 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeG3R: Gradient Guided Generalizable Reconstruction
Sep 28, 2024Large scale 3D scene reconstruction is important for applications such as virtual reality and simulation. Existing neural rendering approaches (e.g., NeRF, 3DGS) have achieved realistic reconstructions on large scenes, but optimize per scene, which is expensive and slow, and exhibit noticeable artifacts under large view changes due to overfitting. Generalizable approaches or large reconstruction models are fast, but primarily work for small scenes/objects and often produce lower quality rendering results. In this work, we introduce G3R, a generalizable reconstruction approach that can efficiently predict high-quality 3D scene representations for large scenes. We propose to learn a reconstruction network that takes the gradient feedback signals from differentiable rendering to iteratively update a 3D scene representation, combining the benefits of high photorealism from per-scene optimization with data-driven priors from fast feed-forward prediction methods. Experiments on urban-driving and drone datasets show that G3R generalizes across diverse large scenes and accelerates the reconstruction process by at least 10x while achieving comparable or better realism compared to 3DGS, and also being more robust to large view changes.
UniCal: Unified Neural Sensor Calibration
Sep 27, 2024



Self-driving vehicles (SDVs) require accurate calibration of LiDARs and cameras to fuse sensor data accurately for autonomy. Traditional calibration methods typically leverage fiducials captured in a controlled and structured scene and compute correspondences to optimize over. These approaches are costly and require substantial infrastructure and operations, making it challenging to scale for vehicle fleets. In this work, we propose UniCal, a unified framework for effortlessly calibrating SDVs equipped with multiple LiDARs and cameras. Our approach is built upon a differentiable scene representation capable of rendering multi-view geometrically and photometrically consistent sensor observations. We jointly learn the sensor calibration and the underlying scene representation through differentiable volume rendering, utilizing outdoor sensor data without the need for specific calibration fiducials. This "drive-and-calibrate" approach significantly reduces costs and operational overhead compared to existing calibration systems, enabling efficient calibration for large SDV fleets at scale. To ensure geometric consistency across observations from different sensors, we introduce a novel surface alignment loss that combines feature-based registration with neural rendering. Comprehensive evaluations on multiple datasets demonstrate that UniCal outperforms or matches the accuracy of existing calibration approaches while being more efficient, demonstrating the value of UniCal for scalable calibration.
Learning to Drive via Asymmetric Self-Play
Sep 26, 2024
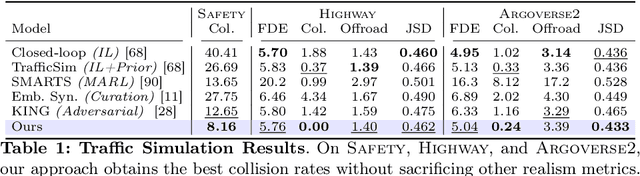
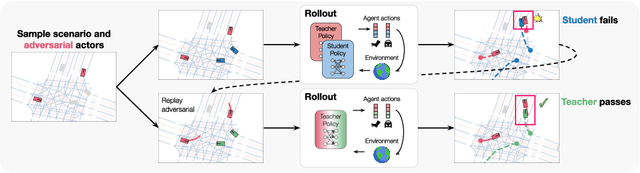
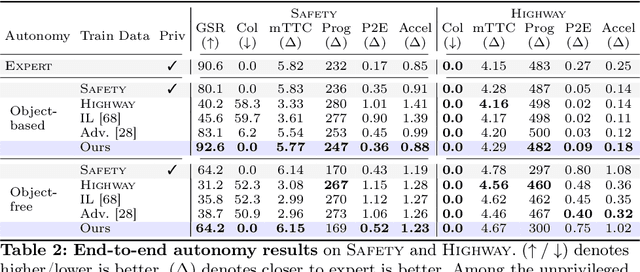
Large-scale data is crucial for learning realistic and capable driving policies. However, it can be impractical to rely on scaling datasets with real data alone. The majority of driving data is uninteresting, and deliberately collecting new long-tail scenarios is expensive and unsafe. We propose asymmetric self-play to scale beyond real data with additional challenging, solvable, and realistic synthetic scenarios. Our approach pairs a teacher that learns to generate scenarios it can solve but the student cannot, with a student that learns to solve them. When applied to traffic simulation, we learn realistic policies with significantly fewer collisions in both nominal and long-tail scenarios. Our policies further zero-shot transfer to generate training data for end-to-end autonomy, significantly outperforming state-of-the-art adversarial approaches, or using real data alone. For more information, visit https://waabi.ai/selfplay .
UnO: Unsupervised Occupancy Fields for Perception and Forecasting
Jun 12, 2024Perceiving the world and forecasting its future state is a critical task for self-driving. Supervised approaches leverage annotated object labels to learn a model of the world -- traditionally with object detections and trajectory predictions, or temporal bird's-eye-view (BEV) occupancy fields. However, these annotations are expensive and typically limited to a set of predefined categories that do not cover everything we might encounter on the road. Instead, we learn to perceive and forecast a continuous 4D (spatio-temporal) occupancy field with self-supervision from LiDAR data. This unsupervised world model can be easily and effectively transferred to downstream tasks. We tackle point cloud forecasting by adding a lightweight learned renderer and achieve state-of-the-art performance in Argoverse 2, nuScenes, and KITTI. To further showcase its transferability, we fine-tune our model for BEV semantic occupancy forecasting and show that it outperforms the fully supervised state-of-the-art, especially when labeled data is scarce. Finally, when compared to prior state-of-the-art on spatio-temporal geometric occupancy prediction, our 4D world model achieves a much higher recall of objects from classes relevant to self-driving.
DeTra: A Unified Model for Object Detection and Trajectory Forecasting
Jun 06, 2024The tasks of object detection and trajectory forecasting play a crucial role in understanding the scene for autonomous driving. These tasks are typically executed in a cascading manner, making them prone to compounding errors. Furthermore, there is usually a very thin interface between the two tasks, creating a lossy information bottleneck. To address these challenges, our approach formulates the union of the two tasks as a trajectory refinement problem, where the first pose is the detection (current time), and the subsequent poses are the waypoints of the multiple forecasts (future time). To tackle this unified task, we design a refinement transformer that infers the presence, pose, and multi-modal future behaviors of objects directly from LiDAR point clouds and high-definition maps. We call this model DeTra, short for object Detection and Trajectory forecasting. In our experiments, we observe that \ourmodel{} outperforms the state-of-the-art on Argoverse 2 Sensor and Waymo Open Dataset by a large margin, across a broad range of metrics. Last but not least, we perform extensive ablation studies that show the value of refinement for this task, that every proposed component contributes positively to its performance, and that key design choices were made.
QuAD: Query-based Interpretable Neural Motion Planning for Autonomous Driving
Apr 01, 2024

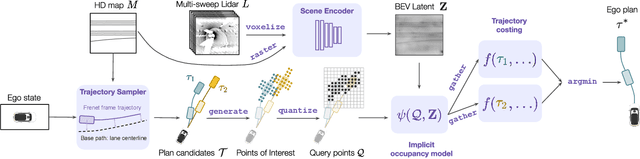

A self-driving vehicle must understand its environment to determine the appropriate action. Traditional autonomy systems rely on object detection to find the agents in the scene. However, object detection assumes a discrete set of objects and loses information about uncertainty, so any errors compound when predicting the future behavior of those agents. Alternatively, dense occupancy grid maps have been utilized to understand free-space. However, predicting a grid for the entire scene is wasteful since only certain spatio-temporal regions are reachable and relevant to the self-driving vehicle. We present a unified, interpretable, and efficient autonomy framework that moves away from cascading modules that first perceive, then predict, and finally plan. Instead, we shift the paradigm to have the planner query occupancy at relevant spatio-temporal points, restricting the computation to those regions of interest. Exploiting this representation, we evaluate candidate trajectories around key factors such as collision avoidance, comfort, and progress for safety and interpretability. Our approach achieves better highway driving quality than the state-of-the-art in high-fidelity closed-loop simulations.
LightSim: Neural Lighting Simulation for Urban Scenes
Dec 11, 2023Different outdoor illumination conditions drastically alter the appearance of urban scenes, and they can harm the performance of image-based robot perception systems if not seen during training. Camera simulation provides a cost-effective solution to create a large dataset of images captured under different lighting conditions. Towards this goal, we propose LightSim, a neural lighting camera simulation system that enables diverse, realistic, and controllable data generation. LightSim automatically builds lighting-aware digital twins at scale from collected raw sensor data and decomposes the scene into dynamic actors and static background with accurate geometry, appearance, and estimated scene lighting. These digital twins enable actor insertion, modification, removal, and rendering from a new viewpoint, all in a lighting-aware manner. LightSim then combines physically-based and learnable deferred rendering to perform realistic relighting of modified scenes, such as altering the sun location and modifying the shadows or changing the sun brightness, producing spatially- and temporally-consistent camera videos. Our experiments show that LightSim generates more realistic relighting results than prior work. Importantly, training perception models on data generated by LightSim can significantly improve their performance.
4D-Former: Multimodal 4D Panoptic Segmentation
Nov 17, 2023



4D panoptic segmentation is a challenging but practically useful task that requires every point in a LiDAR point-cloud sequence to be assigned a semantic class label, and individual objects to be segmented and tracked over time. Existing approaches utilize only LiDAR inputs which convey limited information in regions with point sparsity. This problem can, however, be mitigated by utilizing RGB camera images which offer appearance-based information that can reinforce the geometry-based LiDAR features. Motivated by this, we propose 4D-Former: a novel method for 4D panoptic segmentation which leverages both LiDAR and image modalities, and predicts semantic masks as well as temporally consistent object masks for the input point-cloud sequence. We encode semantic classes and objects using a set of concise queries which absorb feature information from both data modalities. Additionally, we propose a learned mechanism to associate object tracks over time which reasons over both appearance and spatial location. We apply 4D-Former to the nuScenes and SemanticKITTI datasets where it achieves state-of-the-art results.
Real-Time Neural Rasterization for Large Scenes
Nov 09, 2023We propose a new method for realistic real-time novel-view synthesis (NVS) of large scenes. Existing neural rendering methods generate realistic results, but primarily work for small scale scenes (<50 square meters) and have difficulty at large scale (>10000 square meters). Traditional graphics-based rasterization rendering is fast for large scenes but lacks realism and requires expensive manually created assets. Our approach combines the best of both worlds by taking a moderate-quality scaffold mesh as input and learning a neural texture field and shader to model view-dependant effects to enhance realism, while still using the standard graphics pipeline for real-time rendering. Our method outperforms existing neural rendering methods, providing at least 30x faster rendering with comparable or better realism for large self-driving and drone scenes. Our work is the first to enable real-time rendering of large real-world scenes.
Reconstructing Objects in-the-wild for Realistic Sensor Simulation
Nov 09, 2023



Reconstructing objects from real world data and rendering them at novel views is critical to bringing realism, diversity and scale to simulation for robotics training and testing. In this work, we present NeuSim, a novel approach that estimates accurate geometry and realistic appearance from sparse in-the-wild data captured at distance and at limited viewpoints. Towards this goal, we represent the object surface as a neural signed distance function and leverage both LiDAR and camera sensor data to reconstruct smooth and accurate geometry and normals. We model the object appearance with a robust physics-inspired reflectance representation effective for in-the-wild data. Our experiments show that NeuSim has strong view synthesis performance on challenging scenarios with sparse training views. Furthermore, we showcase composing NeuSim assets into a virtual world and generating realistic multi-sensor data for evaluating self-driving perception models.