 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParseBench: A Document Parsing Benchmark for AI Agents
Apr 09, 2026AI agents are changing the requirements for document parsing. What matters is \emph{semantic correctness}: parsed output must preserve the structure and meaning needed for autonomous decisions, including correct table structure, precise chart data, semantically meaningful formatting, and visual grounding. Existing benchmarks do not fully capture this setting for enterprise automation, relying on narrow document distributions and text-similarity metrics that miss agent-critical failures. We introduce \textbf{ParseBench}, a benchmark of ${\sim}2{,}000$ human-verified pages from enterprise documents spanning insurance, finance, and government, organized around five capability dimensions: tables, charts, content faithfulness, semantic formatting, and visual grounding. Across 14 methods spanning vision-language models, specialized document parsers, and LlamaParse, the benchmark reveals a fragmented capability landscape: no method is consistently strong across all five dimensions. LlamaParse Agentic achieves the highest overall score at \agenticoverall\%, and the benchmark highlights the remaining capability gaps across current systems. Dataset and evaluation code are available on \href{https://huggingface.co/datasets/llamaindex/ParseBench}{HuggingFace} and \href{https://github.com/run-llama/ParseBench}{GitHub}.
Learning Realistic Traffic Agents in Closed-loop
Nov 02, 2023Realistic traffic simulation is crucial for developing self-driving software in a safe and scalable manner prior to real-world deployment. Typically, imitation learning (IL) is used to learn human-like traffic agents directly from real-world observations collected offline, but without explicit specification of traffic rules, agents trained from IL alone frequently display unrealistic infractions like collisions and driving off the road. This problem is exacerbated in out-of-distribution and long-tail scenarios. On the other hand, reinforcement learning (RL) can train traffic agents to avoid infractions, but using RL alone results in unhuman-like driving behaviors. We propose Reinforcing Traffic Rules (RTR), a holistic closed-loop learning objective to match expert demonstrations under a traffic compliance constraint, which naturally gives rise to a joint IL + RL approach, obtaining the best of both worlds. Our method learns in closed-loop simulations of both nominal scenarios from real-world datasets as well as procedurally generated long-tail scenarios. Our experiments show that RTR learns more realistic and generalizable traffic simulation policies, achieving significantly better tradeoffs between human-like driving and traffic compliance in both nominal and long-tail scenarios. Moreover, when used as a data generation tool for training prediction models, our learned traffic policy leads to considerably improved downstream prediction metrics compared to baseline traffic agents. For more information, visit the project website: https://waabi.ai/rtr
GoRela: Go Relative for Viewpoint-Invariant Motion Forecasting
Nov 08, 2022The task of motion forecasting is critical for self-driving vehicles (SDVs) to be able to plan a safe maneuver. Towards this goal, modern approaches reason about the map, the agents' past trajectories and their interactions in order to produce accurate forecasts. The predominant approach has been to encode the map and other agents in the reference frame of each target agent. However, this approach is computationally expensive for multi-agent prediction as inference needs to be run for each agent. To tackle the scaling challenge, the solution thus far has been to encode all agents and the map in a shared coordinate frame (e.g., the SDV frame). However, this is sample inefficient and vulnerable to domain shift (e.g., when the SDV visits uncommon states). In contrast, in this paper, we propose an efficient shared encoding for all agents and the map without sacrificing accuracy or generalization. Towards this goal, we leverage pair-wise relative positional encodings to represent geometric relationships between the agents and the map elements in a heterogeneous spatial graph. This parameterization allows us to be invariant to scene viewpoint, and save online computation by re-using map embeddings computed offline. Our decoder is also viewpoint agnostic, predicting agent goals on the lane graph to enable diverse and context-aware multimodal prediction. We demonstrate the effectiveness of our approach on the urban Argoverse 2 benchmark as well as a novel highway dataset.
Deep Parametric Continuous Convolutional Neural Networks
Jan 17, 2021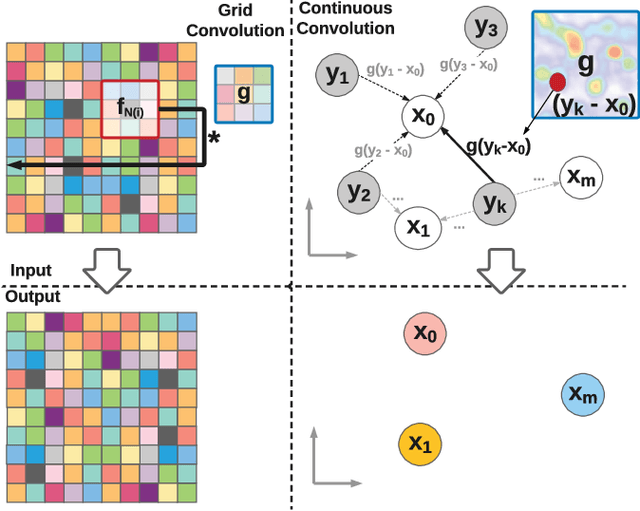

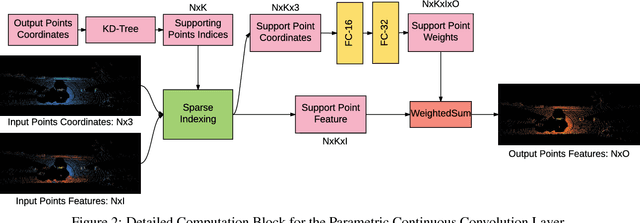
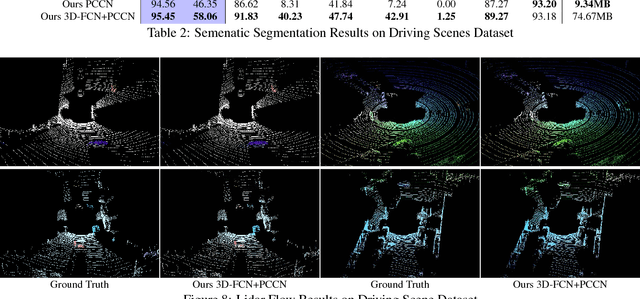
Standard convolutional neural networks assume a grid structured input is available and exploit discrete convolutions as their fundamental building blocks. This limits their applicability to many real-world applications. In this paper we propose Parametric Continuous Convolution, a new learnable operator that operates over non-grid structured data. The key idea is to exploit parameterized kernel functions that span the full continuous vector space. This generalization allows us to learn over arbitrary data structures as long as their support relationship is computable. Our experiments show significant improvement over the state-of-the-art in point cloud segmentation of indoor and outdoor scenes, and lidar motion estimation of driving scenes.
End-to-end Interpretable Neural Motion Planner
Jan 17, 2021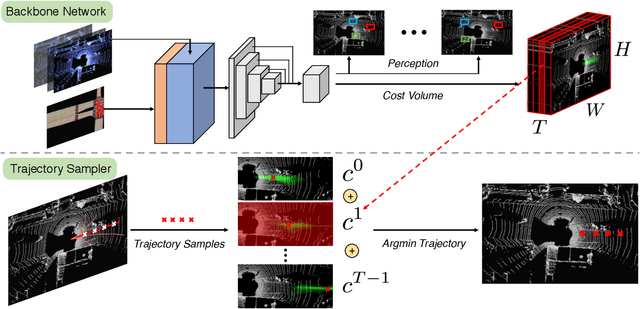
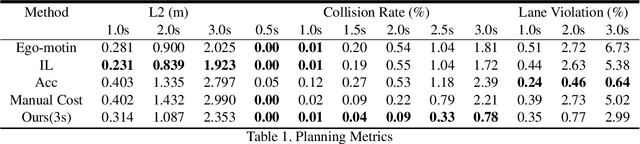
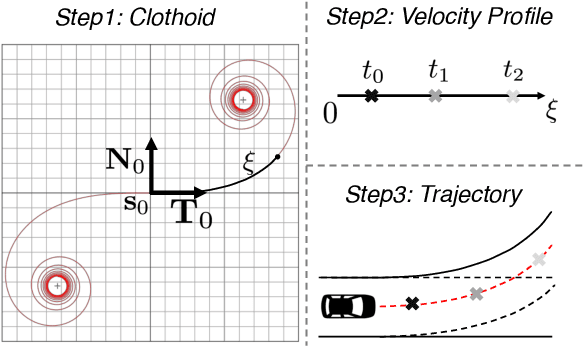

In this paper, we propose a neural motion planner (NMP) for learning to drive autonomously in complex urban scenarios that include traffic-light handling, yielding, and interactions with multiple road-users. Towards this goal, we design a holistic model that takes as input raw LIDAR data and a HD map and produces interpretable intermediate representations in the form of 3D detections and their future trajectories, as well as a cost volume defining the goodness of each position that the self-driving car can take within the planning horizon. We then sample a set of diverse physically possible trajectories and choose the one with the minimum learned cost. Importantly, our cost volume is able to naturally capture multi-modality. We demonstrate the effectiveness of our approach in real-world driving data captured in several cities in North America. Our experiments show that the learned cost volume can generate safer planning than all the baselines.
TrafficSim: Learning to Simulate Realistic Multi-Agent Behaviors
Jan 17, 2021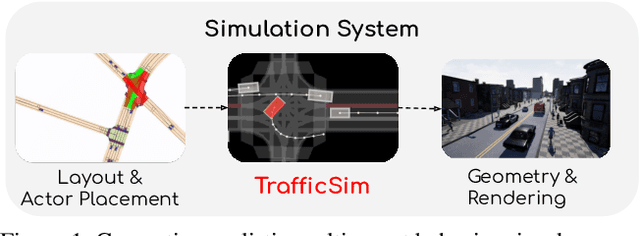
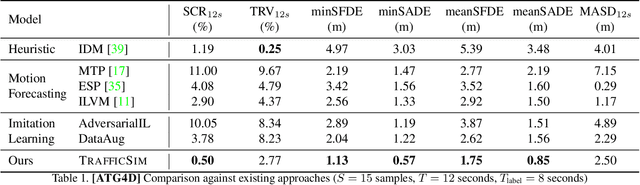

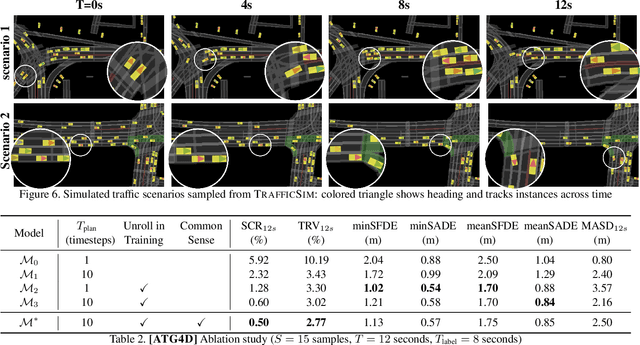
Simulation has the potential to massively scale evaluation of self-driving systems enabling rapid development as well as safe deployment. To close the gap between simulation and the real world, we need to simulate realistic multi-agent behaviors. Existing simulation environments rely on heuristic-based models that directly encode traffic rules, which cannot capture irregular maneuvers (e.g., nudging, U-turns) and complex interactions (e.g., yielding, merging). In contrast, we leverage real-world data to learn directly from human demonstration and thus capture a more diverse set of actor behaviors. To this end, we propose TrafficSim, a multi-agent behavior model for realistic traffic simulation. In particular, we leverage an implicit latent variable model to parameterize a joint actor policy that generates socially-consistent plans for all actors in the scene jointly. To learn a robust policy amenable for long horizon simulation, we unroll the policy in training and optimize through the fully differentiable simulation across time. Our learning objective incorporates both human demonstrations as well as common sense. We show TrafficSim generates significantly more realistic and diverse traffic scenarios as compared to a diverse set of baselines. Notably, we can exploit trajectories generated by TrafficSim as effective data augmentation for training better motion planner.
StrObe: Streaming Object Detection from LiDAR Packets
Nov 13, 2020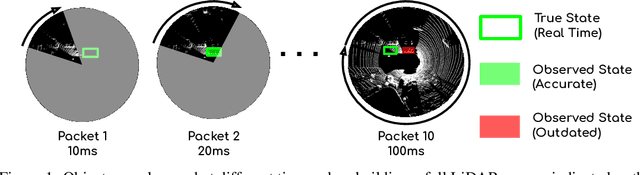

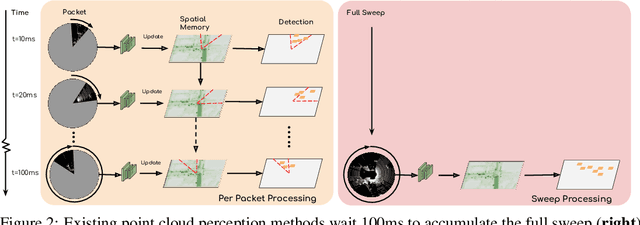
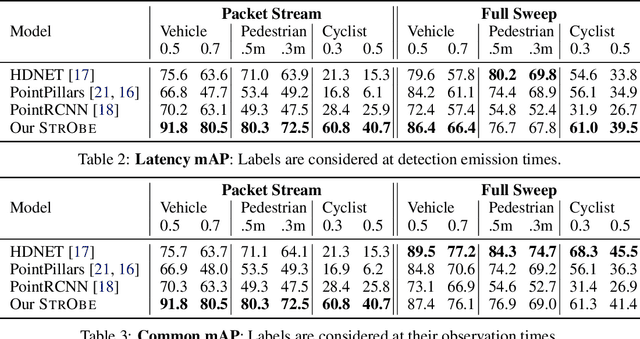
Many modern robotics systems employ LiDAR as their main sensing modality due to its geometrical richness. Rolling shutter LiDARs are particularly common, in which an array of lasers scans the scene from a rotating base. Points are emitted as a stream of packets, each covering a sector of the 360{\deg} coverage. Modern perception algorithms wait for the full sweep to be built before processing the data, which introduces an additional latency. For typical 10Hz LiDARs this will be 100ms. As a consequence, by the time an output is produced, it no longer accurately reflects the state of the world. This poses a challenge, as robotics applications require minimal reaction times, such that maneuvers can be quickly planned in the event of a safety-critical situation. In this paper we propose StrObe, a novel approach that minimizes latency by ingesting LiDAR packets and emitting a stream of detections without waiting for the full sweep to be built. StrObe reuses computations from previous packets and iteratively updates a latent spatial representation of the scene, which acts as a memory, as new evidence comes in, resulting in accurate low-latency perception. We demonstrate the effectiveness of our approach on a large scale real-world dataset, showing that StrObe far outperforms the state-of-the-art when latency is taken into account, and matches the performance in the traditional setting.
Implicit Latent Variable Model for Scene-Consistent Motion Forecasting
Jul 23, 2020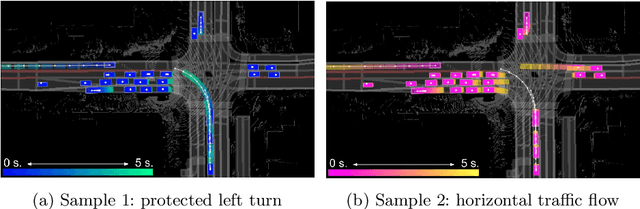
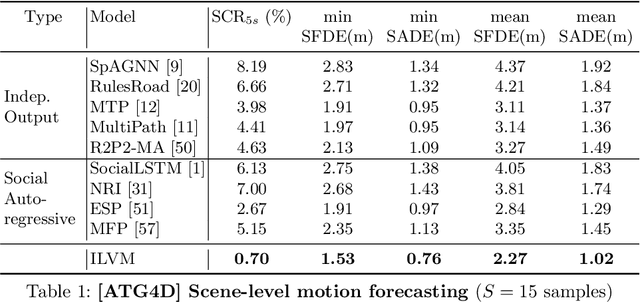

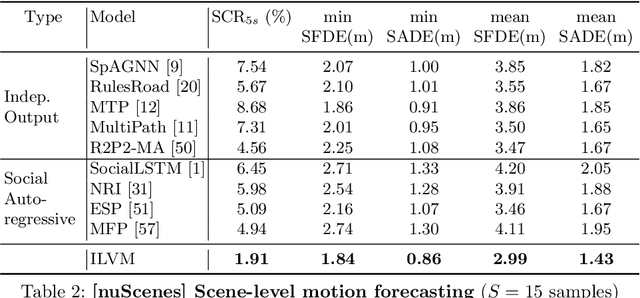
In order to plan a safe maneuver an autonomous vehicle must accurately perceive its environment, and understand the interactions among traffic participants. In this paper, we aim to learn scene-consistent motion forecasts of complex urban traffic directly from sensor data. In particular, we propose to characterize the joint distribution over future trajectories via an implicit latent variable model. We model the scene as an interaction graph and employ powerful graph neural networks to learn a distributed latent representation of the scene. Coupled with a deterministic decoder, we obtain trajectory samples that are consistent across traffic participants, achieving state-of-the-art results in motion forecasting and interaction understanding. Last but not least, we demonstrate that our motion forecasts result in safer and more comfortable motion planning.
The Importance of Prior Knowledge in Precise Multimodal Prediction
Jun 04, 2020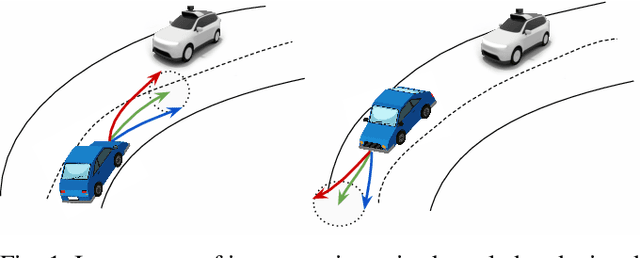
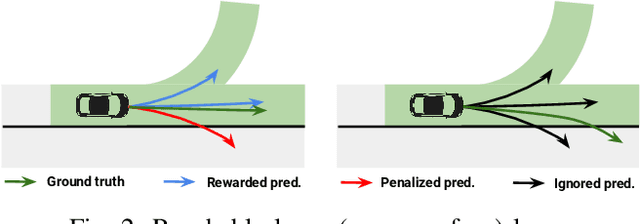
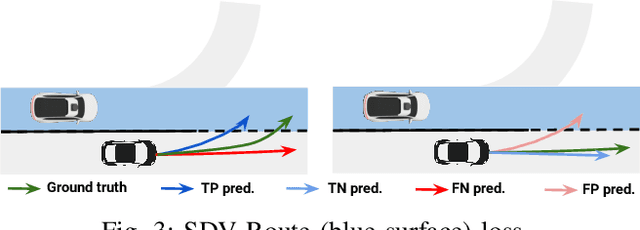

Roads have well defined geometries, topologies, and traffic rules. While this has been widely exploited in motion planning methods to produce maneuvers that obey the law, little work has been devoted to utilize these priors in perception and motion forecasting methods. In this paper we propose to incorporate these structured priors as a loss function. In contrast to imposing hard constraints, this approach allows the model to handle non-compliant maneuvers when those happen in the real world. Safe motion planning is the end goal, and thus a probabilistic characterization of the possible future developments of the scene is key to choose the plan with the lowest expected cost. Towards this goal, we design a framework that leverages REINFORCE to incorporate non-differentiable priors over sample trajectories from a probabilistic model, thus optimizing the whole distribution. We demonstrate the effectiveness of our approach on real-world self-driving datasets containing complex road topologies and multi-agent interactions. Our motion forecasts not only exhibit better precision and map understanding, but most importantly result in safer motion plans taken by our self-driving vehicle. We emphasize that despite the importance of this evaluation, it has been often overlooked by previous perception and motion forecasting works.