 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOrcaRouter: A Production-Oriented LLM Router with Hybrid Offline-Online Learning
May 29, 2026The rapid development of large language models, each with distinct capabilities and inference costs, raises a practical deployment question: given an incoming request, which model should handle it? We present OrcaRouter, a production-oriented LLM router that combines a LinUCB-based contextual bandit over lexical and sentence-embedding features with a hybrid offline-online learning protocol. Offline, OrcaRouter obtains full-information feedback by evaluating each candidate model on a curated set of routing prompts, yielding a reward matrix used to fit one ridge regressor per arm. At deployment time, it initializes from these parameters and can optionally continue learning from bandit feedback, updating only the selected model's arm after observing its reward. At the time of our RouterArena submission (May 20, 2026), OrcaRouter-Adaptive ranked second on the public RouterArena leaderboard with an arena score of 72.08, achieving 75.54% accuracy at a cost of USD 1.00 per 1,000 queries.
Conditional Flow-VAE for Safety-Critical Traffic Scenario Generation
May 06, 2026Safety-critical scenarios are essential for the development of autonomous vehicles (AVs) but are rare in real-world driving data. While simulation offers a way to generate such scenarios, manually designed test cases lack scalability, and adversarial optimization often produces unrealistic behaviors. In this work, we introduce a conditional latent flow matching approach for scalable and realistic safety-critical scenario generation. Our method uses distribution matching to transform nominal scenes into safety-critical rollouts. Furthermore, we demonstrate that incorporating both simulation and real-world data enables our framework to efficiently generate diverse, data-driven scenarios. Experimental results highlight that our approach is able to more consistently and realistically generate novel safety-critical scenarios, making it a valuable tool for training and benchmarking AV systems.
Efficient Equivariant Transformer for Self-Driving Agent Modeling
Apr 01, 2026Accurately modeling agent behaviors is an important task in self-driving. It is also a task with many symmetries, such as equivariance to the order of agents and objects in the scene or equivariance to arbitrary roto-translations of the entire scene as a whole; i.e., SE(2)-equivariance. The transformer architecture is a ubiquitous tool for modeling these symmetries. While standard self-attention is inherently permutation equivariant, explicit pairwise relative positional encodings have been the standard for introducing SE(2)-equivariance. However, this approach introduces an additional cost that is quadratic in the number of agents, limiting its scalability to larger scenes and batch sizes. In this work, we propose DriveGATr, a novel transformer-based architecture for agent modeling that achieves SE(2)-equivariance without the computational cost of existing methods. Inspired by recent advances in geometric deep learning, DriveGATr encodes scene elements as multivectors in the 2D projective geometric algebra $\mathbb{R}^*_{2,0,1}$ and processes them with a stack of equivariant transformer blocks. Crucially, DriveGATr models geometric relationships using standard attention between multivectors, eliminating the need for costly explicit pairwise relative positional encodings. Experiments on the Waymo Open Motion Dataset demonstrate that DriveGATr is comparable to the state-of-the-art in traffic simulation and establishes a superior Pareto front for performance vs computational cost.
Learning to Drive via Asymmetric Self-Play
Sep 26, 2024
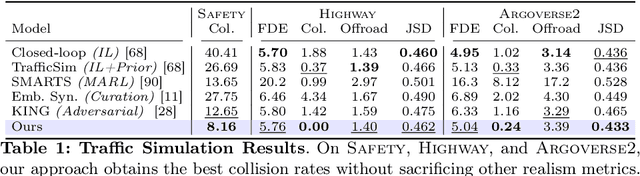
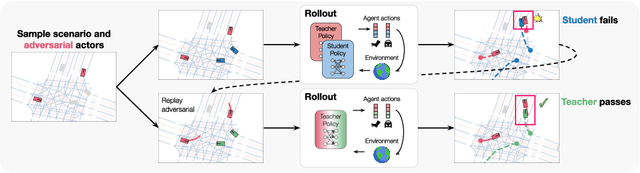
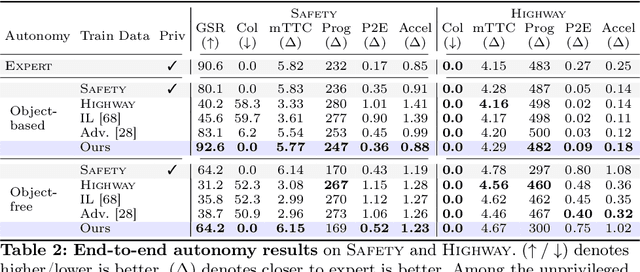
Large-scale data is crucial for learning realistic and capable driving policies. However, it can be impractical to rely on scaling datasets with real data alone. The majority of driving data is uninteresting, and deliberately collecting new long-tail scenarios is expensive and unsafe. We propose asymmetric self-play to scale beyond real data with additional challenging, solvable, and realistic synthetic scenarios. Our approach pairs a teacher that learns to generate scenarios it can solve but the student cannot, with a student that learns to solve them. When applied to traffic simulation, we learn realistic policies with significantly fewer collisions in both nominal and long-tail scenarios. Our policies further zero-shot transfer to generate training data for end-to-end autonomy, significantly outperforming state-of-the-art adversarial approaches, or using real data alone. For more information, visit https://waabi.ai/selfplay .
Unraveling Attacks in Machine Learning-based IoT Ecosystems: A Survey and the Open Libraries Behind Them
Jan 27, 2024
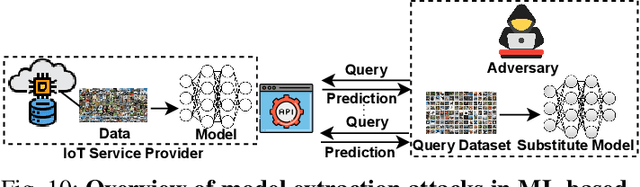
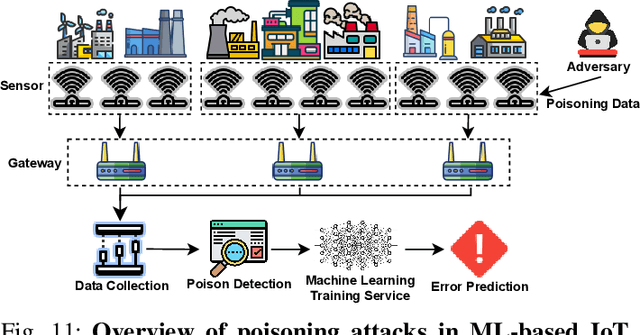
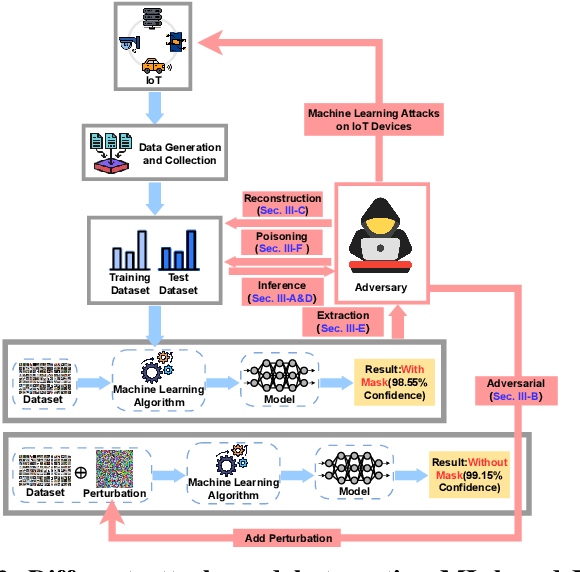
The advent of the Internet of Things (IoT) has brought forth an era of unprecedented connectivity, with an estimated 80 billion smart devices expected to be in operation by the end of 2025. These devices facilitate a multitude of smart applications, enhancing the quality of life and efficiency across various domains. Machine Learning (ML) serves as a crucial technology, not only for analyzing IoT-generated data but also for diverse applications within the IoT ecosystem. For instance, ML finds utility in IoT device recognition, anomaly detection, and even in uncovering malicious activities. This paper embarks on a comprehensive exploration of the security threats arising from ML's integration into various facets of IoT, spanning various attack types including membership inference, adversarial evasion, reconstruction, property inference, model extraction, and poisoning attacks. Unlike previous studies, our work offers a holistic perspective, categorizing threats based on criteria such as adversary models, attack targets, and key security attributes (confidentiality, availability, and integrity). We delve into the underlying techniques of ML attacks in IoT environment, providing a critical evaluation of their mechanisms and impacts. Furthermore, our research thoroughly assesses 65 libraries, both author-contributed and third-party, evaluating their role in safeguarding model and data privacy. We emphasize the availability and usability of these libraries, aiming to arm the community with the necessary tools to bolster their defenses against the evolving threat landscape. Through our comprehensive review and analysis, this paper seeks to contribute to the ongoing discourse on ML-based IoT security, offering valuable insights and practical solutions to secure ML models and data in the rapidly expanding field of artificial intelligence in IoT.
Learning Realistic Traffic Agents in Closed-loop
Nov 02, 2023Realistic traffic simulation is crucial for developing self-driving software in a safe and scalable manner prior to real-world deployment. Typically, imitation learning (IL) is used to learn human-like traffic agents directly from real-world observations collected offline, but without explicit specification of traffic rules, agents trained from IL alone frequently display unrealistic infractions like collisions and driving off the road. This problem is exacerbated in out-of-distribution and long-tail scenarios. On the other hand, reinforcement learning (RL) can train traffic agents to avoid infractions, but using RL alone results in unhuman-like driving behaviors. We propose Reinforcing Traffic Rules (RTR), a holistic closed-loop learning objective to match expert demonstrations under a traffic compliance constraint, which naturally gives rise to a joint IL + RL approach, obtaining the best of both worlds. Our method learns in closed-loop simulations of both nominal scenarios from real-world datasets as well as procedurally generated long-tail scenarios. Our experiments show that RTR learns more realistic and generalizable traffic simulation policies, achieving significantly better tradeoffs between human-like driving and traffic compliance in both nominal and long-tail scenarios. Moreover, when used as a data generation tool for training prediction models, our learned traffic policy leads to considerably improved downstream prediction metrics compared to baseline traffic agents. For more information, visit the project website: https://waabi.ai/rtr
Rethinking Closed-loop Training for Autonomous Driving
Jun 27, 2023Recent advances in high-fidelity simulators have enabled closed-loop training of autonomous driving agents, potentially solving the distribution shift in training v.s. deployment and allowing training to be scaled both safely and cheaply. However, there is a lack of understanding of how to build effective training benchmarks for closed-loop training. In this work, we present the first empirical study which analyzes the effects of different training benchmark designs on the success of learning agents, such as how to design traffic scenarios and scale training environments. Furthermore, we show that many popular RL algorithms cannot achieve satisfactory performance in the context of autonomous driving, as they lack long-term planning and take an extremely long time to train. To address these issues, we propose trajectory value learning (TRAVL), an RL-based driving agent that performs planning with multistep look-ahead and exploits cheaply generated imagined data for efficient learning. Our experiments show that TRAVL can learn much faster and produce safer maneuvers compared to all the baselines. For more information, visit the project website: https://waabi.ai/research/travl
Graph HyperNetworks for Neural Architecture Search
Oct 12, 2018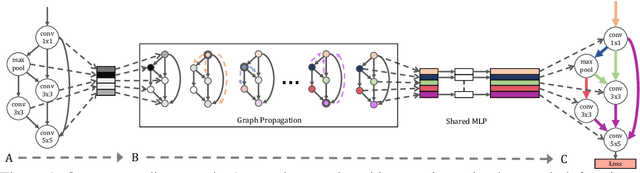
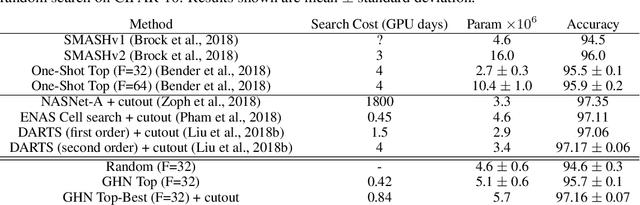
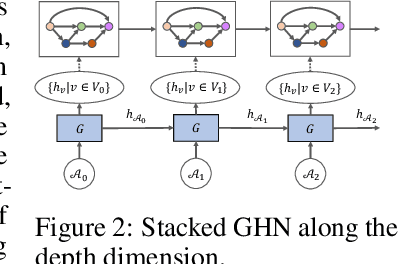
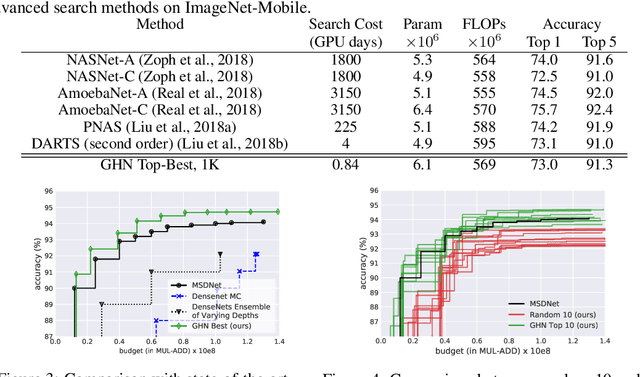
Neural architecture search (NAS) automatically finds the best task-specific neural network topology, outperforming many manual architecture designs. However, it can be prohibitively expensive as the search requires training thousands of different networks, while each can last for hours. In this work, we propose the Graph HyperNetwork (GHN) to amortize the search cost: given an architecture, it directly generates the weights by running inference on a graph neural network. GHNs model the topology of an architecture and therefore can predict network performance more accurately than regular hypernetworks and premature early stopping. To perform NAS, we randomly sample architectures and use the validation accuracy of networks with GHN generated weights as the surrogate search signal. GHNs are fast -- they can search nearly 10 times faster than other random search methods on CIFAR-10 and ImageNet. GHNs can be further extended to the anytime prediction setting, where they have found networks with better speed-accuracy tradeoff than the state-of-the-art manual designs.