 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Comparative Study of Confidence Calibration in Deep Learning: From Computer Vision to Medical Imaging
Jun 17, 2022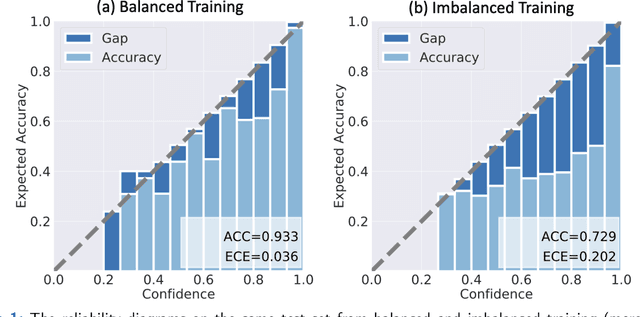
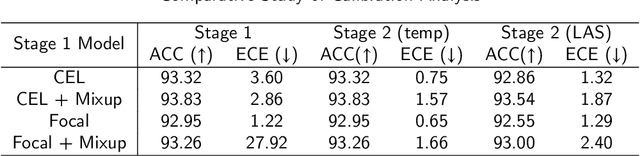
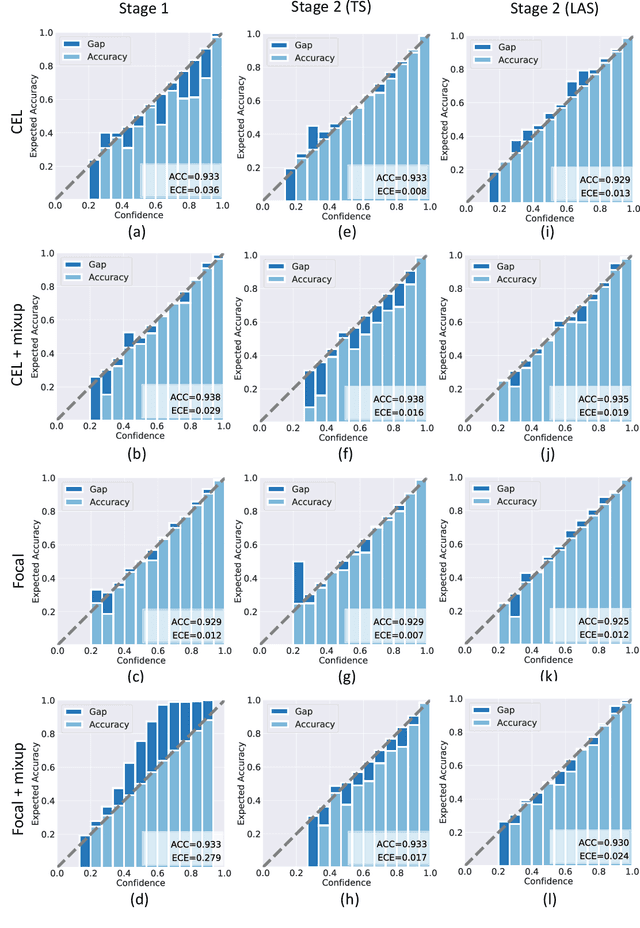
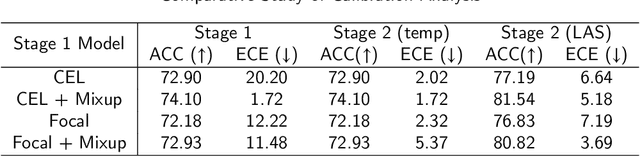
Although deep learning prediction models have been successful in the discrimination of different classes, they can often suffer from poor calibration across challenging domains including healthcare. Moreover, the long-tail distribution poses great challenges in deep learning classification problems including clinical disease prediction. There are approaches proposed recently to calibrate deep prediction in computer vision, but there are no studies found to demonstrate how the representative models work in different challenging contexts. In this paper, we bridge the confidence calibration from computer vision to medical imaging with a comparative study of four high-impact calibration models. Our studies are conducted in different contexts (natural image classification and lung cancer risk estimation) including in balanced vs. imbalanced training sets and in computer vision vs. medical imaging. Our results support key findings: (1) We achieve new conclusions which are not studied under different learning contexts, e.g., combining two calibration models that both mitigate the overconfident prediction can lead to under-confident prediction, and simpler calibration models from the computer vision domain tend to be more generalizable to medical imaging. (2) We highlight the gap between general computer vision tasks and medical imaging prediction, e.g., calibration methods ideal for general computer vision tasks may in fact damage the calibration of medical imaging prediction. (3) We also reinforce previous conclusions in natural image classification settings. We believe that this study has merits to guide readers to choose calibration models and understand gaps between general computer vision and medical imaging domains.