 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFOMO-3D: Using Vision Foundation Models for Long-Tailed 3D Object Detection
Mar 09, 2026In order to navigate complex traffic environments, self-driving vehicles must recognize many semantic classes pertaining to vulnerable road users or traffic control devices. However, many safety-critical objects (e.g., construction worker) appear infrequently in nominal traffic conditions, leading to a severe shortage of training examples from driving data alone. Recent vision foundation models, which are trained on a large corpus of data, can serve as a good source of external prior knowledge to improve generalization. We propose FOMO-3D, the first multi-modal 3D detector to leverage vision foundation models for long-tailed 3D detection. Specifically, FOMO-3D exploits rich semantic and depth priors from OWLv2 and Metric3Dv2 within a two-stage detection paradigm that first generates proposals with a LiDAR-based branch and a novel camera-based branch, and refines them with attention especially to image features from OWL. Evaluations on real-world driving data show that using rich priors from vision foundation models with careful multi-modal fusion designs leads to large gains for long-tailed 3D detection. Project website is at https://waabi.ai/fomo3d/.
Adv3D: Generating Safety-Critical 3D Objects through Closed-Loop Simulation
Nov 02, 2023



Self-driving vehicles (SDVs) must be rigorously tested on a wide range of scenarios to ensure safe deployment. The industry typically relies on closed-loop simulation to evaluate how the SDV interacts on a corpus of synthetic and real scenarios and verify it performs properly. However, they primarily only test the system's motion planning module, and only consider behavior variations. It is key to evaluate the full autonomy system in closed-loop, and to understand how variations in sensor data based on scene appearance, such as the shape of actors, affect system performance. In this paper, we propose a framework, Adv3D, that takes real world scenarios and performs closed-loop sensor simulation to evaluate autonomy performance, and finds vehicle shapes that make the scenario more challenging, resulting in autonomy failures and uncomfortable SDV maneuvers. Unlike prior works that add contrived adversarial shapes to vehicle roof-tops or roadside to harm perception only, we optimize a low-dimensional shape representation to modify the vehicle shape itself in a realistic manner to degrade autonomy performance (e.g., perception, prediction, and motion planning). Moreover, we find that the shape variations found with Adv3D optimized in closed-loop are much more effective than those in open-loop, demonstrating the importance of finding scene appearance variations that affect autonomy in the interactive setting.
Learning Realistic Traffic Agents in Closed-loop
Nov 02, 2023Realistic traffic simulation is crucial for developing self-driving software in a safe and scalable manner prior to real-world deployment. Typically, imitation learning (IL) is used to learn human-like traffic agents directly from real-world observations collected offline, but without explicit specification of traffic rules, agents trained from IL alone frequently display unrealistic infractions like collisions and driving off the road. This problem is exacerbated in out-of-distribution and long-tail scenarios. On the other hand, reinforcement learning (RL) can train traffic agents to avoid infractions, but using RL alone results in unhuman-like driving behaviors. We propose Reinforcing Traffic Rules (RTR), a holistic closed-loop learning objective to match expert demonstrations under a traffic compliance constraint, which naturally gives rise to a joint IL + RL approach, obtaining the best of both worlds. Our method learns in closed-loop simulations of both nominal scenarios from real-world datasets as well as procedurally generated long-tail scenarios. Our experiments show that RTR learns more realistic and generalizable traffic simulation policies, achieving significantly better tradeoffs between human-like driving and traffic compliance in both nominal and long-tail scenarios. Moreover, when used as a data generation tool for training prediction models, our learned traffic policy leads to considerably improved downstream prediction metrics compared to baseline traffic agents. For more information, visit the project website: https://waabi.ai/rtr
3D Reasoning for Unsupervised Anomaly Detection in Pediatric WbMRI
Mar 24, 2021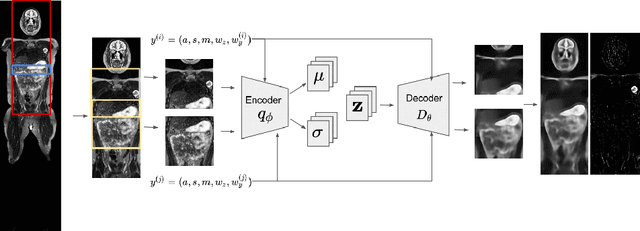
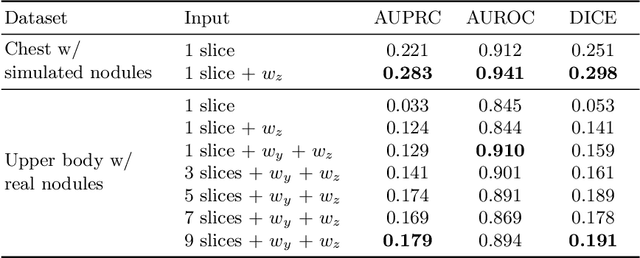

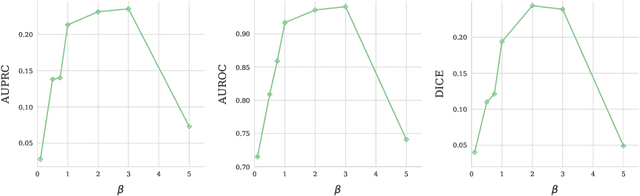
Modern deep unsupervised learning methods have shown great promise for detecting diseases across a variety of medical imaging modalities. While previous generative modeling approaches successfully perform anomaly detection by learning the distribution of healthy 2D image slices, they process such slices independently and ignore the fact that they are correlated, all being sampled from a 3D volume. We show that incorporating the 3D context and processing whole-body MRI volumes is beneficial to distinguishing anomalies from their benign counterparts. In our work, we introduce a multi-channel sliding window generative model to perform lesion detection in whole-body MRI (wbMRI). Our experiments demonstrate that our proposed method significantly outperforms processing individual images in isolation and our ablations clearly show the importance of 3D reasoning. Moreover, our work also shows that it is beneficial to include additional patient-specific features to further improve anomaly detection in pediatric scans.
Exploring Adversarial Robustness of Multi-Sensor Perception Systems in Self Driving
Jan 26, 2021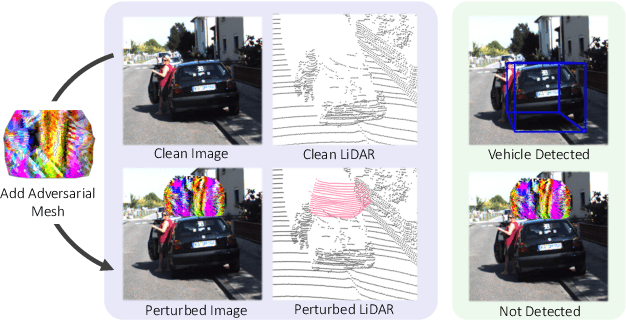
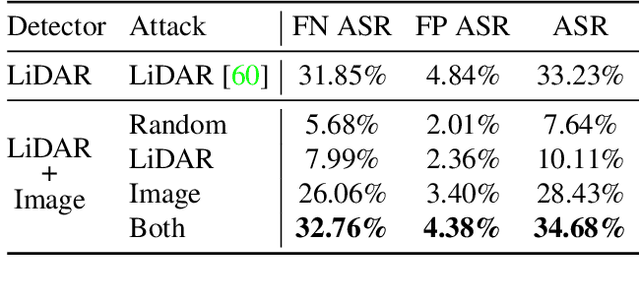
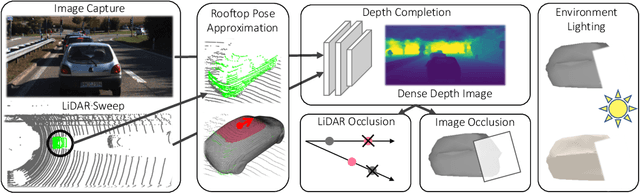
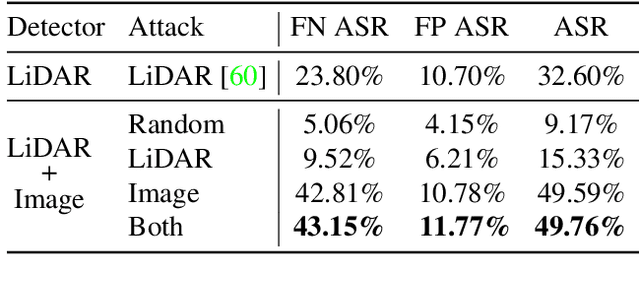
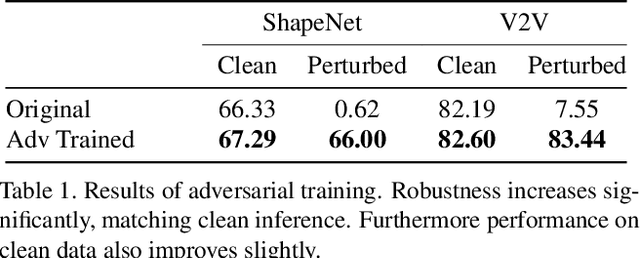
Modern self-driving perception systems have been shown to improve upon processing complementary inputs such as LiDAR with images. In isolation, 2D images have been found to be extremely vulnerable to adversarial attacks. Yet, there have been limited studies on the adversarial robustness of multi-modal models that fuse LiDAR features with image features. Furthermore, existing works do not consider physically realizable perturbations that are consistent across the input modalities. In this paper, we showcase practical susceptibilities of multi-sensor detection by placing an adversarial object on top of a host vehicle. We focus on physically realizable and input-agnostic attacks as they are feasible to execute in practice, and show that a single universal adversary can hide different host vehicles from state-of-the-art multi-modal detectors. Our experiments demonstrate that successful attacks are primarily caused by easily corrupted image features. Furthermore, we find that in modern sensor fusion methods which project image features into 3D, adversarial attacks can exploit the projection process to generate false positives across distant regions in 3D. Towards more robust multi-modal perception systems, we show that adversarial training with feature denoising can boost robustness to such attacks significantly. However, we find that standard adversarial defenses still struggle to prevent false positives which are also caused by inaccurate associations between 3D LiDAR points and 2D pixels.
Adversarial Attacks On Multi-Agent Communication
Jan 17, 2021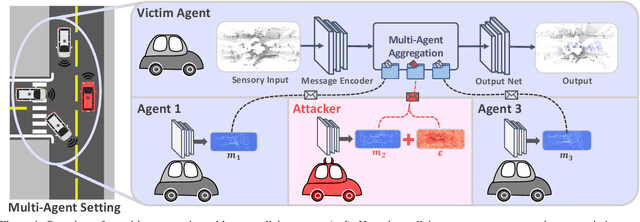
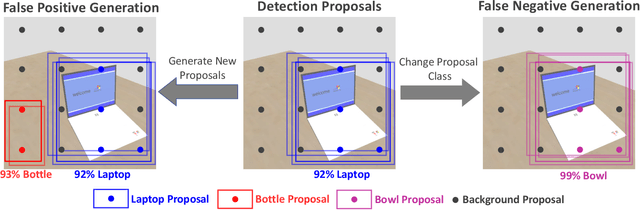
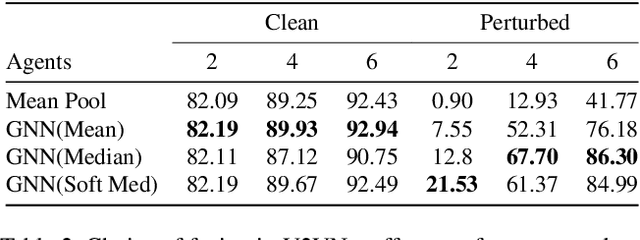
Growing at a very fast pace, modern autonomous systems will soon be deployed at scale, opening up the possibility for cooperative multi-agent systems. By sharing information and distributing workloads, autonomous agents can better perform their tasks and enjoy improved computation efficiency. However, such advantages rely heavily on communication channels which have been shown to be vulnerable to security breaches. Thus, communication can be compromised to execute adversarial attacks on deep learning models which are widely employed in modern systems. In this paper, we explore such adversarial attacks in a novel multi-agent setting where agents communicate by sharing learned intermediate representations. We observe that an indistinguishable adversarial message can severely degrade performance, but becomes weaker as the number of benign agents increase. Furthermore, we show that transfer attacks are more difficult in this setting when compared to directly perturbing the inputs, as it is necessary to align the distribution of communication messages with domain adaptation. Finally, we show that low-budget online attacks can be achieved by exploiting the temporal consistency of streaming sensory inputs.
Diverse Complexity Measures for Dataset Curation in Self-driving
Jan 16, 2021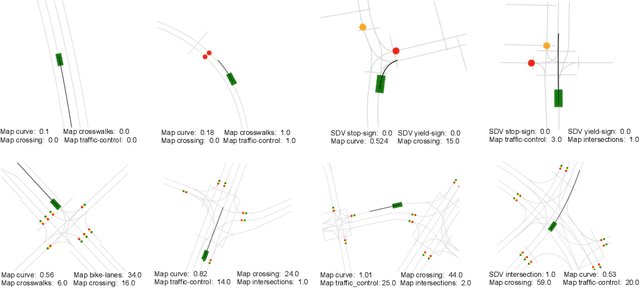
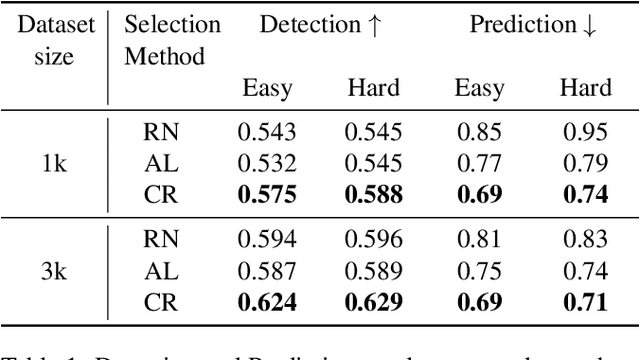

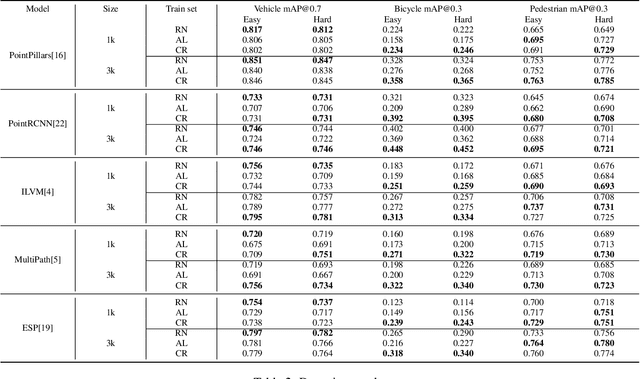
Modern self-driving autonomy systems heavily rely on deep learning. As a consequence, their performance is influenced significantly by the quality and richness of the training data. Data collecting platforms can generate many hours of raw data in a daily basis, however, it is not feasible to label everything. It is thus of key importance to have a mechanism to identify "what to label". Active learning approaches identify examples to label, but their interestingness is tied to a fixed model performing a particular task. These assumptions are not valid in self-driving, where we have to solve a diverse set of tasks (i.e., perception, and motion forecasting) and our models evolve over time frequently. In this paper we introduce a novel approach and propose a new data selection method that exploits a diverse set of criteria that quantize interestingness of traffic scenes. Our experiments on a wide range of tasks and models show that the proposed curation pipeline is able to select datasets that lead to better generalization and higher performance.
AdvSim: Generating Safety-Critical Scenarios for Self-Driving Vehicles
Jan 16, 2021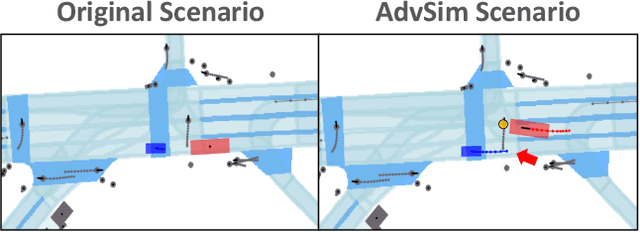
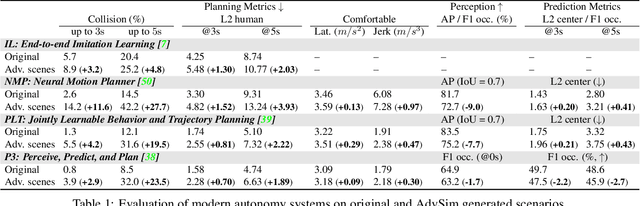

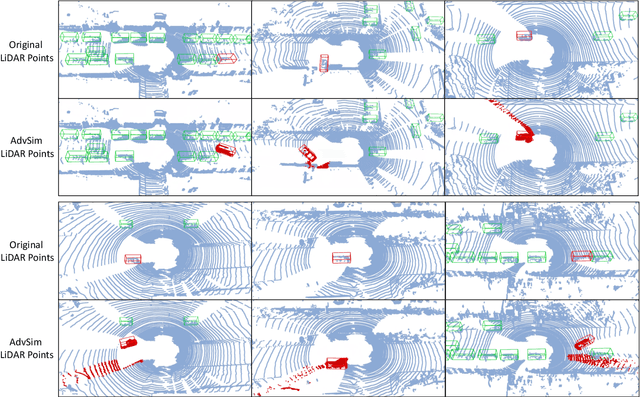
As self-driving systems become better, simulating scenarios where the autonomy stack is likely to fail becomes of key importance. Traditionally, those scenarios are generated for a few scenes with respect to the planning module that takes ground-truth actor states as input. This does not scale and cannot identify all possible autonomy failures, such as perception failures due to occlusion. In this paper, we propose AdvSim, an adversarial framework to generate safety-critical scenarios for any LiDAR-based autonomy system. Given an initial traffic scenario, AdvSim modifies the actors' trajectories in a physically plausible manner and updates the LiDAR sensor data to create realistic observations of the perturbed world. Importantly, by simulating directly from sensor data, we obtain adversarial scenarios that are safety-critical for the full autonomy stack. Our experiments show that our approach is general and can identify thousands of semantically meaningful safety-critical scenarios for a wide range of modern self-driving systems. Furthermore, we show that the robustness and safety of these autonomy systems can be further improved by training them with scenarios generated by AdvSim.
StrObe: Streaming Object Detection from LiDAR Packets
Nov 13, 2020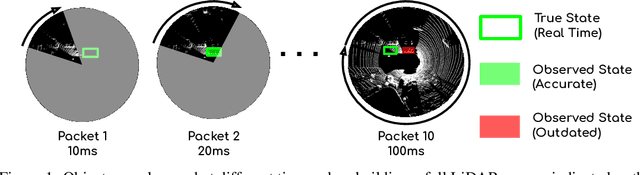

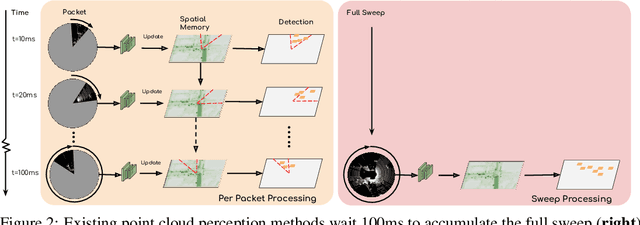
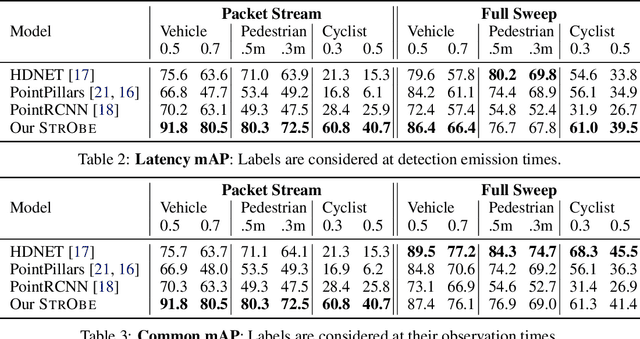
Many modern robotics systems employ LiDAR as their main sensing modality due to its geometrical richness. Rolling shutter LiDARs are particularly common, in which an array of lasers scans the scene from a rotating base. Points are emitted as a stream of packets, each covering a sector of the 360{\deg} coverage. Modern perception algorithms wait for the full sweep to be built before processing the data, which introduces an additional latency. For typical 10Hz LiDARs this will be 100ms. As a consequence, by the time an output is produced, it no longer accurately reflects the state of the world. This poses a challenge, as robotics applications require minimal reaction times, such that maneuvers can be quickly planned in the event of a safety-critical situation. In this paper we propose StrObe, a novel approach that minimizes latency by ingesting LiDAR packets and emitting a stream of detections without waiting for the full sweep to be built. StrObe reuses computations from previous packets and iteratively updates a latent spatial representation of the scene, which acts as a memory, as new evidence comes in, resulting in accurate low-latency perception. We demonstrate the effectiveness of our approach on a large scale real-world dataset, showing that StrObe far outperforms the state-of-the-art when latency is taken into account, and matches the performance in the traditional setting.
Learning to Communicate and Correct Pose Errors
Nov 10, 2020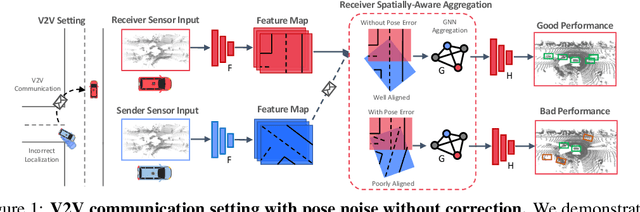
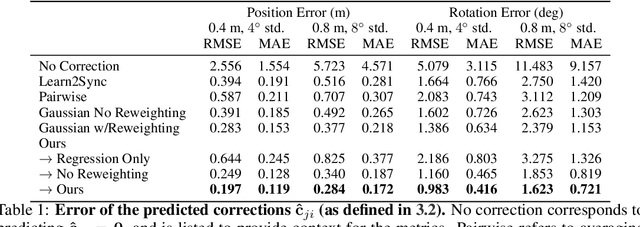
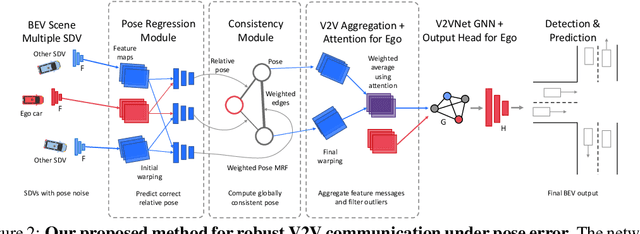
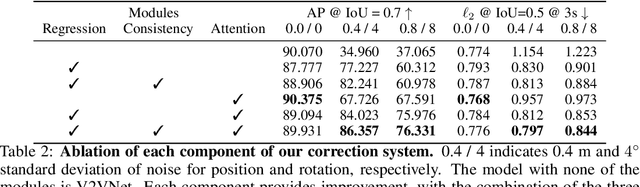
Learned communication makes multi-agent systems more effective by aggregating distributed information. However, it also exposes individual agents to the threat of erroneous messages they might receive. In this paper, we study the setting proposed in V2VNet, where nearby self-driving vehicles jointly perform object detection and motion forecasting in a cooperative manner. Despite a huge performance boost when the agents solve the task together, the gain is quickly diminished in the presence of pose noise since the communication relies on spatial transformations. Hence, we propose a novel neural reasoning framework that learns to communicate, to estimate potential errors, and finally, to reach a consensus about those errors. Experiments confirm that our proposed framework significantly improves the robustness of multi-agent self-driving perception and motion forecasting systems under realistic and severe localization noise.