 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDECADE: A Temporally-Consistent Unsupervised Diffusion Model for Enhanced Rb-82 Dynamic Cardiac PET Image Denoising
Mar 08, 2026Rb-82 dynamic cardiac PET imaging is widely used for the clinical diagnosis of coronary artery disease (CAD), but its short half-life results in high noise levels that degrade dynamic frame quality and parametric imaging. The lack of paired clean-noisy training data, rapid tracer kinetics, and frame-dependent noise variations further limit the effectiveness of existing deep learning denoising methods. We propose DECADE (A Temporally-Consistent Unsupervised Diffusion model for Enhanced Rb-82 CArdiac PET DEnoising), an unsupervised diffusion framework that generalizes across early- to late-phase dynamic frames. DECADE incorporates temporal consistency during both training and iterative sampling, using noisy frames as guidance to preserve quantitative accuracy. The method was trained and evaluated on datasets acquired from Siemens Vision 450 and Siemens Biograph Vision Quadra scanners. On the Vision 450 dataset, DECADE consistently produced high-quality dynamic and parametric images with reduced noise while preserving myocardial blood flow (MBF) and myocardial flow reserve (MFR). On the Quadra dataset, using 15%-count images as input and full-count images as reference, DECADE outperformed UNet-based and other diffusion models in image quality and K1/MBF quantification. The proposed framework enables effective unsupervised denoising of Rb-82 dynamic cardiac PET without paired training data, supporting clearer visualization while maintaining quantitative integrity.
Fed-NDIF: A Noise-Embedded Federated Diffusion Model For Low-Count Whole-Body PET Denoising
Mar 20, 2025



Low-count positron emission tomography (LCPET) imaging can reduce patients' exposure to radiation but often suffers from increased image noise and reduced lesion detectability, necessitating effective denoising techniques. Diffusion models have shown promise in LCPET denoising for recovering degraded image quality. However, training such models requires large and diverse datasets, which are challenging to obtain in the medical domain. To address data scarcity and privacy concerns, we combine diffusion models with federated learning -- a decentralized training approach where models are trained individually at different sites, and their parameters are aggregated on a central server over multiple iterations. The variation in scanner types and image noise levels within and across institutions poses additional challenges for federated learning in LCPET denoising. In this study, we propose a novel noise-embedded federated learning diffusion model (Fed-NDIF) to address these challenges, leveraging a multicenter dataset and varying count levels. Our approach incorporates liver normalized standard deviation (NSTD) noise embedding into a 2.5D diffusion model and utilizes the Federated Averaging (FedAvg) algorithm to aggregate locally trained models into a global model, which is subsequently fine-tuned on local datasets to optimize performance and obtain personalized models. Extensive validation on datasets from the University of Bern, Ruijin Hospital in Shanghai, and Yale-New Haven Hospital demonstrates the superior performance of our method in enhancing image quality and improving lesion quantification. The Fed-NDIF model shows significant improvements in PSNR, SSIM, and NMSE of the entire 3D volume, as well as enhanced lesion detectability and quantification, compared to local diffusion models and federated UNet-based models.
2.5D Multi-view Averaging Diffusion Model for 3D Medical Image Translation: Application to Low-count PET Reconstruction with CT-less Attenuation Correction
Jun 12, 2024


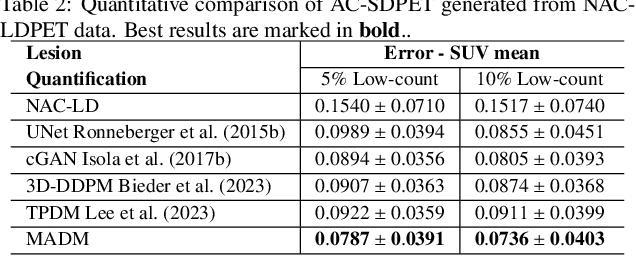
Positron Emission Tomography (PET) is an important clinical imaging tool but inevitably introduces radiation hazards to patients and healthcare providers. Reducing the tracer injection dose and eliminating the CT acquisition for attenuation correction can reduce the overall radiation dose, but often results in PET with high noise and bias. Thus, it is desirable to develop 3D methods to translate the non-attenuation-corrected low-dose PET (NAC-LDPET) into attenuation-corrected standard-dose PET (AC-SDPET). Recently, diffusion models have emerged as a new state-of-the-art deep learning method for image-to-image translation, better than traditional CNN-based methods. However, due to the high computation cost and memory burden, it is largely limited to 2D applications. To address these challenges, we developed a novel 2.5D Multi-view Averaging Diffusion Model (MADM) for 3D image-to-image translation with application on NAC-LDPET to AC-SDPET translation. Specifically, MADM employs separate diffusion models for axial, coronal, and sagittal views, whose outputs are averaged in each sampling step to ensure the 3D generation quality from multiple views. To accelerate the 3D sampling process, we also proposed a strategy to use the CNN-based 3D generation as a prior for the diffusion model. Our experimental results on human patient studies suggested that MADM can generate high-quality 3D translation images, outperforming previous CNN-based and Diffusion-based baseline methods.
POUR-Net: A Population-Prior-Aided Over-Under-Representation Network for Low-Count PET Attenuation Map Generation
Jan 25, 2024



Low-dose PET offers a valuable means of minimizing radiation exposure in PET imaging. However, the prevalent practice of employing additional CT scans for generating attenuation maps (u-map) for PET attenuation correction significantly elevates radiation doses. To address this concern and further mitigate radiation exposure in low-dose PET exams, we propose POUR-Net - an innovative population-prior-aided over-under-representation network that aims for high-quality attenuation map generation from low-dose PET. First, POUR-Net incorporates an over-under-representation network (OUR-Net) to facilitate efficient feature extraction, encompassing both low-resolution abstracted and fine-detail features, for assisting deep generation on the full-resolution level. Second, complementing OUR-Net, a population prior generation machine (PPGM) utilizing a comprehensive CT-derived u-map dataset, provides additional prior information to aid OUR-Net generation. The integration of OUR-Net and PPGM within a cascade framework enables iterative refinement of $\mu$-map generation, resulting in the production of high-quality $\mu$-maps. Experimental results underscore the effectiveness of POUR-Net, showing it as a promising solution for accurate CT-free low-count PET attenuation correction, which also surpasses the performance of previous baseline methods.
Multi-Contrast Computed Tomography Atlas of Healthy Pancreas
Jun 02, 2023With the substantial diversity in population demographics, such as differences in age and body composition, the volumetric morphology of pancreas varies greatly, resulting in distinctive variations in shape and appearance. Such variations increase the difficulty at generalizing population-wide pancreas features. A volumetric spatial reference is needed to adapt the morphological variability for organ-specific analysis. Here, we proposed a high-resolution computed tomography (CT) atlas framework specifically optimized for the pancreas organ across multi-contrast CT. We introduce a deep learning-based pre-processing technique to extract the abdominal region of interests (ROIs) and leverage a hierarchical registration pipeline to align the pancreas anatomy across populations. Briefly, DEEDs affine and non-rigid registration are performed to transfer patient abdominal volumes to a fixed high-resolution atlas template. To generate and evaluate the pancreas atlas template, multi-contrast modality CT scans of 443 subjects (without reported history of pancreatic disease, age: 15-50 years old) are processed. Comparing with different registration state-of-the-art tools, the combination of DEEDs affine and non-rigid registration achieves the best performance for the pancreas label transfer across all contrast phases. We further perform external evaluation with another research cohort of 100 de-identified portal venous scans with 13 organs labeled, having the best label transfer performance of 0.504 Dice score in unsupervised setting. The qualitative representation (e.g., average mapping) of each phase creates a clear boundary of pancreas and its distinctive contrast appearance. The deformation surface renderings across scales (e.g., small to large volume) further illustrate the generalizability of the proposed atlas template.
UNesT: Local Spatial Representation Learning with Hierarchical Transformer for Efficient Medical Segmentation
Sep 28, 2022



Transformer-based models, capable of learning better global dependencies, have recently demonstrated exceptional representation learning capabilities in computer vision and medical image analysis. Transformer reformats the image into separate patches and realize global communication via the self-attention mechanism. However, positional information between patches is hard to preserve in such 1D sequences, and loss of it can lead to sub-optimal performance when dealing with large amounts of heterogeneous tissues of various sizes in 3D medical image segmentation. Additionally, current methods are not robust and efficient for heavy-duty medical segmentation tasks such as predicting a large number of tissue classes or modeling globally inter-connected tissues structures. Inspired by the nested hierarchical structures in vision transformer, we proposed a novel 3D medical image segmentation method (UNesT), employing a simplified and faster-converging transformer encoder design that achieves local communication among spatially adjacent patch sequences by aggregating them hierarchically. We extensively validate our method on multiple challenging datasets, consisting anatomies of 133 structures in brain, 14 organs in abdomen, 4 hierarchical components in kidney, and inter-connected kidney tumors). We show that UNesT consistently achieves state-of-the-art performance and evaluate its generalizability and data efficiency. Particularly, the model achieves whole brain segmentation task complete ROI with 133 tissue classes in single network, outperforms prior state-of-the-art method SLANT27 ensembled with 27 network tiles, our model performance increases the mean DSC score of the publicly available Colin and CANDI dataset from 0.7264 to 0.7444 and from 0.6968 to 0.7025, respectively.
Characterizing Renal Structures with 3D Block Aggregate Transformers
Mar 04, 2022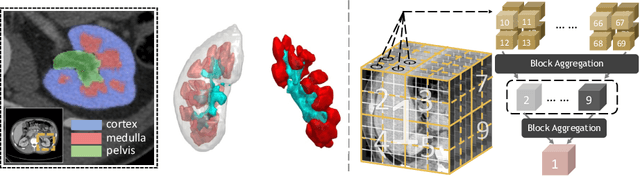
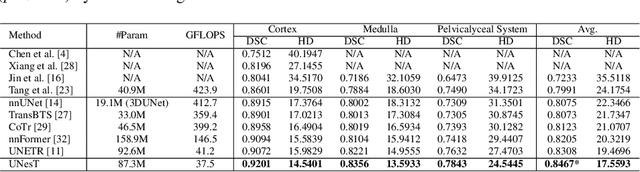
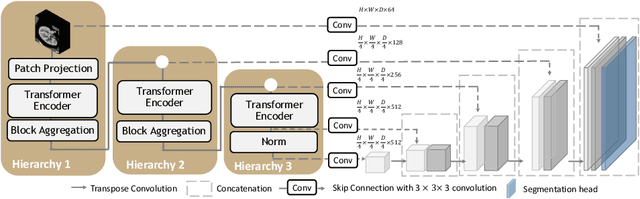

Efficiently quantifying renal structures can provide distinct spatial context and facilitate biomarker discovery for kidney morphology. However, the development and evaluation of the transformer model to segment the renal cortex, medulla, and collecting system remains challenging due to data inefficiency. Inspired by the hierarchical structures in vision transformer, we propose a novel method using a 3D block aggregation transformer for segmenting kidney components on contrast-enhanced CT scans. We construct the first cohort of renal substructures segmentation dataset with 116 subjects under institutional review board (IRB) approval. Our method yields the state-of-the-art performance (Dice of 0.8467) against the baseline approach of 0.8308 with the data-efficient design. The Pearson R achieves 0.9891 between the proposed method and manual standards and indicates the strong correlation and reproducibility for volumetric analysis. We extend the proposed method to the public KiTS dataset, the method leads to improved accuracy compared to transformer-based approaches. We show that the 3D block aggregation transformer can achieve local communication between sequence representations without modifying self-attention, and it can serve as an accurate and efficient quantification tool for characterizing renal structures.