 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaFuse: Adaptive Multimodal Fusion for Lung Cancer Risk Prediction via Reinforcement Learning
Jan 30, 2026Multimodal fusion has emerged as a promising paradigm for disease diagnosis and prognosis, integrating complementary information from heterogeneous data sources such as medical images, clinical records, and radiology reports. However, existing fusion methods process all available modalities through the network, either treating them equally or learning to assign different contribution weights, leaving a fundamental question unaddressed: for a given patient, should certain modalities be used at all? We present AdaFuse, an adaptive multimodal fusion framework that leverages reinforcement learning (RL) to learn patient-specific modality selection and fusion strategies for lung cancer risk prediction. AdaFuse formulates multimodal fusion as a sequential decision process, where the policy network iteratively decides whether to incorporate an additional modality or proceed to prediction based on the information already acquired. This sequential formulation enables the model to condition each selection on previously observed modalities and terminate early when sufficient information is available, rather than committing to a fixed subset upfront. We evaluate AdaFuse on the National Lung Screening Trial (NLST) dataset. Experimental results demonstrate that AdaFuse achieves the highest AUC (0.762) compared to the best single-modality baseline (0.732), the best fixed fusion strategy (0.759), and adaptive baselines including DynMM (0.754) and MoE (0.742), while using fewer FLOPs than all triple-modality methods. Our work demonstrates the potential of reinforcement learning for personalized multimodal fusion in medical imaging, representing a shift from uniform fusion strategies toward adaptive diagnostic pipelines that learn when to consult additional modalities and when existing information suffices for accurate prediction.
Self-supervised learning of imaging and clinical signatures using a multimodal joint-embedding predictive architecture
Sep 18, 2025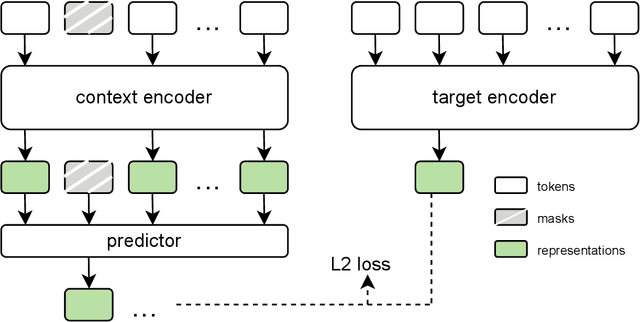

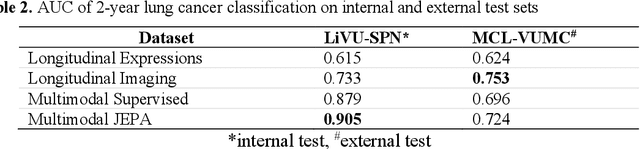
The development of multimodal models for pulmonary nodule diagnosis is limited by the scarcity of labeled data and the tendency for these models to overfit on the training distribution. In this work, we leverage self-supervised learning from longitudinal and multimodal archives to address these challenges. We curate an unlabeled set of patients with CT scans and linked electronic health records from our home institution to power joint embedding predictive architecture (JEPA) pretraining. After supervised finetuning, we show that our approach outperforms an unregularized multimodal model and imaging-only model in an internal cohort (ours: 0.91, multimodal: 0.88, imaging-only: 0.73 AUC), but underperforms in an external cohort (ours: 0.72, imaging-only: 0.75 AUC). We develop a synthetic environment that characterizes the context in which JEPA may underperform. This work innovates an approach that leverages unlabeled multimodal medical archives to improve predictive models and demonstrates its advantages and limitations in pulmonary nodule diagnosis.
Cohort-Aware Agents for Individualized Lung Cancer Risk Prediction Using a Retrieval-Augmented Model Selection Framework
Aug 20, 2025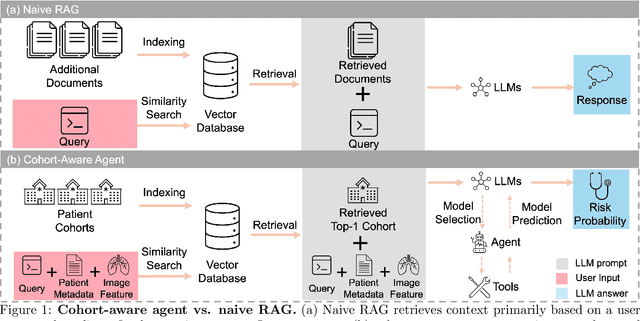

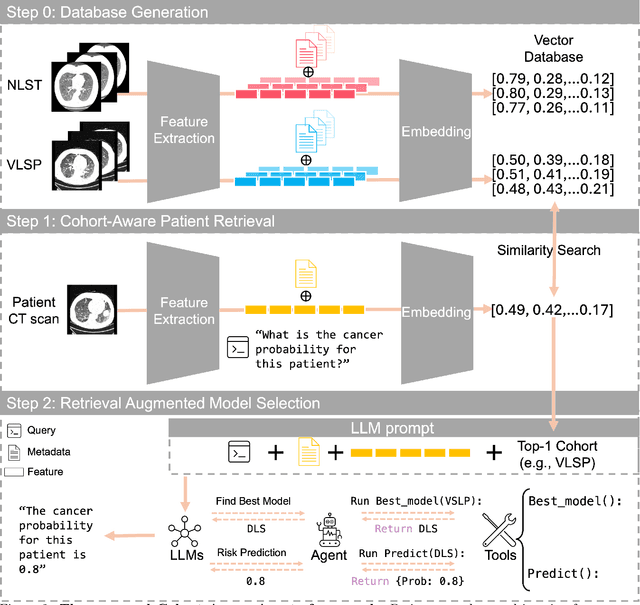
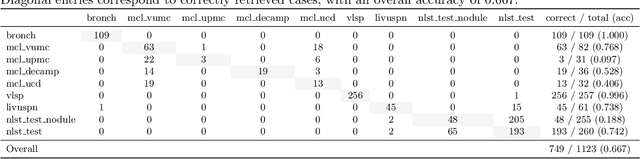
Accurate lung cancer risk prediction remains challenging due to substantial variability across patient populations and clinical settings -- no single model performs best for all cohorts. To address this, we propose a personalized lung cancer risk prediction agent that dynamically selects the most appropriate model for each patient by combining cohort-specific knowledge with modern retrieval and reasoning techniques. Given a patient's CT scan and structured metadata -- including demographic, clinical, and nodule-level features -- the agent first performs cohort retrieval using FAISS-based similarity search across nine diverse real-world cohorts to identify the most relevant patient population from a multi-institutional database. Second, a Large Language Model (LLM) is prompted with the retrieved cohort and its associated performance metrics to recommend the optimal prediction algorithm from a pool of eight representative models, including classical linear risk models (e.g., Mayo, Brock), temporally-aware models (e.g., TDVIT, DLSTM), and multi-modal computer vision-based approaches (e.g., Liao, Sybil, DLS, DLI). This two-stage agent pipeline -- retrieval via FAISS and reasoning via LLM -- enables dynamic, cohort-aware risk prediction personalized to each patient's profile. Building on this architecture, the agent supports flexible and cohort-driven model selection across diverse clinical populations, offering a practical path toward individualized risk assessment in real-world lung cancer screening.
Multipath cycleGAN for harmonization of paired and unpaired low-dose lung computed tomography reconstruction kernels
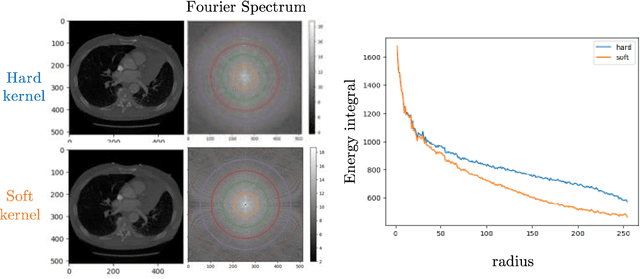
May 28, 2025Reconstruction kernels in computed tomography (CT) affect spatial resolution and noise characteristics, introducing systematic variability in quantitative imaging measurements such as emphysema quantification. Choosing an appropriate kernel is therefore essential for consistent quantitative analysis. We propose a multipath cycleGAN model for CT kernel harmonization, trained on a mixture of paired and unpaired data from a low-dose lung cancer screening cohort. The model features domain-specific encoders and decoders with a shared latent space and uses discriminators tailored for each domain.We train the model on 42 kernel combinations using 100 scans each from seven representative kernels in the National Lung Screening Trial (NLST) dataset. To evaluate performance, 240 scans from each kernel are harmonized to a reference soft kernel, and emphysema is quantified before and after harmonization. A general linear model assesses the impact of age, sex, smoking status, and kernel on emphysema. We also evaluate harmonization from soft kernels to a reference hard kernel. To assess anatomical consistency, we compare segmentations of lung vessels, muscle, and subcutaneous adipose tissue generated by TotalSegmentator between harmonized and original images. Our model is benchmarked against traditional and switchable cycleGANs. For paired kernels, our approach reduces bias in emphysema scores, as seen in Bland-Altman plots (p<0.05). For unpaired kernels, harmonization eliminates confounding differences in emphysema (p>0.05). High Dice scores confirm preservation of muscle and fat anatomy, while lung vessel overlap remains reasonable. Overall, our shared latent space multipath cycleGAN enables robust harmonization across paired and unpaired CT kernels, improving emphysema quantification and preserving anatomical fidelity.
Investigating the impact of kernel harmonization and deformable registration on inspiratory and expiratory chest CT images for people with COPD
Feb 07, 2025



Paired inspiratory-expiratory CT scans enable the quantification of gas trapping due to small airway disease and emphysema by analyzing lung tissue motion in COPD patients. Deformable image registration of these scans assesses regional lung volumetric changes. However, variations in reconstruction kernels between paired scans introduce errors in quantitative analysis. This work proposes a two-stage pipeline to harmonize reconstruction kernels and perform deformable image registration using data acquired from the COPDGene study. We use a cycle generative adversarial network (GAN) to harmonize inspiratory scans reconstructed with a hard kernel (BONE) to match expiratory scans reconstructed with a soft kernel (STANDARD). We then deformably register the expiratory scans to inspiratory scans. We validate harmonization by measuring emphysema using a publicly available segmentation algorithm before and after harmonization. Results show harmonization significantly reduces emphysema measurement inconsistencies, decreasing median emphysema scores from 10.479% to 3.039%, with a reference median score of 1.305% from the STANDARD kernel as the target. Registration accuracy is evaluated via Dice overlap between emphysema regions on inspiratory, expiratory, and deformed images. The Dice coefficient between inspiratory emphysema masks and deformably registered emphysema masks increases significantly across registration stages (p<0.001). Additionally, we demonstrate that deformable registration is robust to kernel variations.
Inter-vendor harmonization of Computed Tomography (CT) reconstruction kernels using unpaired image translation
Sep 22, 2023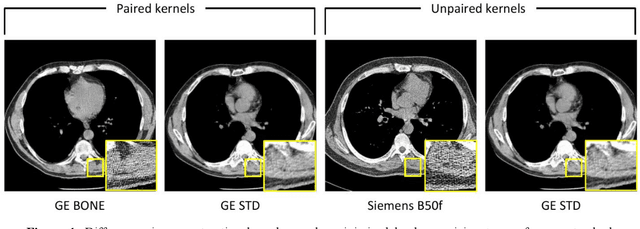
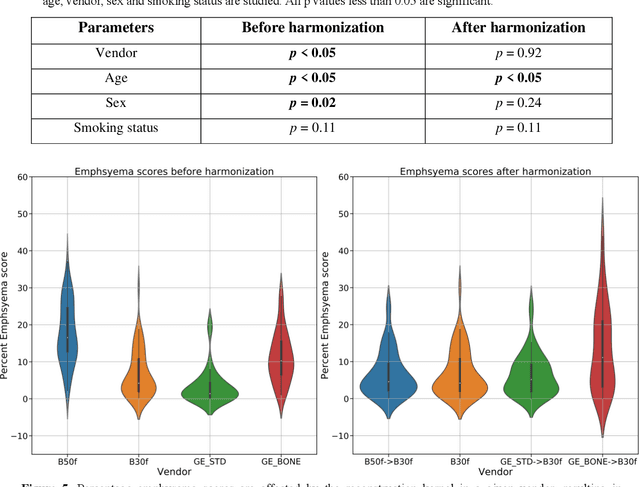
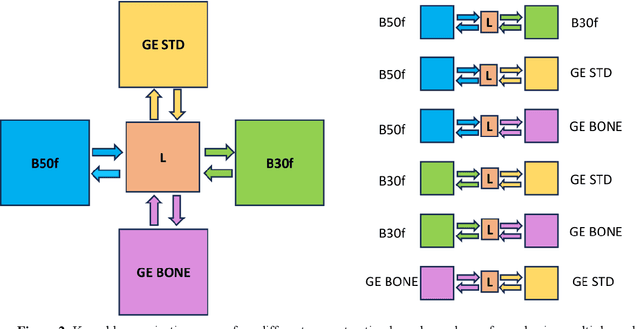
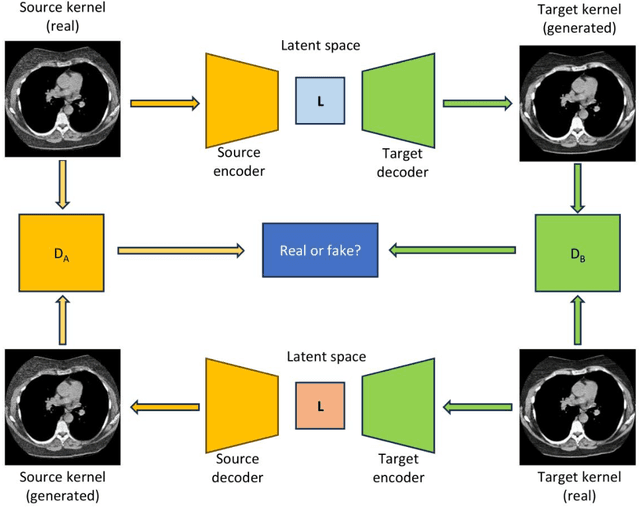
The reconstruction kernel in computed tomography (CT) generation determines the texture of the image. Consistency in reconstruction kernels is important as the underlying CT texture can impact measurements during quantitative image analysis. Harmonization (i.e., kernel conversion) minimizes differences in measurements due to inconsistent reconstruction kernels. Existing methods investigate harmonization of CT scans in single or multiple manufacturers. However, these methods require paired scans of hard and soft reconstruction kernels that are spatially and anatomically aligned. Additionally, a large number of models need to be trained across different kernel pairs within manufacturers. In this study, we adopt an unpaired image translation approach to investigate harmonization between and across reconstruction kernels from different manufacturers by constructing a multipath cycle generative adversarial network (GAN). We use hard and soft reconstruction kernels from the Siemens and GE vendors from the National Lung Screening Trial dataset. We use 50 scans from each reconstruction kernel and train a multipath cycle GAN. To evaluate the effect of harmonization on the reconstruction kernels, we harmonize 50 scans each from Siemens hard kernel, GE soft kernel and GE hard kernel to a reference Siemens soft kernel (B30f) and evaluate percent emphysema. We fit a linear model by considering the age, smoking status, sex and vendor and perform an analysis of variance (ANOVA) on the emphysema scores. Our approach minimizes differences in emphysema measurement and highlights the impact of age, sex, smoking status and vendor on emphysema quantification.
Longitudinal Multimodal Transformer Integrating Imaging and Latent Clinical Signatures From Routine EHRs for Pulmonary Nodule Classification
Apr 10, 2023



The accuracy of predictive models for solitary pulmonary nodule (SPN) diagnosis can be greatly increased by incorporating repeat imaging and medical context, such as electronic health records (EHRs). However, clinically routine modalities such as imaging and diagnostic codes can be asynchronous and irregularly sampled over different time scales which are obstacles to longitudinal multimodal learning. In this work, we propose a transformer-based multimodal strategy to integrate repeat imaging with longitudinal clinical signatures from routinely collected EHRs for SPN classification. We perform unsupervised disentanglement of latent clinical signatures and leverage time-distance scaled self-attention to jointly learn from clinical signatures expressions and chest computed tomography (CT) scans. Our classifier is pretrained on 2,668 scans from a public dataset and 1,149 subjects with longitudinal chest CTs, billing codes, medications, and laboratory tests from EHRs of our home institution. Evaluation on 227 subjects with challenging SPNs revealed a significant AUC improvement over a longitudinal multimodal baseline (0.824 vs 0.752 AUC), as well as improvements over a single cross-section multimodal scenario (0.809 AUC) and a longitudinal imaging-only scenario (0.741 AUC). This work demonstrates significant advantages with a novel approach for co-learning longitudinal imaging and non-imaging phenotypes with transformers.
Zero-shot CT Field-of-view Completion with Unconditional Generative Diffusion Prior
Apr 07, 2023Anatomically consistent field-of-view (FOV) completion to recover truncated body sections has important applications in quantitative analyses of computed tomography (CT) with limited FOV. Existing solution based on conditional generative models relies on the fidelity of synthetic truncation patterns at training phase, which poses limitations for the generalizability of the method to potential unknown types of truncation. In this study, we evaluate a zero-shot method based on a pretrained unconditional generative diffusion prior, where truncation pattern with arbitrary forms can be specified at inference phase. In evaluation on simulated chest CT slices with synthetic FOV truncation, the method is capable of recovering anatomically consistent body sections and subcutaneous adipose tissue measurement error caused by FOV truncation. However, the correction accuracy is inferior to the conditionally trained counterpart.
Body Composition Assessment with Limited Field-of-view Computed Tomography: A Semantic Image Extension Perspective
Jul 13, 2022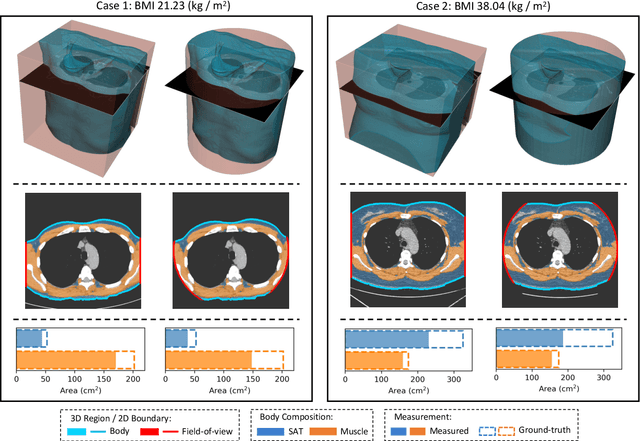
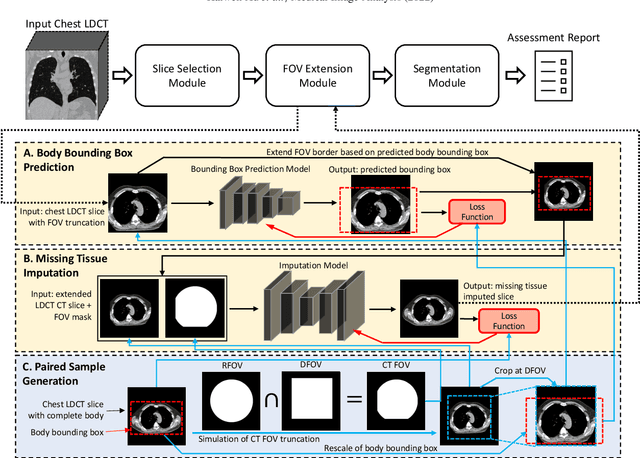
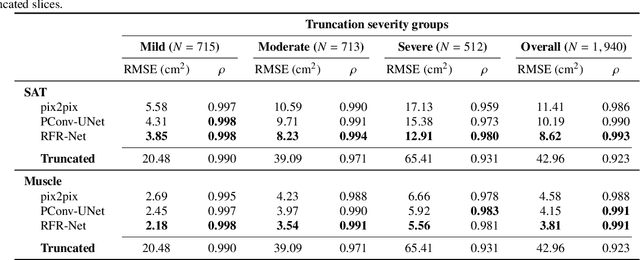
Field-of-view (FOV) tissue truncation beyond the lungs is common in routine lung screening computed tomography (CT). This poses limitations for opportunistic CT- based body composition (BC) assessment as key anatomical structures are missing. Traditionally, extending the FOV of CT is considered as a CT reconstruction problem using limited data. However, this approach relies on the projection domain data which might not be available in application. In this work, we formulate the problem from the semantic image extension perspective which only requires image data as inputs. The proposed two-stage method identifies a new FOV border based on the estimated extent of the complete body and imputes missing tissues in the truncated region. The training samples are simulated using CT slices with complete body in FOV, making the model development self-supervised. We evaluate the validity of the proposed method in automatic BC assessment using lung screening CT with limited FOV. The proposed method effectively restores the missing tissues and reduces BC assessment error introduced by FOV tissue truncation. In the BC assessment for a large-scale lung screening CT dataset, this correction improves both the intra-subject consistency and the correlation with anthropometric approximations. The developed method is available at https://github.com/MASILab/S-EFOV.
Technical Report: Quality Assessment Tool for Machine Learning with Clinical CT
Jul 27, 2021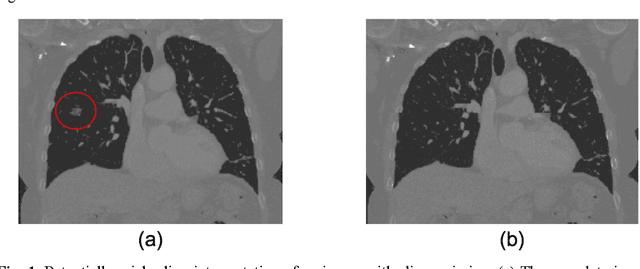

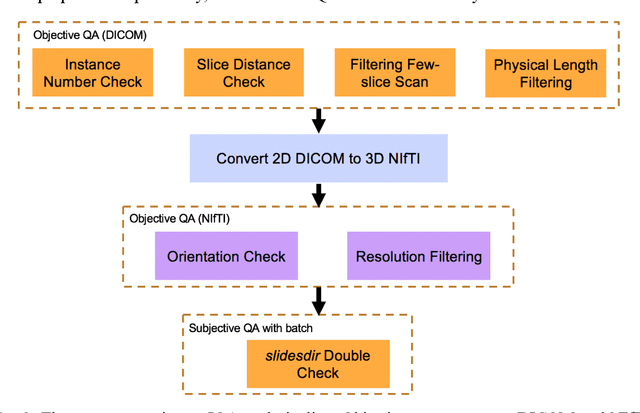

Image Quality Assessment (IQA) is important for scientific inquiry, especially in medical imaging and machine learning. Potential data quality issues can be exacerbated when human-based workflows use limited views of the data that may obscure digital artifacts. In practice, multiple factors such as network issues, accelerated acquisitions, motion artifacts, and imaging protocol design can impede the interpretation of image collections. The medical image processing community has developed a wide variety of tools for the inspection and validation of imaging data. Yet, IQA of computed tomography (CT) remains an under-recognized challenge, and no user-friendly tool is commonly available to address these potential issues. Here, we create and illustrate a pipeline specifically designed to identify and resolve issues encountered with large-scale data mining of clinically acquired CT data. Using the widely studied National Lung Screening Trial (NLST), we have identified approximately 4% of image volumes with quality concerns out of 17,392 scans. To assess robustness, we applied the proposed pipeline to our internal datasets where we find our tool is generalizable to clinically acquired medical images. In conclusion, the tool has been useful and time-saving for research study of clinical data, and the code and tutorials are publicly available at https://github.com/MASILab/QA_tool.