 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting 2D Foundation Models for Scalable 3D Medical Image Classification
Dec 15, 2025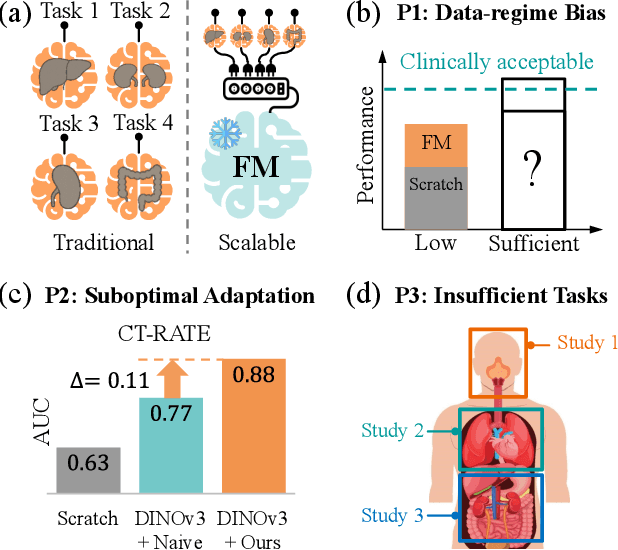
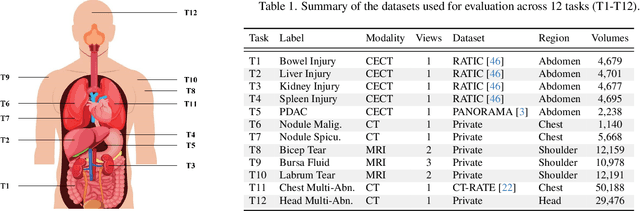
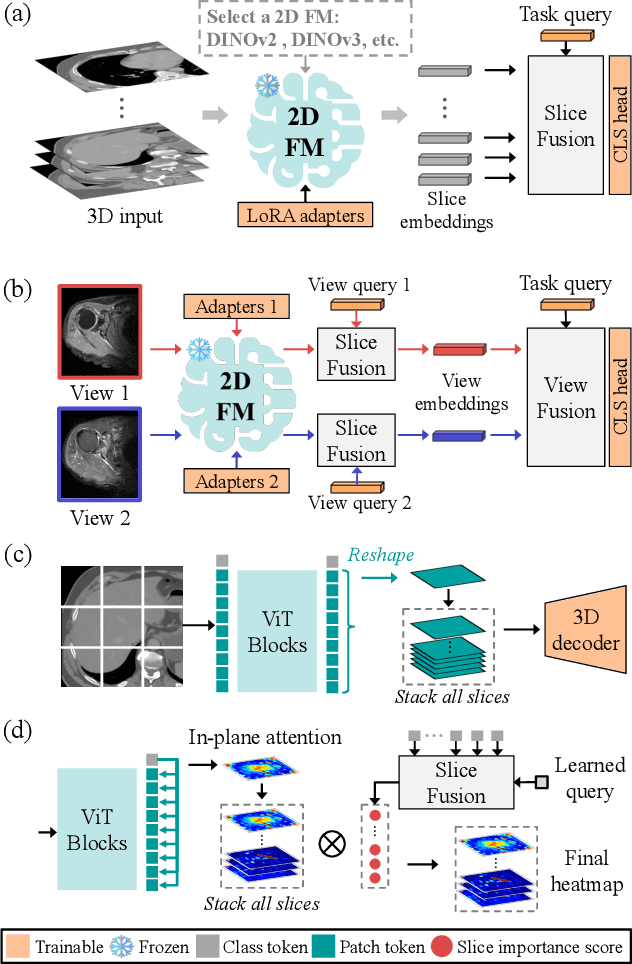
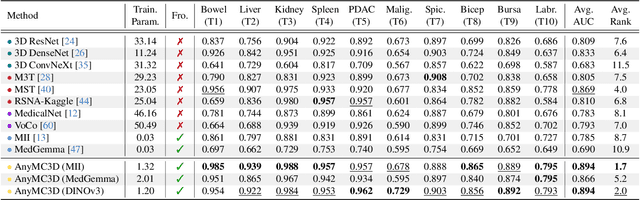
3D medical image classification is essential for modern clinical workflows. Medical foundation models (FMs) have emerged as a promising approach for scaling to new tasks, yet current research suffers from three critical pitfalls: data-regime bias, suboptimal adaptation, and insufficient task coverage. In this paper, we address these pitfalls and introduce AnyMC3D, a scalable 3D classifier adapted from 2D FMs. Our method scales efficiently to new tasks by adding only lightweight plugins (about 1M parameters per task) on top of a single frozen backbone. This versatile framework also supports multi-view inputs, auxiliary pixel-level supervision, and interpretable heatmap generation. We establish a comprehensive benchmark of 12 tasks covering diverse pathologies, anatomies, and modalities, and systematically analyze state-of-the-art 3D classification techniques. Our analysis reveals key insights: (1) effective adaptation is essential to unlock FM potential, (2) general-purpose FMs can match medical-specific FMs if properly adapted, and (3) 2D-based methods surpass 3D architectures for 3D classification. For the first time, we demonstrate the feasibility of achieving state-of-the-art performance across diverse applications using a single scalable framework (including 1st place in the VLM3D challenge), eliminating the need for separate task-specific models.
Demo: Generative AI helps Radiotherapy Planning with User Preference
Dec 08, 2025Radiotherapy planning is a highly complex process that often varies significantly across institutions and individual planners. Most existing deep learning approaches for 3D dose prediction rely on reference plans as ground truth during training, which can inadvertently bias models toward specific planning styles or institutional preferences. In this study, we introduce a novel generative model that predicts 3D dose distributions based solely on user-defined preference flavors. These customizable preferences enable planners to prioritize specific trade-offs between organs-at-risk (OARs) and planning target volumes (PTVs), offering greater flexibility and personalization. Designed for seamless integration with clinical treatment planning systems, our approach assists users in generating high-quality plans efficiently. Comparative evaluations demonstrate that our method can surpasses the Varian RapidPlan model in both adaptability and plan quality in some scenarios.
AI-assisted Early Detection of Pancreatic Ductal Adenocarcinoma on Contrast-enhanced CT
Mar 13, 2025



Pancreatic ductal adenocarcinoma (PDAC) is one of the most common and aggressive types of pancreatic cancer. However, due to the lack of early and disease-specific symptoms, most patients with PDAC are diagnosed at an advanced disease stage. Consequently, early PDAC detection is crucial for improving patients' quality of life and expanding treatment options. In this work, we develop a coarse-to-fine approach to detect PDAC on contrast-enhanced CT scans. First, we localize and crop the region of interest from the low-resolution images, and then segment the PDAC-related structures at a finer scale. Additionally, we introduce two strategies to further boost detection performance: (1) a data-splitting strategy for model ensembling, and (2) a customized post-processing function. We participated in the PANORAMA challenge and ranked 1st place for PDAC detection with an AUROC of 0.9263 and an AP of 0.7243. Our code and models are publicly available at https://github.com/han-liu/PDAC_detection.
A Beam's Eye View to Fluence Maps 3D Network for Ultra Fast VMAT Radiotherapy Planning
Feb 05, 2025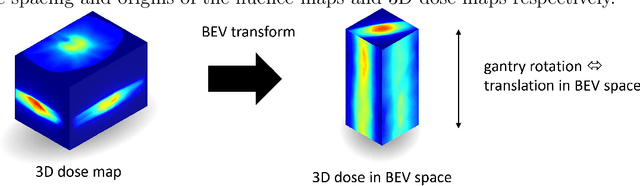
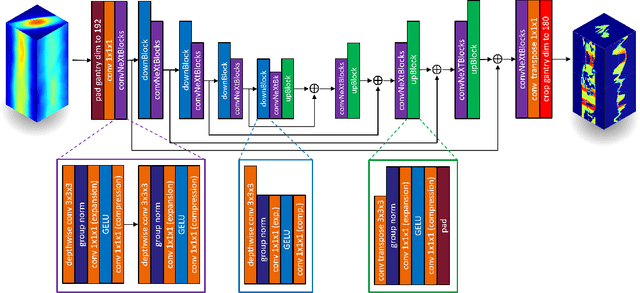

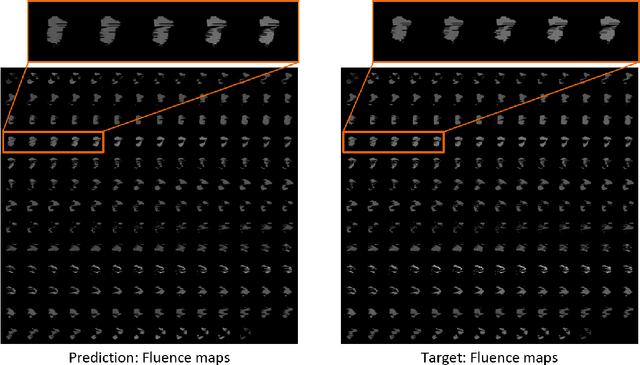
Volumetric Modulated Arc Therapy (VMAT) revolutionizes cancer treatment by precisely delivering radiation while sparing healthy tissues. Fluence maps generation, crucial in VMAT planning, traditionally involves complex and iterative, and thus time consuming processes. These fluence maps are subsequently leveraged for leaf-sequence. The deep-learning approach presented in this article aims to expedite this by directly predicting fluence maps from patient data. We developed a 3D network which we trained in a supervised way using a combination of L1 and L2 losses, and RT plans generated by Eclipse and from the REQUITE dataset, taking the RT dose map as input and the fluence maps computed from the corresponding RT plans as target. Our network predicts jointly the 180 fluence maps corresponding to the 180 control points (CP) of single arc VMAT plans. In order to help the network, we pre-process the input dose by computing the projections of the 3D dose map to the beam's eye view (BEV) of the 180 CPs, in the same coordinate system as the fluence maps. We generated over 2000 VMAT plans using Eclipse to scale up the dataset size. Additionally, we evaluated various network architectures and analyzed the impact of increasing the dataset size. We are measuring the performance in the 2D fluence maps domain using image metrics (PSNR, SSIM), as well as in the 3D dose domain using the dose-volume histogram (DVH) on a validation dataset. The network inference, which does not include the data loading and processing, is less than 20ms. Using our proposed 3D network architecture as well as increasing the dataset size using Eclipse improved the fluence map reconstruction performance by approximately 8 dB in PSNR compared to a U-Net architecture trained on the original REQUITE dataset. The resulting DVHs are very close to the one of the input target dose.
Automating High Quality RT Planning at Scale
Jan 21, 2025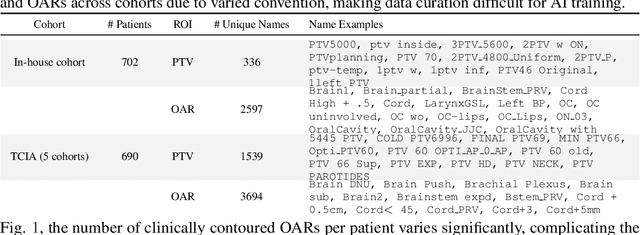
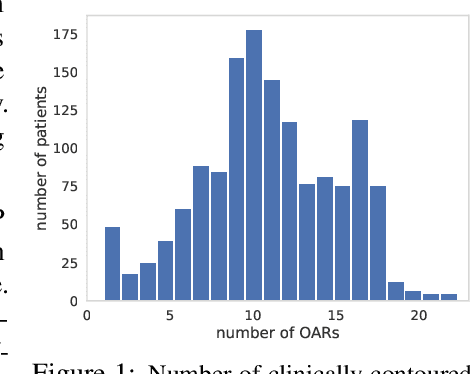
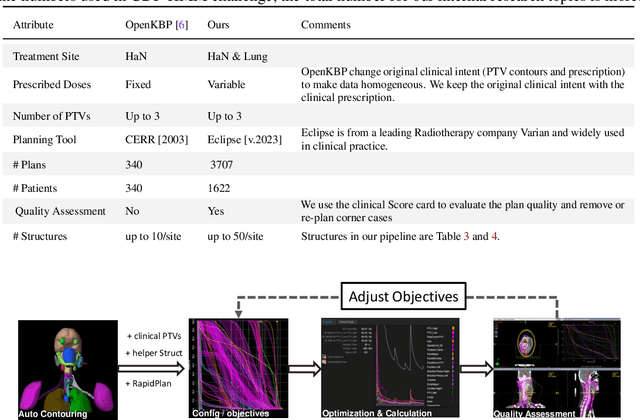
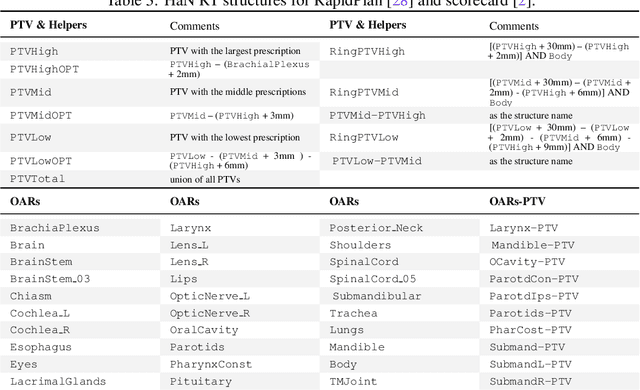
Radiotherapy (RT) planning is complex, subjective, and time-intensive. Advances in artificial intelligence (AI) promise to improve its precision, efficiency, and consistency, but progress is often limited by the scarcity of large, standardized datasets. To address this, we introduce the Automated Iterative RT Planning (AIRTP) system, a scalable solution for generating high-quality treatment plans. This scalable solution is designed to generate substantial volumes of consistently high-quality treatment plans, overcoming a key obstacle in the advancement of AI-driven RT planning. Our AIRTP pipeline adheres to clinical guidelines and automates essential steps, including organ-at-risk (OAR) contouring, helper structure creation, beam setup, optimization, and plan quality improvement, using AI integrated with RT planning software like Eclipse of Varian. Furthermore, a novel approach for determining optimization parameters to reproduce 3D dose distributions, i.e. a method to convert dose predictions to deliverable treatment plans constrained by machine limitations. A comparative analysis of plan quality reveals that our automated pipeline produces treatment plans of quality comparable to those generated manually, which traditionally require several hours of labor per plan. Committed to public research, the first data release of our AIRTP pipeline includes nine cohorts covering head-and-neck and lung cancer sites to support an AAPM 2025 challenge. This data set features more than 10 times the number of plans compared to the largest existing well-curated public data set to our best knowledge. Repo:{https://github.com/RiqiangGao/GDP-HMM_AAPMChallenge}
Multi-Agent Reinforcement Learning Meets Leaf Sequencing in Radiotherapy
Jun 03, 2024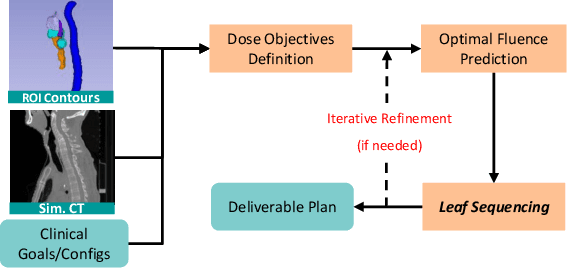
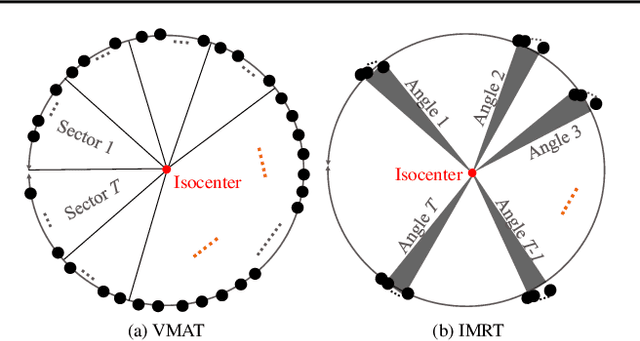

In contemporary radiotherapy planning (RTP), a key module leaf sequencing is predominantly addressed by optimization-based approaches. In this paper, we propose a novel deep reinforcement learning (DRL) model termed as Reinforced Leaf Sequencer (RLS) in a multi-agent framework for leaf sequencing. The RLS model offers improvements to time-consuming iterative optimization steps via large-scale training and can control movement patterns through the design of reward mechanisms. We have conducted experiments on four datasets with four metrics and compared our model with a leading optimization sequencer. Our findings reveal that the proposed RLS model can achieve reduced fluence reconstruction errors, and potential faster convergence when integrated in an optimization planner. Additionally, RLS has shown promising results in a full artificial intelligence RTP pipeline. We hope this pioneer multi-agent RL leaf sequencer can foster future research on machine learning for RTP.
Deep conditional generative models for longitudinal single-slice abdominal computed tomography harmonization
Sep 17, 2023Two-dimensional single-slice abdominal computed tomography (CT) provides a detailed tissue map with high resolution allowing quantitative characterization of relationships between health conditions and aging. However, longitudinal analysis of body composition changes using these scans is difficult due to positional variation between slices acquired in different years, which leading to different organs/tissues captured. To address this issue, we propose C-SliceGen, which takes an arbitrary axial slice in the abdominal region as a condition and generates a pre-defined vertebral level slice by estimating structural changes in the latent space. Our experiments on 2608 volumetric CT data from two in-house datasets and 50 subjects from the 2015 Multi-Atlas Abdomen Labeling Challenge dataset (BTCV) Challenge demonstrate that our model can generate high-quality images that are realistic and similar. We further evaluate our method's capability to harmonize longitudinal positional variation on 1033 subjects from the Baltimore Longitudinal Study of Aging (BLSA) dataset, which contains longitudinal single abdominal slices, and confirmed that our method can harmonize the slice positional variance in terms of visceral fat area. This approach provides a promising direction for mapping slices from different vertebral levels to a target slice and reducing positional variance for single-slice longitudinal analysis. The source code is available at: https://github.com/MASILab/C-SliceGen.
COSST: Multi-organ Segmentation with Partially Labeled Datasets Using Comprehensive Supervisions and Self-training
Apr 28, 2023Deep learning models have demonstrated remarkable success in multi-organ segmentation but typically require large-scale datasets with all organs of interest annotated. However, medical image datasets are often low in sample size and only partially labeled, i.e., only a subset of organs are annotated. Therefore, it is crucial to investigate how to learn a unified model on the available partially labeled datasets to leverage their synergistic potential. In this paper, we empirically and systematically study the partial-label segmentation with in-depth analyses on the existing approaches and identify three distinct types of supervision signals, including two signals derived from ground truth and one from pseudo label. We propose a novel training framework termed COSST, which effectively and efficiently integrates comprehensive supervision signals with self-training. Concretely, we first train an initial unified model using two ground truth-based signals and then iteratively incorporate the pseudo label signal to the initial model using self-training. To mitigate performance degradation caused by unreliable pseudo labels, we assess the reliability of pseudo labels via outlier detection in latent space and exclude the most unreliable pseudo labels from each self-training iteration. Extensive experiments are conducted on six CT datasets for three partial-label segmentation tasks. Experimental results show that our proposed COSST achieves significant improvement over the baseline method, i.e., individual networks trained on each partially labeled dataset. Compared to the state-of-the-art partial-label segmentation methods, COSST demonstrates consistent superior performance on various segmentation tasks and with different training data size.
Longitudinal Multimodal Transformer Integrating Imaging and Latent Clinical Signatures From Routine EHRs for Pulmonary Nodule Classification
Apr 10, 2023



The accuracy of predictive models for solitary pulmonary nodule (SPN) diagnosis can be greatly increased by incorporating repeat imaging and medical context, such as electronic health records (EHRs). However, clinically routine modalities such as imaging and diagnostic codes can be asynchronous and irregularly sampled over different time scales which are obstacles to longitudinal multimodal learning. In this work, we propose a transformer-based multimodal strategy to integrate repeat imaging with longitudinal clinical signatures from routinely collected EHRs for SPN classification. We perform unsupervised disentanglement of latent clinical signatures and leverage time-distance scaled self-attention to jointly learn from clinical signatures expressions and chest computed tomography (CT) scans. Our classifier is pretrained on 2,668 scans from a public dataset and 1,149 subjects with longitudinal chest CTs, billing codes, medications, and laboratory tests from EHRs of our home institution. Evaluation on 227 subjects with challenging SPNs revealed a significant AUC improvement over a longitudinal multimodal baseline (0.824 vs 0.752 AUC), as well as improvements over a single cross-section multimodal scenario (0.809 AUC) and a longitudinal imaging-only scenario (0.741 AUC). This work demonstrates significant advantages with a novel approach for co-learning longitudinal imaging and non-imaging phenotypes with transformers.
Reducing Positional Variance in Cross-sectional Abdominal CT Slices with Deep Conditional Generative Models
Sep 28, 20222D low-dose single-slice abdominal computed tomography (CT) slice enables direct measurements of body composition, which are critical to quantitatively characterizing health relationships on aging. However, longitudinal analysis of body composition changes using 2D abdominal slices is challenging due to positional variance between longitudinal slices acquired in different years. To reduce the positional variance, we extend the conditional generative models to our C-SliceGen that takes an arbitrary axial slice in the abdominal region as the condition and generates a defined vertebral level slice by estimating the structural changes in the latent space. Experiments on 1170 subjects from an in-house dataset and 50 subjects from BTCV MICCAI Challenge 2015 show that our model can generate high quality images in terms of realism and similarity. External experiments on 20 subjects from the Baltimore Longitudinal Study of Aging (BLSA) dataset that contains longitudinal single abdominal slices validate that our method can harmonize the slice positional variance in terms of muscle and visceral fat area. Our approach provides a promising direction of mapping slices from different vertebral levels to a target slice to reduce positional variance for single slice longitudinal analysis. The source code is available at: https://github.com/MASILab/C-SliceGen.
* 11 pages, 4 figures