 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCreativeVR: Diffusion-Prior-Guided Approach for Structure and Motion Restoration in Generative and Real Videos
Dec 12, 2025Modern text-to-video (T2V) diffusion models can synthesize visually compelling clips, yet they remain brittle at fine-scale structure: even state-of-the-art generators often produce distorted faces and hands, warped backgrounds, and temporally inconsistent motion. Such severe structural artifacts also appear in very low-quality real-world videos. Classical video restoration and super-resolution (VR/VSR) methods, in contrast, are tuned for synthetic degradations such as blur and downsampling and tend to stabilize these artifacts rather than repair them, while diffusion-prior restorers are usually trained on photometric noise and offer little control over the trade-off between perceptual quality and fidelity. We introduce CreativeVR, a diffusion-prior-guided video restoration framework for AI-generated (AIGC) and real videos with severe structural and temporal artifacts. Our deep-adapter-based method exposes a single precision knob that controls how strongly the model follows the input, smoothly trading off between precise restoration on standard degradations and stronger structure- and motion-corrective behavior on challenging content. Our key novelty is a temporally coherent degradation module used during training, which applies carefully designed transformations that produce realistic structural failures. To evaluate AIGC-artifact restoration, we propose the AIGC54 benchmark with FIQA, semantic and perceptual metrics, and multi-aspect scoring. CreativeVR achieves state-of-the-art results on videos with severe artifacts and performs competitively on standard video restoration benchmarks, while running at practical throughput (about 13 FPS at 720p on a single 80-GB A100). Project page: https://daveishan.github.io/creativevr-webpage/.
SpotEdit: Evaluating Visually-Guided Image Editing Methods
Aug 25, 2025Visually-guided image editing, where edits are conditioned on both visual cues and textual prompts, has emerged as a powerful paradigm for fine-grained, controllable content generation. Although recent generative models have shown remarkable capabilities, existing evaluations remain simple and insufficiently representative of real-world editing challenges. We present SpotEdit, a comprehensive benchmark designed to systematically assess visually-guided image editing methods across diverse diffusion, autoregressive, and hybrid generative models, uncovering substantial performance disparities. To address a critical yet underexplored challenge, our benchmark includes a dedicated component on hallucination, highlighting how leading models, such as GPT-4o, often hallucinate the existence of a visual cue and erroneously perform the editing task. Our code and benchmark are publicly released at https://github.com/SaraGhazanfari/SpotEdit.
Exploring Adversarial Robustness of Multi-Sensor Perception Systems in Self Driving
Jan 26, 2021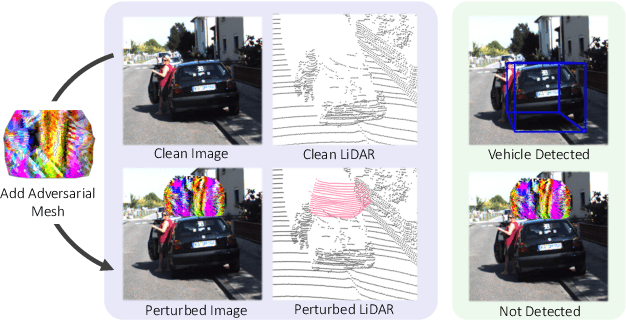
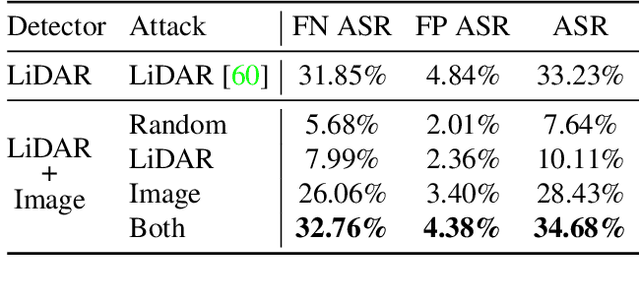
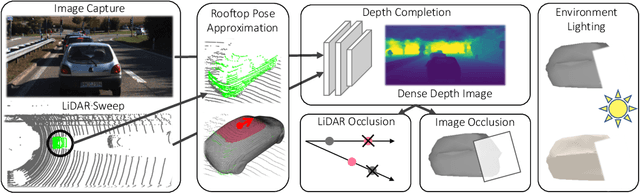
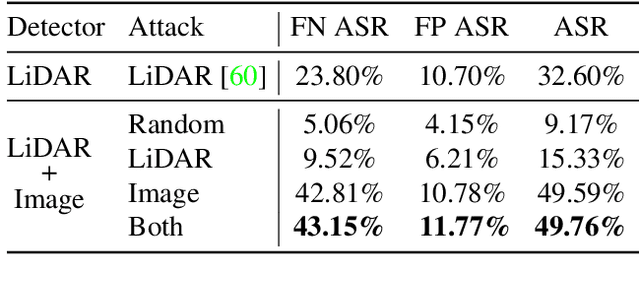
Modern self-driving perception systems have been shown to improve upon processing complementary inputs such as LiDAR with images. In isolation, 2D images have been found to be extremely vulnerable to adversarial attacks. Yet, there have been limited studies on the adversarial robustness of multi-modal models that fuse LiDAR features with image features. Furthermore, existing works do not consider physically realizable perturbations that are consistent across the input modalities. In this paper, we showcase practical susceptibilities of multi-sensor detection by placing an adversarial object on top of a host vehicle. We focus on physically realizable and input-agnostic attacks as they are feasible to execute in practice, and show that a single universal adversary can hide different host vehicles from state-of-the-art multi-modal detectors. Our experiments demonstrate that successful attacks are primarily caused by easily corrupted image features. Furthermore, we find that in modern sensor fusion methods which project image features into 3D, adversarial attacks can exploit the projection process to generate false positives across distant regions in 3D. Towards more robust multi-modal perception systems, we show that adversarial training with feature denoising can boost robustness to such attacks significantly. However, we find that standard adversarial defenses still struggle to prevent false positives which are also caused by inaccurate associations between 3D LiDAR points and 2D pixels.
Non-parametric Memory for Spatio-Temporal Segmentation of Construction Zones for Self-Driving
Jan 18, 2021
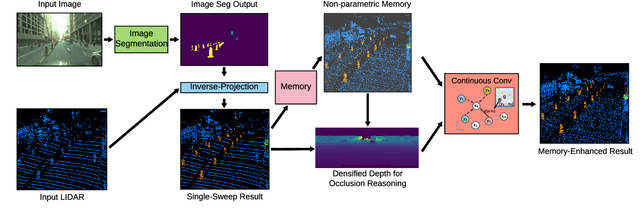
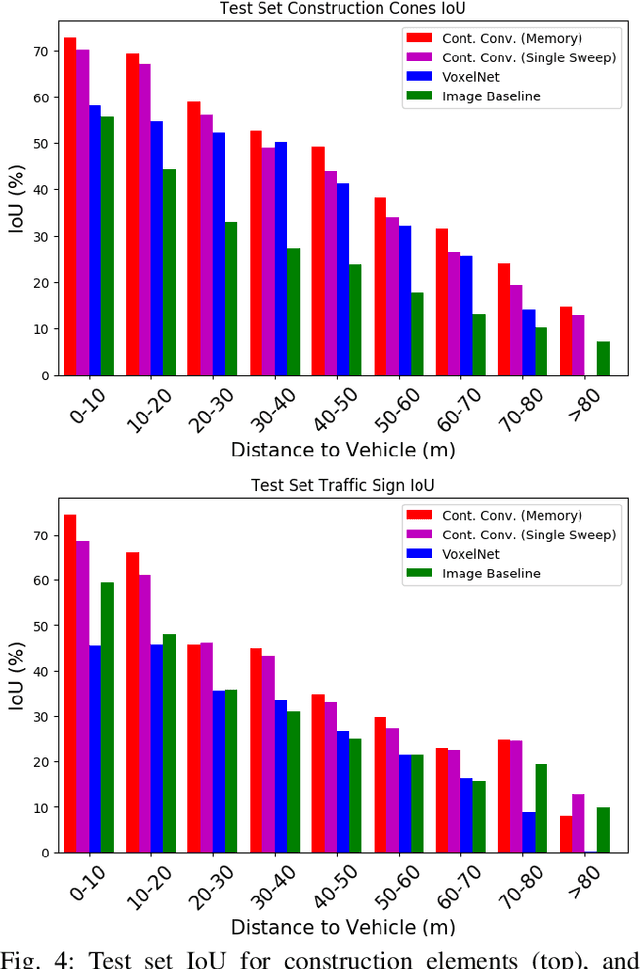

In this paper, we introduce a non-parametric memory representation for spatio-temporal segmentation that captures the local space and time around an autonomous vehicle (AV). Our representation has three important properties: (i) it remembers what it has seen in the past, (ii) it reinforces and (iii) forgets its past beliefs based on new evidence. Reinforcing is important as the first time we see an element we might be uncertain, e.g, if the element is heavily occluded or at range. Forgetting is desirable, as otherwise false positives will make the self driving vehicle behave erratically. Our process is informed by 3D reasoning, as occlusion is key to distinguishing between the desire to forget and to remember. We show how our method can be used as an online component to complement static world representations such as HD maps by detecting and remembering changes that should be superimposed on top of this static view due to such events.
Deep Structured Reactive Planning
Jan 18, 2021
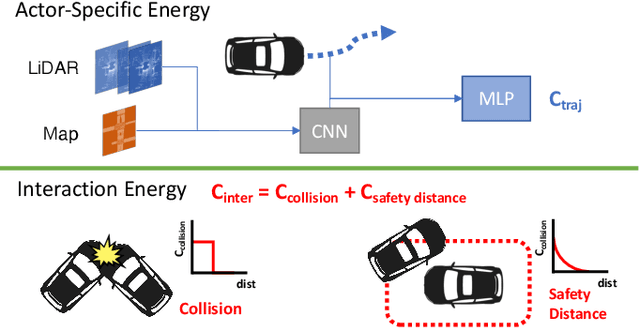

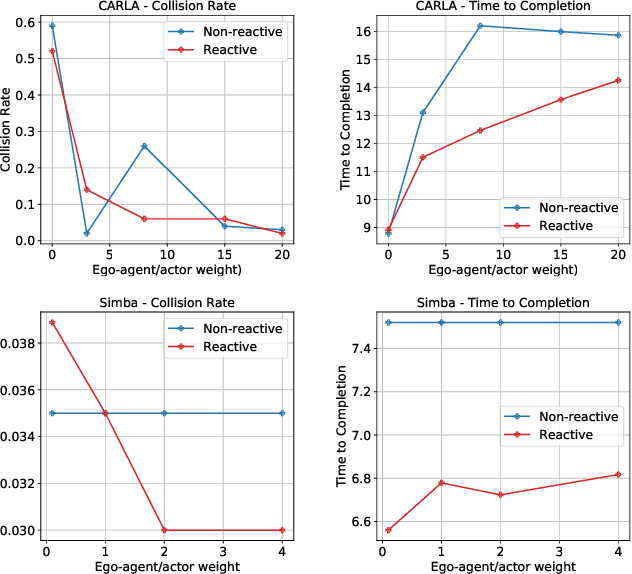
An intelligent agent operating in the real-world must balance achieving its goal with maintaining the safety and comfort of not only itself, but also other participants within the surrounding scene. This requires jointly reasoning about the behavior of other actors while deciding its own actions as these two processes are inherently intertwined - a vehicle will yield to us if we decide to proceed first at the intersection but will proceed first if we decide to yield. However, this is not captured in most self-driving pipelines, where planning follows prediction. In this paper we propose a novel data-driven, reactive planning objective which allows a self-driving vehicle to jointly reason about its own plans as well as how other actors will react to them. We formulate the problem as an energy-based deep structured model that is learned from observational data and encodes both the planning and prediction problems. Through simulations based on both real-world driving and synthetically generated dense traffic, we demonstrate that our reactive model outperforms a non-reactive variant in successfully completing highly complex maneuvers (lane merges/turns in traffic) faster, without trading off collision rate.
S3: Neural Shape, Skeleton, and Skinning Fields for 3D Human Modeling
Jan 17, 2021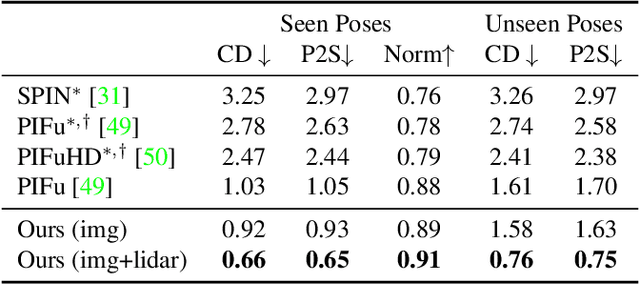
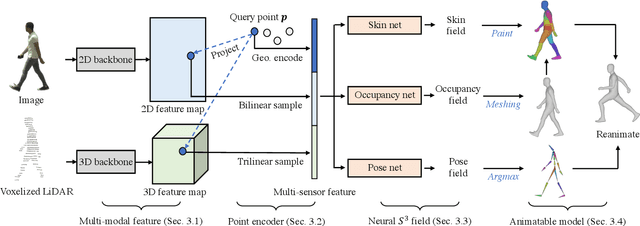
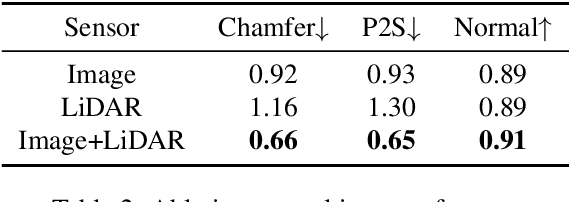
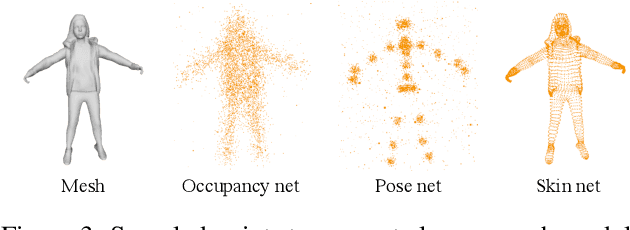
Constructing and animating humans is an important component for building virtual worlds in a wide variety of applications such as virtual reality or robotics testing in simulation. As there are exponentially many variations of humans with different shape, pose and clothing, it is critical to develop methods that can automatically reconstruct and animate humans at scale from real world data. Towards this goal, we represent the pedestrian's shape, pose and skinning weights as neural implicit functions that are directly learned from data. This representation enables us to handle a wide variety of different pedestrian shapes and poses without explicitly fitting a human parametric body model, allowing us to handle a wider range of human geometries and topologies. We demonstrate the effectiveness of our approach on various datasets and show that our reconstructions outperform existing state-of-the-art methods. Furthermore, our re-animation experiments show that we can generate 3D human animations at scale from a single RGB image (and/or an optional LiDAR sweep) as input.
Diverse Complexity Measures for Dataset Curation in Self-driving
Jan 16, 2021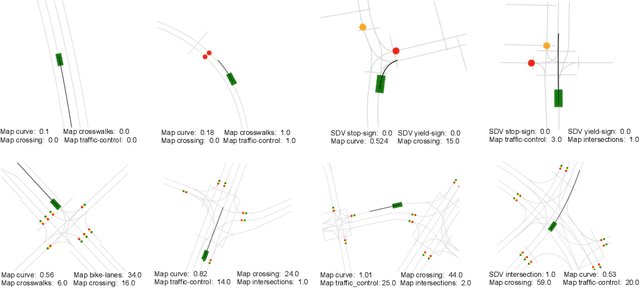
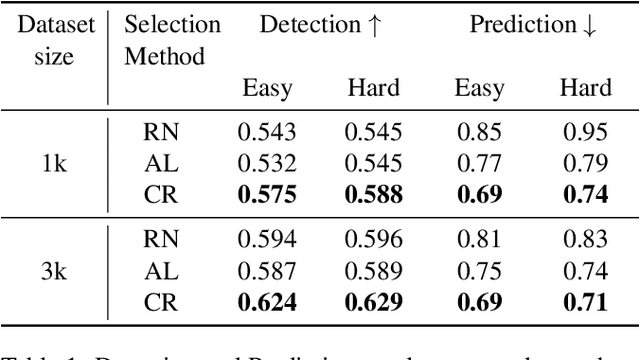

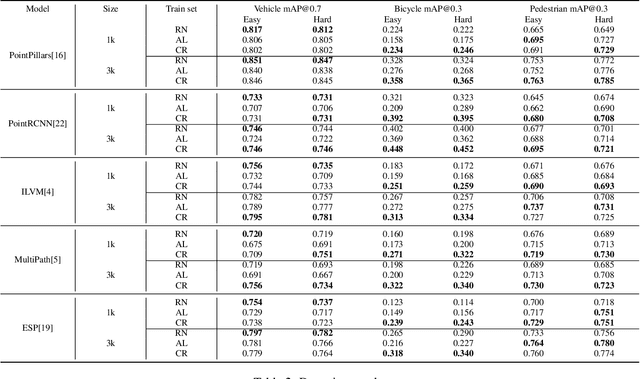
Modern self-driving autonomy systems heavily rely on deep learning. As a consequence, their performance is influenced significantly by the quality and richness of the training data. Data collecting platforms can generate many hours of raw data in a daily basis, however, it is not feasible to label everything. It is thus of key importance to have a mechanism to identify "what to label". Active learning approaches identify examples to label, but their interestingness is tied to a fixed model performing a particular task. These assumptions are not valid in self-driving, where we have to solve a diverse set of tasks (i.e., perception, and motion forecasting) and our models evolve over time frequently. In this paper we introduce a novel approach and propose a new data selection method that exploits a diverse set of criteria that quantize interestingness of traffic scenes. Our experiments on a wide range of tasks and models show that the proposed curation pipeline is able to select datasets that lead to better generalization and higher performance.
GeoSim: Photorealistic Image Simulation with Geometry-Aware Composition
Jan 16, 2021
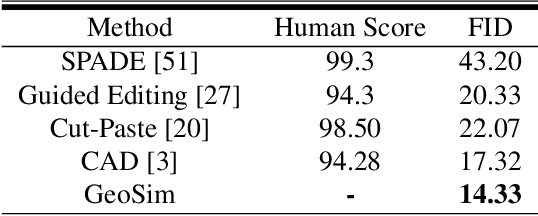
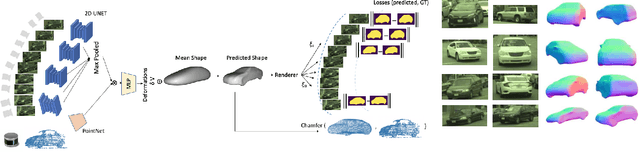

Scalable sensor simulation is an important yet challenging open problem for safety-critical domains such as self-driving. Current work in image simulation either fail to be photorealistic or do not model the 3D environment and the dynamic objects within, losing high-level control and physical realism. In this paper, we present GeoSim, a geometry-aware image composition process that synthesizes novel urban driving scenes by augmenting existing images with dynamic objects extracted from other scenes and rendered at novel poses. Towards this goal, we first build a diverse bank of 3D objects with both realistic geometry and appearance from sensor data. During simulation, we perform a novel geometry-aware simulation-by-composition procedure which 1) proposes plausible and realistic object placements into a given scene, 2) renders novel views of dynamic objects from the asset bank, and 3) composes and blends the rendered image segments. The resulting synthetic images are photorealistic, traffic-aware, and geometrically consistent, allowing image simulation to scale to complex use cases. We demonstrate two such important applications: long-range realistic video simulation across multiple camera sensors, and synthetic data generation for data augmentation on downstream segmentation tasks.
Universal Embeddings for Spatio-Temporal Tagging of Self-Driving Logs
Nov 12, 2020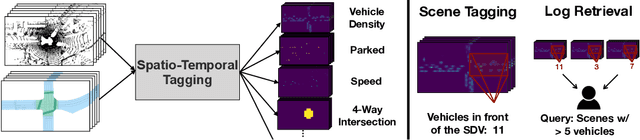
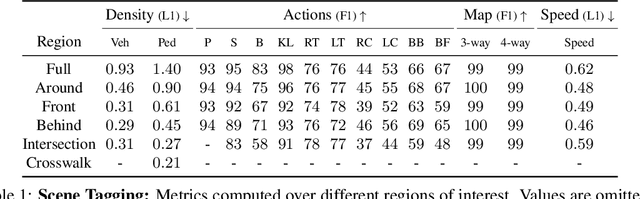
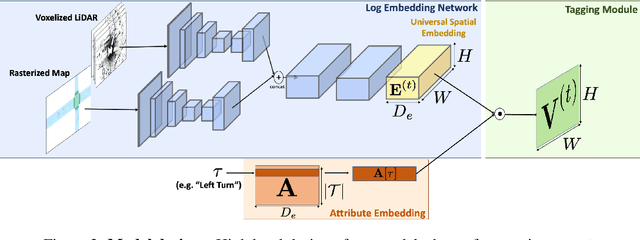

In this paper, we tackle the problem of spatio-temporal tagging of self-driving scenes from raw sensor data. Our approach learns a universal embedding for all tags, enabling efficient tagging of many attributes and faster learning of new attributes with limited data. Importantly, the embedding is spatio-temporally aware, allowing the model to naturally output spatio-temporal tag values. Values can then be pooled over arbitrary regions, in order to, for example, compute the pedestrian density in front of the SDV, or determine if a car is blocking another car at a 4-way intersection. We demonstrate the effectiveness of our approach on a new large scale self-driving dataset, SDVScenes, containing 15 attributes relating to vehicle and pedestrian density, the actions of each actor, the speed of each actor, interactions between actors, and the topology of the road map.
Hierarchical Verification for Adversarial Robustness
Jul 23, 2020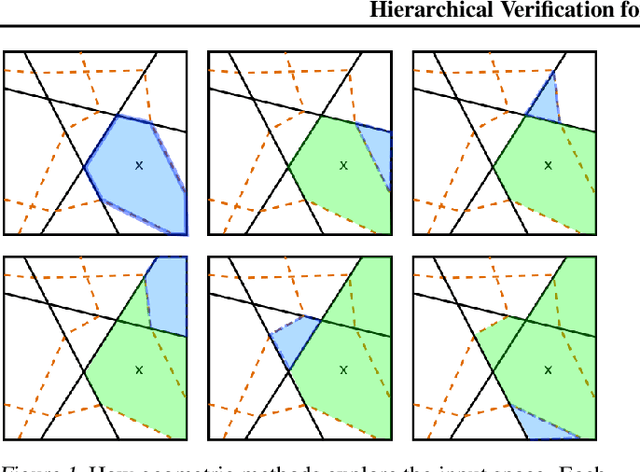
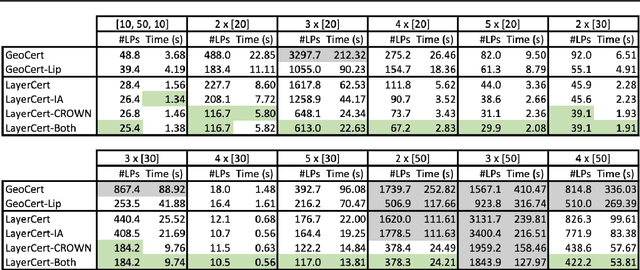
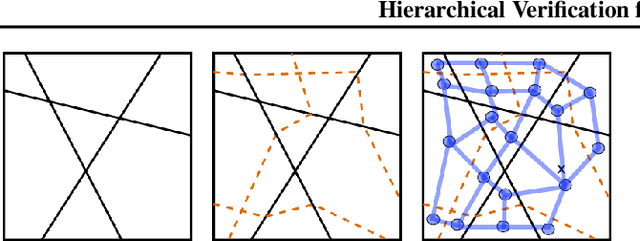
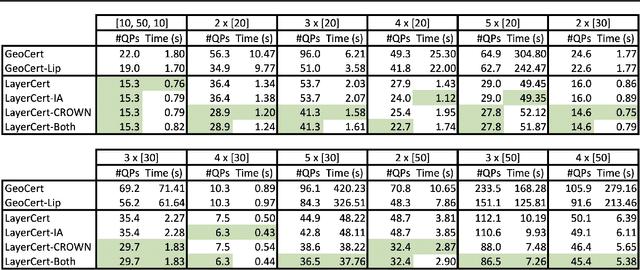
We introduce a new framework for the exact point-wise $\ell_p$ robustness verification problem that exploits the layer-wise geometric structure of deep feed-forward networks with rectified linear activations (ReLU networks). The activation regions of the network partition the input space, and one can verify the $\ell_p$ robustness around a point by checking all the activation regions within the desired radius. The GeoCert algorithm (Jordan et al., NeurIPS 2019) treats this partition as a generic polyhedral complex in order to detect which region to check next. In contrast, our LayerCert framework considers the \emph{nested hyperplane arrangement} structure induced by the layers of the ReLU network and explores regions in a hierarchical manner. We show that, under certain conditions on the algorithm parameters, LayerCert provably reduces the number and size of the convex programs that one needs to solve compared to GeoCert. Furthermore, our LayerCert framework allows the incorporation of lower bounding routines based on convex relaxations to further improve performance. Experimental results demonstrate that LayerCert can significantly reduce both the number of convex programs solved and the running time over the state-of-the-art.