 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-Method Validation of Large Language Model Medical Translation Across High- and Low-Resource Languages
Mar 23, 2026Language barriers affect 27.3 million U.S. residents with non-English language preference, yet professional medical translation remains costly and often unavailable. We evaluated four frontier large language models (GPT-5.1, Claude Opus 4.5, Gemini 3 Pro, Kimi K2) translating 22 medical documents into 8 languages spanning high-resource (Spanish, Chinese, Russian, Vietnamese), medium-resource (Korean, Arabic), and low-resource (Tagalog, Haitian Creole) categories using a five-layer validation framework. Across 704 translation pairs, all models achieved high semantic preservation (LaBSE greater than 0.92), with no significant difference between high- and low-resource languages (p = 0.066). Cross-model back-translation confirmed results were not driven by same-model circularity (delta = -0.0009). Inter-model concordance across four independently trained models was high (LaBSE: 0.946), and lexical borrowing analysis showed no correlation between English term retention and fidelity scores in low-resource languages (rho = +0.018, p = 0.82). These converging results suggest frontier LLMs preserve medical meaning across resource levels, with implications for language access in healthcare.
Deployment and Evaluation of an EHR-integrated, Large Language Model-Powered Tool to Triage Surgical Patients
Mar 18, 2026Surgical co-management (SCM) is an evidence-based model in which hospitalists jointly manage medically complex perioperative patients alongside surgical teams. Despite its clinical and financial value, SCM is limited by the need to manually identify eligible patients. To determine whether SCM triage can be automated, we conducted a prospective, unblinded study at Stanford Health Care in which an LLM-based, electronic health record (EHR)-integrated triage tool (SCM Navigator) provided SCM recommendations followed by physician review. Using pre-operative documentation, structured data, and clinical criteria for perioperative morbidity, SCM Navigator categorized patients as appropriate, not appropriate, or possibly appropriate for SCM. Faculty indicated their clinical judgment and provided free-text feedback when they disagreed. Sensitivity, specificity, positive predictive value, and negative predictive value were measured using physician determinations as a reference. Free-text reasons were thematically categorized, and manual chart review was conducted on all false-negative cases and 30 randomly selected cases from the largest false-positive category. Since deployment, 6,193 cases have been triaged, of which 1,582 (23%) were recommended for hospitalist consultation. SCM Navigator displayed high sensitivity (0.94, 95% CI 0.91-0.96) and moderate specificity (0.74, 95% CI 0.71-0.77). Post-hoc chart review suggested most discrepancies reflect modifiable gaps in clinical criteria, institutional workflow, or physician practice variability rather than LLM misclassification, which accounted for 2 of 19 (11%) false-negative cases. These findings demonstrate that an LLM-powered, EHR-integrated, human-in-the-loop AI system can accurately and safely triage surgical patients for SCM, and that AI-enabled screening tools can augment and potentially automate time-intensive clinical workflows.
Towards Learning High-Precision Least Squares Algorithms with Sequence Models
Mar 15, 2025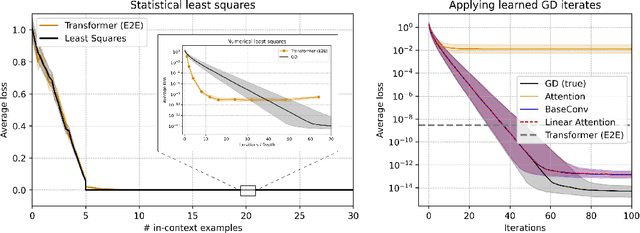

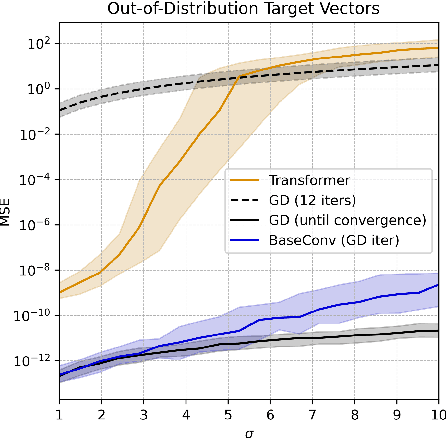
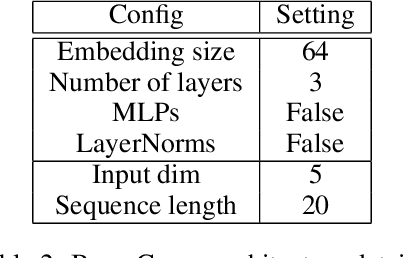
This paper investigates whether sequence models can learn to perform numerical algorithms, e.g. gradient descent, on the fundamental problem of least squares. Our goal is to inherit two properties of standard algorithms from numerical analysis: (1) machine precision, i.e. we want to obtain solutions that are accurate to near floating point error, and (2) numerical generality, i.e. we want them to apply broadly across problem instances. We find that prior approaches using Transformers fail to meet these criteria, and identify limitations present in existing architectures and training procedures. First, we show that softmax Transformers struggle to perform high-precision multiplications, which prevents them from precisely learning numerical algorithms. Second, we identify an alternate class of architectures, comprised entirely of polynomials, that can efficiently represent high-precision gradient descent iterates. Finally, we investigate precision bottlenecks during training and address them via a high-precision training recipe that reduces stochastic gradient noise. Our recipe enables us to train two polynomial architectures, gated convolutions and linear attention, to perform gradient descent iterates on least squares problems. For the first time, we demonstrate the ability to train to near machine precision. Applied iteratively, our models obtain 100,000x lower MSE than standard Transformers trained end-to-end and they incur a 10,000x smaller generalization gap on out-of-distribution problems. We make progress towards end-to-end learning of numerical algorithms for least squares.
FullStack Bench: Evaluating LLMs as Full Stack Coders
Dec 03, 2024



As the capabilities of code large language models (LLMs) continue to expand, their applications across diverse code intelligence domains are rapidly increasing. However, most existing datasets only evaluate limited application domains. To address this gap, we have developed a comprehensive code evaluation dataset FullStack Bench focusing on full-stack programming, which encompasses a wide range of application domains (e.g., basic programming, data analysis, software engineering, mathematics, and machine learning). Besides, to assess multilingual programming capabilities, in FullStack Bench, we design real-world instructions and corresponding unit test cases from 16 widely-used programming languages to reflect real-world usage scenarios rather than simple translations. Moreover, we also release an effective code sandbox execution tool (i.e., SandboxFusion) supporting various programming languages and packages to evaluate the performance of our FullStack Bench efficiently. Comprehensive experimental results on our FullStack Bench demonstrate the necessity and effectiveness of our FullStack Bench and SandboxFusion.
Deep Structured Reactive Planning
Jan 18, 2021
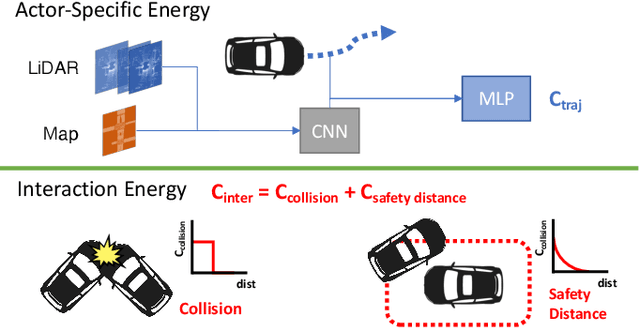

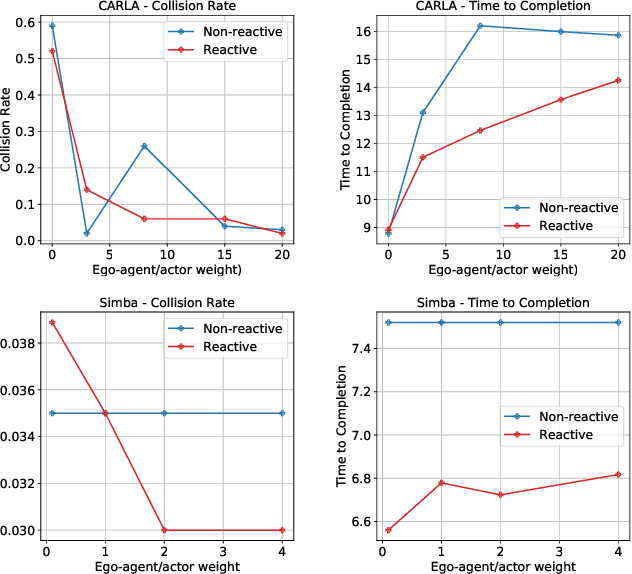
An intelligent agent operating in the real-world must balance achieving its goal with maintaining the safety and comfort of not only itself, but also other participants within the surrounding scene. This requires jointly reasoning about the behavior of other actors while deciding its own actions as these two processes are inherently intertwined - a vehicle will yield to us if we decide to proceed first at the intersection but will proceed first if we decide to yield. However, this is not captured in most self-driving pipelines, where planning follows prediction. In this paper we propose a novel data-driven, reactive planning objective which allows a self-driving vehicle to jointly reason about its own plans as well as how other actors will react to them. We formulate the problem as an energy-based deep structured model that is learned from observational data and encodes both the planning and prediction problems. Through simulations based on both real-world driving and synthetically generated dense traffic, we demonstrate that our reactive model outperforms a non-reactive variant in successfully completing highly complex maneuvers (lane merges/turns in traffic) faster, without trading off collision rate.
MuSCLE: Multi Sweep Compression of LiDAR using Deep Entropy Models
Nov 15, 2020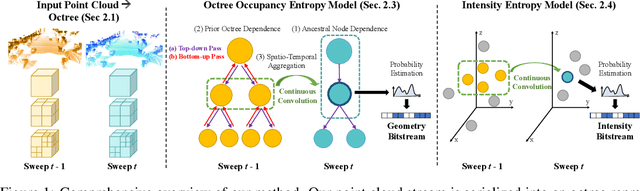

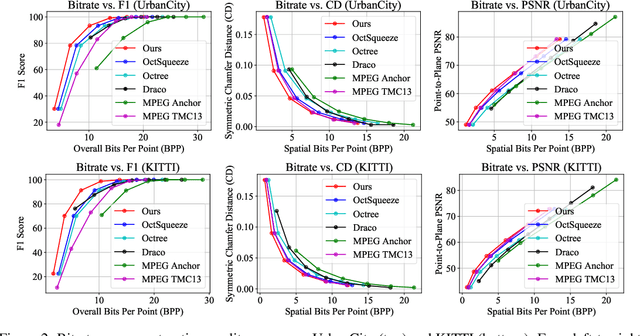
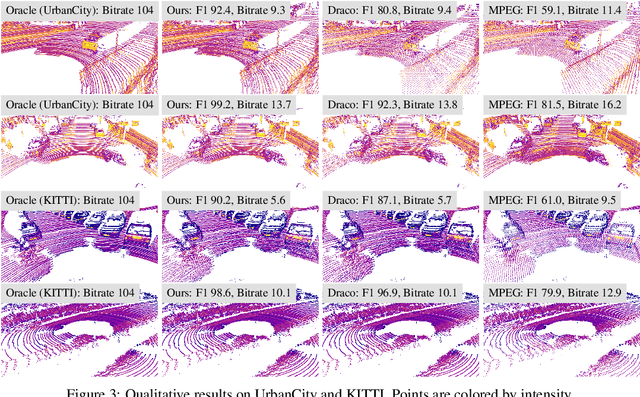
We present a novel compression algorithm for reducing the storage of LiDAR sensor data streams. Our model exploits spatio-temporal relationships across multiple LiDAR sweeps to reduce the bitrate of both geometry and intensity values. Towards this goal, we propose a novel conditional entropy model that models the probabilities of the octree symbols by considering both coarse level geometry and previous sweeps' geometric and intensity information. We then use the learned probability to encode the full data stream into a compact one. Our experiments demonstrate that our method significantly reduces the joint geometry and intensity bitrate over prior state-of-the-art LiDAR compression methods, with a reduction of 7-17% and 15-35% on the UrbanCity and SemanticKITTI datasets respectively.
Conditional Entropy Coding for Efficient Video Compression
Aug 20, 2020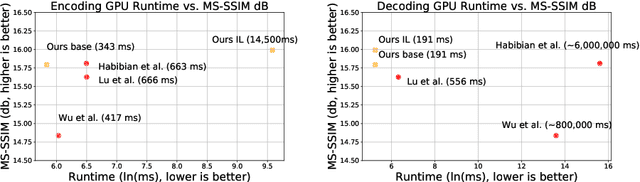
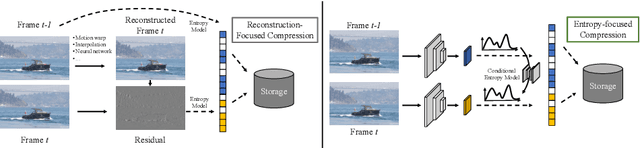
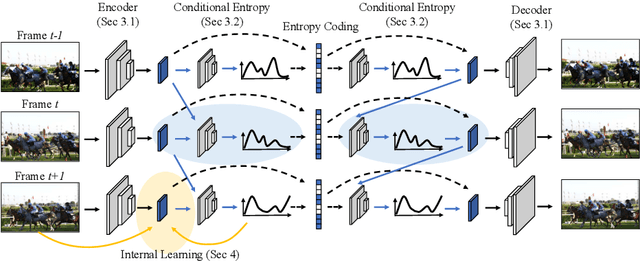
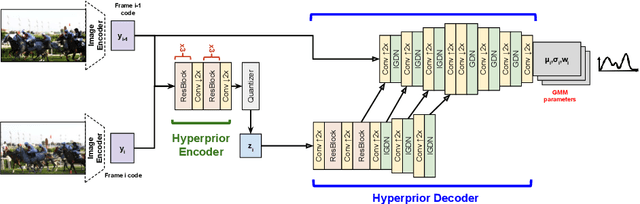
We propose a very simple and efficient video compression framework that only focuses on modeling the conditional entropy between frames. Unlike prior learning-based approaches, we reduce complexity by not performing any form of explicit transformations between frames and assume each frame is encoded with an independent state-of-the-art deep image compressor. We first show that a simple architecture modeling the entropy between the image latent codes is as competitive as other neural video compression works and video codecs while being much faster and easier to implement. We then propose a novel internal learning extension on top of this architecture that brings an additional 10% bitrate savings without trading off decoding speed. Importantly, we show that our approach outperforms H.265 and other deep learning baselines in MS-SSIM on higher bitrate UVG video, and against all video codecs on lower framerates, while being thousands of times faster in decoding than deep models utilizing an autoregressive entropy model.
OctSqueeze: Octree-Structured Entropy Model for LiDAR Compression
May 14, 2020



We present a novel deep compression algorithm to reduce the memory footprint of LiDAR point clouds. Our method exploits the sparsity and structural redundancy between points to reduce the bitrate. Towards this goal, we first encode the LiDAR points into an octree, a data-efficient structure suitable for sparse point clouds. We then design a tree-structured conditional entropy model that models the probabilities of the octree symbols to encode the octree into a compact bitstream. We validate the effectiveness of our method over two large-scale datasets. The results demonstrate that our approach reduces the bitrate by 10-20% at the same reconstruction quality, compared to the previous state-of-the-art. Importantly, we also show that for the same bitrate, our approach outperforms other compression algorithms when performing downstream 3D segmentation and detection tasks using compressed representations. Our algorithm can be used to reduce the onboard and offboard storage of LiDAR points for applications such as self-driving cars, where a single vehicle captures 84 billion points per day
DSIC: Deep Stereo Image Compression
Aug 09, 2019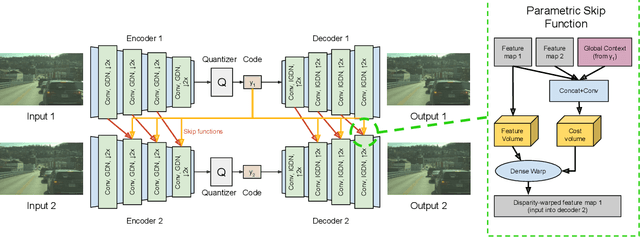
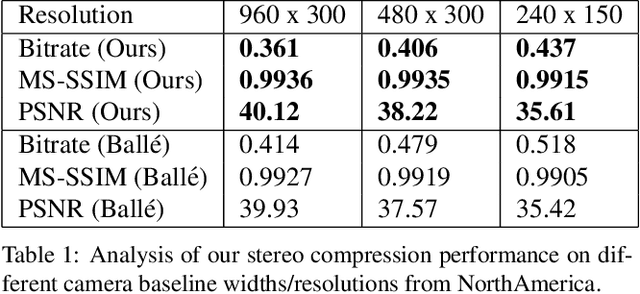
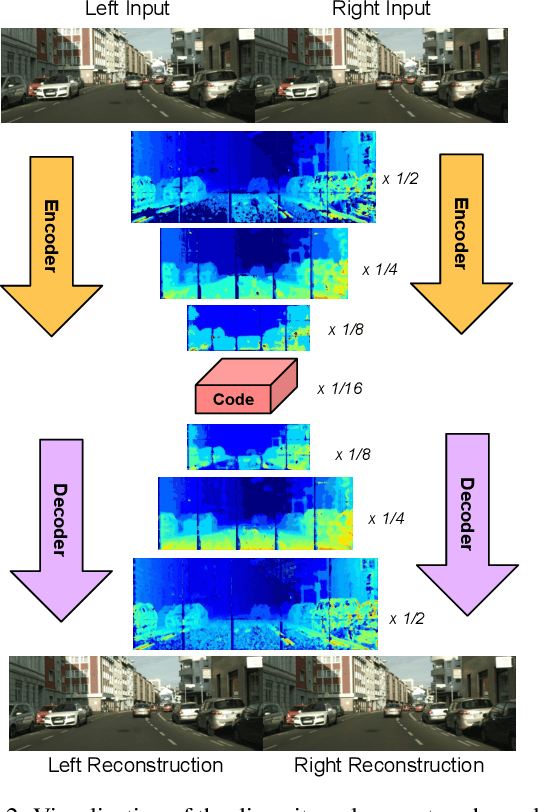
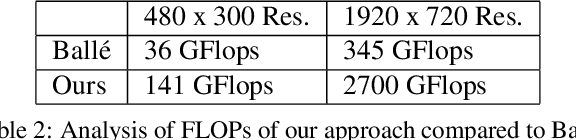
In this paper we tackle the problem of stereo image compression, and leverage the fact that the two images have overlapping fields of view to further compress the representations. Our approach leverages state-of-the-art single-image compression autoencoders and enhances the compression with novel parametric skip functions to feed fully differentiable, disparity-warped features at all levels to the encoder/decoder of the second image. Moreover, we model the probabilistic dependence between the image codes using a conditional entropy model. Our experiments show an impressive 30 - 50% reduction in the second image bitrate at low bitrates compared to deep single-image compression, and a 10 - 20% reduction at higher bitrates.
Interactive 3D Modeling with a Generative Adversarial Network
Jan 07, 2018
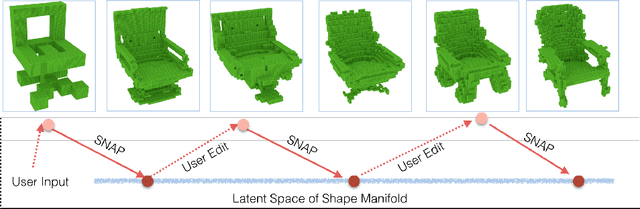


This paper proposes the idea of using a generative adversarial network (GAN) to assist a novice user in designing real-world shapes with a simple interface. The user edits a voxel grid with a painting interface (like Minecraft). Yet, at any time, he/she can execute a SNAP command, which projects the current voxel grid onto a latent shape manifold with a learned projection operator and then generates a similar, but more realistic, shape using a learned generator network. Then the user can edit the resulting shape and snap again until he/she is satisfied with the result. The main advantage of this approach is that the projection and generation operators assist novice users to create 3D models characteristic of a background distribution of object shapes, but without having to specify all the details. The core new research idea is to use a GAN to support this application. 3D GANs have previously been used for shape generation, interpolation, and completion, but never for interactive modeling. The new challenge for this application is to learn a projection operator that takes an arbitrary 3D voxel model and produces a latent vector on the shape manifold from which a similar and realistic shape can be generated. We develop algorithms for this and other steps of the SNAP processing pipeline and integrate them into a simple modeling tool. Experiments with these algorithms and tool suggest that GANs provide a promising approach to computer-assisted interactive modeling.