 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-supervised learning of imaging and clinical signatures using a multimodal joint-embedding predictive architecture
Sep 18, 2025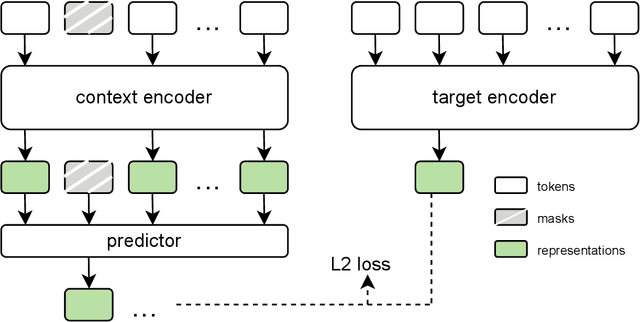

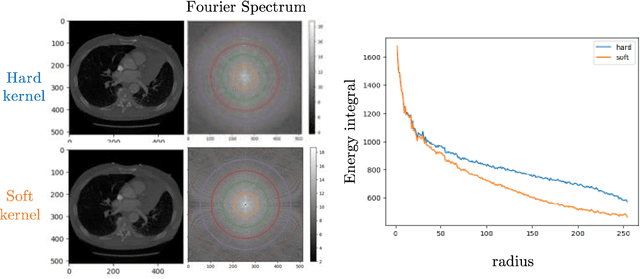
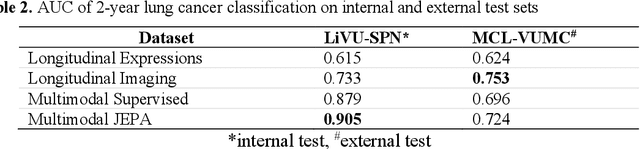
The development of multimodal models for pulmonary nodule diagnosis is limited by the scarcity of labeled data and the tendency for these models to overfit on the training distribution. In this work, we leverage self-supervised learning from longitudinal and multimodal archives to address these challenges. We curate an unlabeled set of patients with CT scans and linked electronic health records from our home institution to power joint embedding predictive architecture (JEPA) pretraining. After supervised finetuning, we show that our approach outperforms an unregularized multimodal model and imaging-only model in an internal cohort (ours: 0.91, multimodal: 0.88, imaging-only: 0.73 AUC), but underperforms in an external cohort (ours: 0.72, imaging-only: 0.75 AUC). We develop a synthetic environment that characterizes the context in which JEPA may underperform. This work innovates an approach that leverages unlabeled multimodal medical archives to improve predictive models and demonstrates its advantages and limitations in pulmonary nodule diagnosis.
Cryptogenic stroke and migraine: using probabilistic independence and machine learning to uncover latent sources of disease from the electronic health record
Apr 22, 2025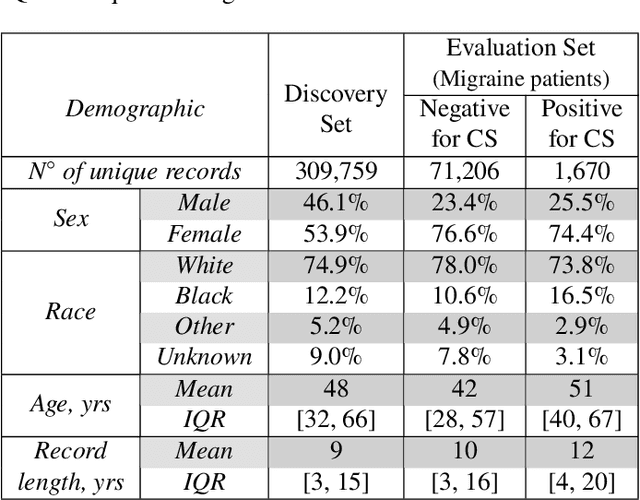
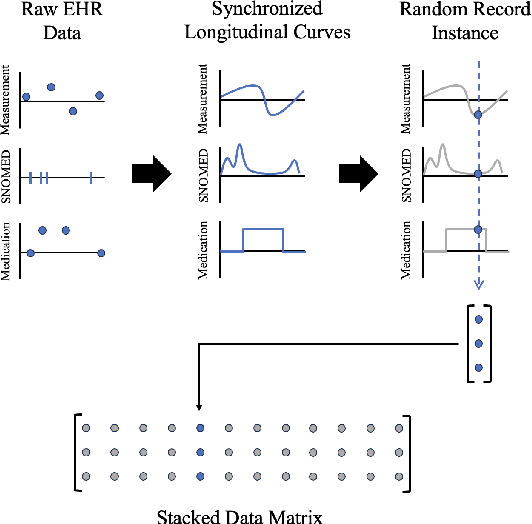
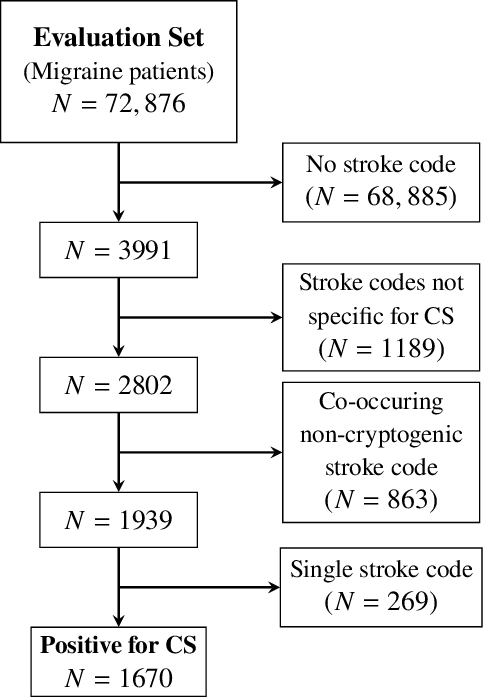
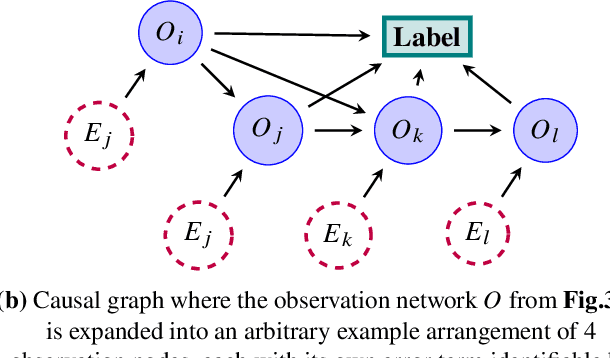
Migraine is a common but complex neurological disorder that doubles the lifetime risk of cryptogenic stroke (CS). However, this relationship remains poorly characterized, and few clinical guidelines exist to reduce this associated risk. We therefore propose a data-driven approach to extract probabilistically-independent sources from electronic health record (EHR) data and create a 10-year risk-predictive model for CS in migraine patients. These sources represent external latent variables acting on the causal graph constructed from the EHR data and approximate root causes of CS in our population. A random forest model trained on patient expressions of these sources demonstrated good accuracy (ROC 0.771) and identified the top 10 most predictive sources of CS in migraine patients. These sources revealed that pharmacologic interventions were the most important factor in minimizing CS risk in our population and identified a factor related to allergic rhinitis as a potential causative source of CS in migraine patients.
A data-driven approach to discover and quantify systemic lupus erythematosus etiological heterogeneity from electronic health records
Jan 13, 2025Systemic lupus erythematosus (SLE) is a complex heterogeneous disease with many manifestational facets. We propose a data-driven approach to discover probabilistic independent sources from multimodal imperfect EHR data. These sources represent exogenous variables in the data generation process causal graph that estimate latent root causes of the presence of SLE in the health record. We objectively evaluated the sources against the original variables from which they were discovered by training supervised models to discriminate SLE from negative health records using a reduced set of labelled instances. We found 19 predictive sources with high clinical validity and whose EHR signatures define independent factors of SLE heterogeneity. Using the sources as input patient data representation enables models to provide with rich explanations that better capture the clinical reasons why a particular record is (not) an SLE case. Providers may be willing to trade patient-level interpretability for discrimination especially in challenging cases.
Unsupervised Discovery of Clinical Disease Signatures Using Probabilistic Independence
Feb 08, 2024



Insufficiently precise diagnosis of clinical disease is likely responsible for many treatment failures, even for common conditions and treatments. With a large enough dataset, it may be possible to use unsupervised machine learning to define clinical disease patterns more precisely. We present an approach to learning these patterns by using probabilistic independence to disentangle the imprint on the medical record of causal latent sources of disease. We inferred a broad set of 2000 clinical signatures of latent sources from 9195 variables in 269,099 Electronic Health Records. The learned signatures produced better discrimination than the original variables in a lung cancer prediction task unknown to the inference algorithm, predicting 3-year malignancy in patients with no history of cancer before a solitary lung nodule was discovered. More importantly, the signatures' greater explanatory power identified pre-nodule signatures of apparently undiagnosed cancer in many of those patients.
Longitudinal Multimodal Transformer Integrating Imaging and Latent Clinical Signatures From Routine EHRs for Pulmonary Nodule Classification
Apr 10, 2023



The accuracy of predictive models for solitary pulmonary nodule (SPN) diagnosis can be greatly increased by incorporating repeat imaging and medical context, such as electronic health records (EHRs). However, clinically routine modalities such as imaging and diagnostic codes can be asynchronous and irregularly sampled over different time scales which are obstacles to longitudinal multimodal learning. In this work, we propose a transformer-based multimodal strategy to integrate repeat imaging with longitudinal clinical signatures from routinely collected EHRs for SPN classification. We perform unsupervised disentanglement of latent clinical signatures and leverage time-distance scaled self-attention to jointly learn from clinical signatures expressions and chest computed tomography (CT) scans. Our classifier is pretrained on 2,668 scans from a public dataset and 1,149 subjects with longitudinal chest CTs, billing codes, medications, and laboratory tests from EHRs of our home institution. Evaluation on 227 subjects with challenging SPNs revealed a significant AUC improvement over a longitudinal multimodal baseline (0.824 vs 0.752 AUC), as well as improvements over a single cross-section multimodal scenario (0.809 AUC) and a longitudinal imaging-only scenario (0.741 AUC). This work demonstrates significant advantages with a novel approach for co-learning longitudinal imaging and non-imaging phenotypes with transformers.