prediction, and simpler calibration models from the computer vision domain tend to be more generalizable to medical imaging. (2) We highlight the gap between general computer vision tasks and medical imaging prediction, e.g., calibration methods ideal for general computer vision tasks may in fact damage the calibration of medical imaging prediction. (3) We also reinforce previous conclusions in natural image classification settings. We believe that this study has merits to guide readers to choose calibration models and understand gaps between general computer vision and medical imaging domains.
Characterizing Renal Structures with 3D Block Aggregate Transformers
Mar 04, 2022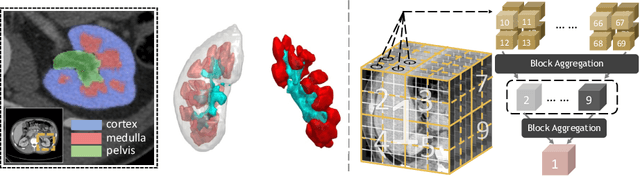
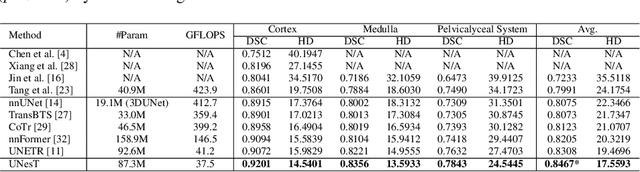
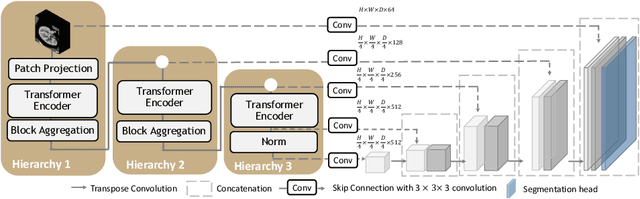

Efficiently quantifying renal structures can provide distinct spatial context and facilitate biomarker discovery for kidney morphology. However, the development and evaluation of the transformer model to segment the renal cortex, medulla, and collecting system remains challenging due to data inefficiency. Inspired by the hierarchical structures in vision transformer, we propose a novel method using a 3D block aggregation transformer for segmenting kidney components on contrast-enhanced CT scans. We construct the first cohort of renal substructures segmentation dataset with 116 subjects under institutional review board (IRB) approval. Our method yields the state-of-the-art performance (Dice of 0.8467) against the baseline approach of 0.8308 with the data-efficient design. The Pearson R achieves 0.9891 between the proposed method and manual standards and indicates the strong correlation and reproducibility for volumetric analysis. We extend the proposed method to the public KiTS dataset, the method leads to improved accuracy compared to transformer-based approaches. We show that the 3D block aggregation transformer can achieve local communication between sequence representations without modifying self-attention, and it can serve as an accurate and efficient quantification tool for characterizing renal structures.
Low Pass Filter for Anti-aliasing in Temporal Action Localization
Apr 23, 2021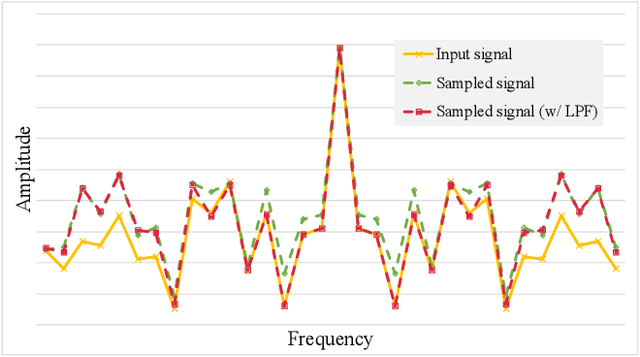

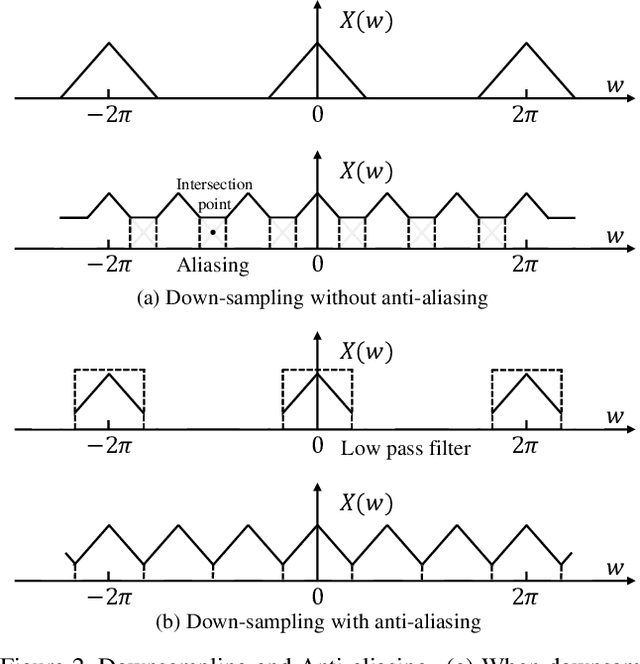
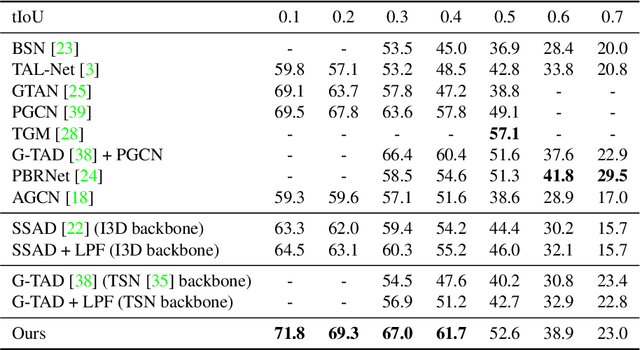
In temporal action localization methods, temporal downsampling operations are widely used to extract proposal features, but they often lead to the aliasing problem, due to lacking consideration of sampling rates. This paper aims to verify the existence of aliasing in TAL methods and investigate utilizing low pass filters to solve this problem by inhibiting the high-frequency band. However, the high-frequency band usually contains large amounts of specific information, which is important for model inference. Therefore, it is necessary to make a tradeoff between anti-aliasing and reserving high-frequency information. To acquire optimal performance, this paper learns different cutoff frequencies for different instances dynamically. This design can be plugged into most existing temporal modeling programs requiring only one additional cutoff frequency parameter. Integrating low pass filters to the downsampling operations significantly improves the detection performance and achieves comparable results on THUMOS'14, ActivityNet~1.3, and Charades datasets. Experiments demonstrate that anti-aliasing with low pass filters in TAL is advantageous and efficient.