 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning to Drive via Asymmetric Self-Play
Sep 26, 2024
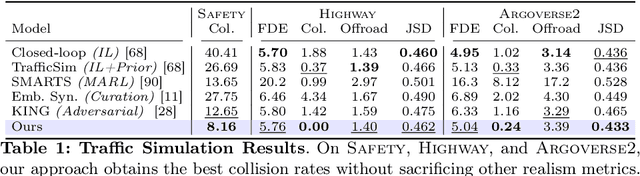
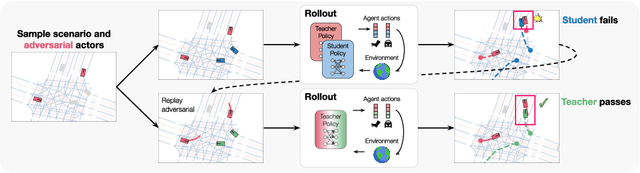
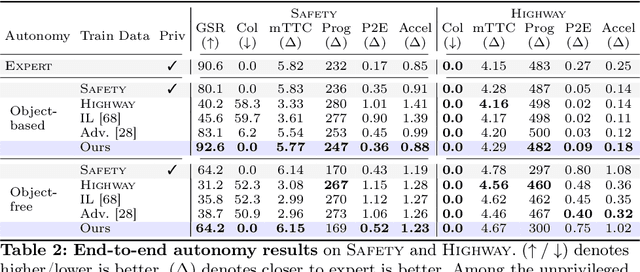
Large-scale data is crucial for learning realistic and capable driving policies. However, it can be impractical to rely on scaling datasets with real data alone. The majority of driving data is uninteresting, and deliberately collecting new long-tail scenarios is expensive and unsafe. We propose asymmetric self-play to scale beyond real data with additional challenging, solvable, and realistic synthetic scenarios. Our approach pairs a teacher that learns to generate scenarios it can solve but the student cannot, with a student that learns to solve them. When applied to traffic simulation, we learn realistic policies with significantly fewer collisions in both nominal and long-tail scenarios. Our policies further zero-shot transfer to generate training data for end-to-end autonomy, significantly outperforming state-of-the-art adversarial approaches, or using real data alone. For more information, visit https://waabi.ai/selfplay .
QuAD: Query-based Interpretable Neural Motion Planning for Autonomous Driving
Apr 01, 2024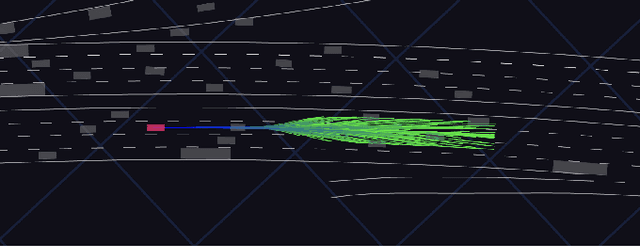

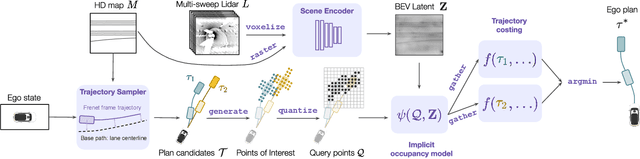

A self-driving vehicle must understand its environment to determine the appropriate action. Traditional autonomy systems rely on object detection to find the agents in the scene. However, object detection assumes a discrete set of objects and loses information about uncertainty, so any errors compound when predicting the future behavior of those agents. Alternatively, dense occupancy grid maps have been utilized to understand free-space. However, predicting a grid for the entire scene is wasteful since only certain spatio-temporal regions are reachable and relevant to the self-driving vehicle. We present a unified, interpretable, and efficient autonomy framework that moves away from cascading modules that first perceive, then predict, and finally plan. Instead, we shift the paradigm to have the planner query occupancy at relevant spatio-temporal points, restricting the computation to those regions of interest. Exploiting this representation, we evaluate candidate trajectories around key factors such as collision avoidance, comfort, and progress for safety and interpretability. Our approach achieves better highway driving quality than the state-of-the-art in high-fidelity closed-loop simulations.
Hierarchical Neural Implicit Pose Network for Animation and Motion Retargeting
Dec 02, 2021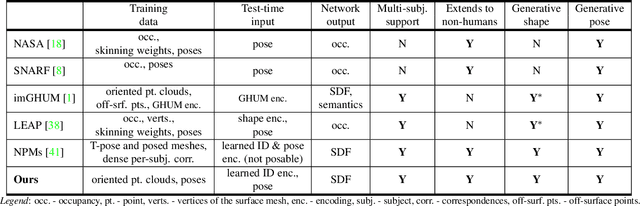
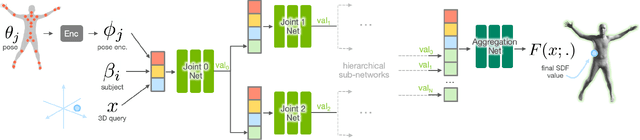
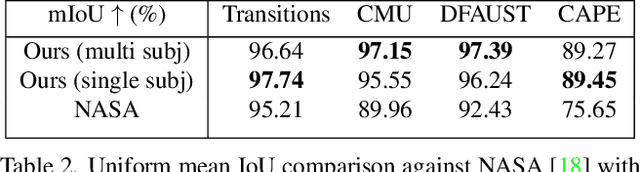
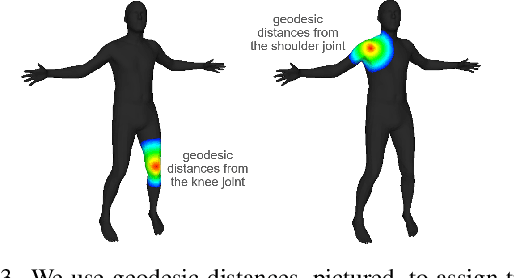
We present HIPNet, a neural implicit pose network trained on multiple subjects across many poses. HIPNet can disentangle subject-specific details from pose-specific details, effectively enabling us to retarget motion from one subject to another or to animate between keyframes through latent space interpolation. To this end, we employ a hierarchical skeleton-based representation to learn a signed distance function on a canonical unposed space. This joint-based decomposition enables us to represent subtle details that are local to the space around the body joint. Unlike previous neural implicit method that requires ground-truth SDF for training, our model we only need a posed skeleton and the point cloud for training, and we have no dependency on a traditional parametric model or traditional skinning approaches. We achieve state-of-the-art results on various single-subject and multi-subject benchmarks.
MuSCLE: Multi Sweep Compression of LiDAR using Deep Entropy Models
Nov 15, 2020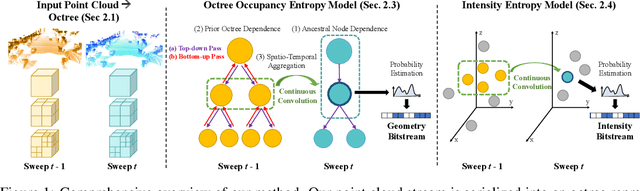

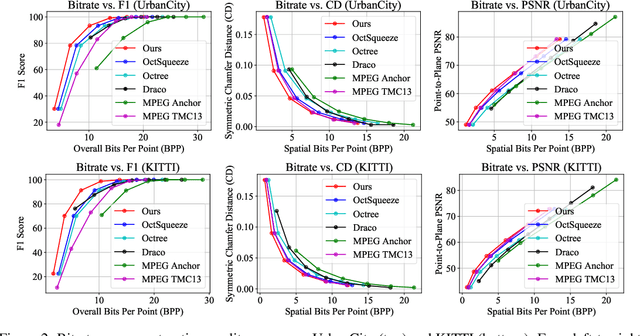
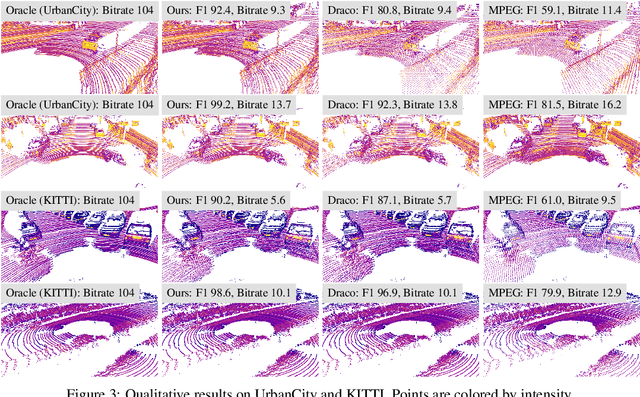
We present a novel compression algorithm for reducing the storage of LiDAR sensor data streams. Our model exploits spatio-temporal relationships across multiple LiDAR sweeps to reduce the bitrate of both geometry and intensity values. Towards this goal, we propose a novel conditional entropy model that models the probabilities of the octree symbols by considering both coarse level geometry and previous sweeps' geometric and intensity information. We then use the learned probability to encode the full data stream into a compact one. Our experiments demonstrate that our method significantly reduces the joint geometry and intensity bitrate over prior state-of-the-art LiDAR compression methods, with a reduction of 7-17% and 15-35% on the UrbanCity and SemanticKITTI datasets respectively.
CoinPress: Practical Private Mean and Covariance Estimation
Jun 11, 2020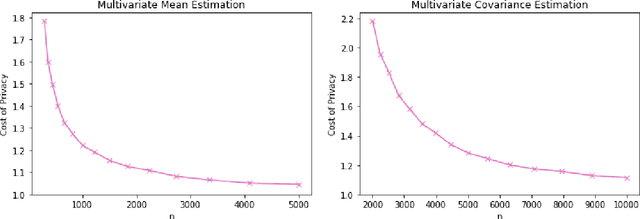
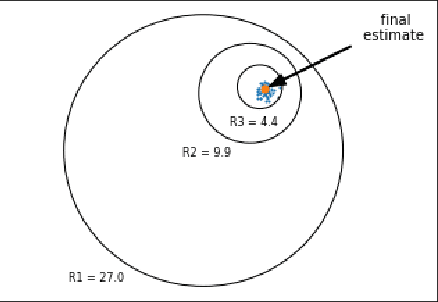
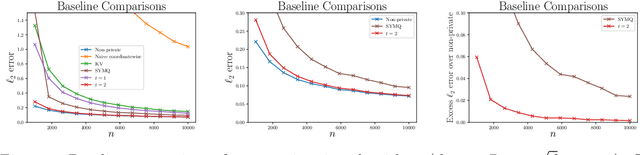
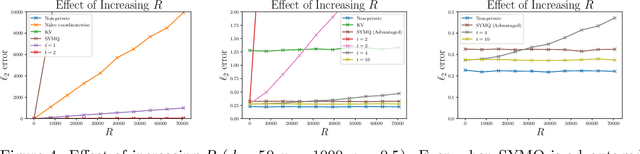
We present simple differentially private estimators for the mean and covariance of multivariate sub-Gaussian data that are accurate at small sample sizes. We demonstrate the effectiveness of our algorithms both theoretically and empirically using synthetic and real-world datasets---showing that their asymptotic error rates match the state-of-the-art theoretical bounds, and that they concretely outperform all previous methods. Specifically, previous estimators either have weak empirical accuracy at small sample sizes, perform poorly for multivariate data, or require the user to provide strong a priori estimates for the parameters.