 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpoCM: Exposure-Aware One-Step Generative Single-Image HDR Reconstruction
May 04, 2026Single-image HDR reconstruction aims to recover high dynamic range radiance from a single low dynamic range (LDR) input, but remains highly ill-posed due to detail saturation in over-exposed regions and noise amplification in under-exposed areas. While recent diffusion-based approaches offer powerful generative priors, they often overlook the exposure-dependent nature of the degradation and incur substantial computational costs from iterative sampling. To address these challenges, we propose ExpoCM, a novel one-step generative HDR reconstruction framework that reformulates HDR reconstruction as a Probability Flow ODE (PF-ODE) and constructs exposure-aware consistency trajectories via exposure-dependent perturbations. Specifically, a soft exposure mask is first constructed to separate the LDR image into over-, under-, and well-exposed regions. Based on this partition, region-conditioned consistency trajectories are designed to hallucinate saturated details, suppress noise in dark regions, and preserve reliable structures within a single, distillation-free inference step. To further enhance perceptual quality, we introduce an Exposure-guided Luminance-Chromaticity Loss in the CIE~$\text{L}^*\text{a}^*\text{b}^*$ space, which assigns exposure-aware weights to luminance and chromaticity components, effectively mitigating brightness bias and color drift. Extensive experiments on the HDR-REAL, HDR-EYE, and AIM2025 benchmarks demonstrate that ExpoCM achieves state-of-the-art fidelity and perceptual accuracy, while enabling over 400$\times$ and 20$\times$ faster inference compared to DDPM (1000 steps) and DDIM (50 steps), respectively.
Efficient Equivariant Transformer for Self-Driving Agent Modeling
Apr 01, 2026Accurately modeling agent behaviors is an important task in self-driving. It is also a task with many symmetries, such as equivariance to the order of agents and objects in the scene or equivariance to arbitrary roto-translations of the entire scene as a whole; i.e., SE(2)-equivariance. The transformer architecture is a ubiquitous tool for modeling these symmetries. While standard self-attention is inherently permutation equivariant, explicit pairwise relative positional encodings have been the standard for introducing SE(2)-equivariance. However, this approach introduces an additional cost that is quadratic in the number of agents, limiting its scalability to larger scenes and batch sizes. In this work, we propose DriveGATr, a novel transformer-based architecture for agent modeling that achieves SE(2)-equivariance without the computational cost of existing methods. Inspired by recent advances in geometric deep learning, DriveGATr encodes scene elements as multivectors in the 2D projective geometric algebra $\mathbb{R}^*_{2,0,1}$ and processes them with a stack of equivariant transformer blocks. Crucially, DriveGATr models geometric relationships using standard attention between multivectors, eliminating the need for costly explicit pairwise relative positional encodings. Experiments on the Waymo Open Motion Dataset demonstrate that DriveGATr is comparable to the state-of-the-art in traffic simulation and establishes a superior Pareto front for performance vs computational cost.
AGRI-Fidelity: Evaluating the Reliability of Listenable Explanations for Poultry Disease Detection
Mar 18, 2026Existing XAI metrics measure faithfulness for a single model, ignoring model multiplicity where near-optimal classifiers rely on different or spurious acoustic cues. In noisy farm environments, stationary artifacts such as ventilation noise can produce explanations that are faithful yet unreliable, as masking-based metrics fail to penalize redundant shortcuts. We propose AGRI-Fidelity, a reliability-oriented evaluation framework for listenable explanations in poultry disease detection without spatial ground truth. The method combines cross-model consensus with cyclic temporal permutation to construct null distributions and compute a False Discovery Rate (FDR), suppressing stationary artifacts while preserving time-localized bioacoustic markers. Across real and controlled datasets, AGRI-Fidelity effectively provides reliability-aware discrimination for all data points versus masking-based metrics.
X-MAP: eXplainable Misclassification Analysis and Profiling for Spam and Phishing Detection
Feb 17, 2026Misclassifications in spam and phishing detection are very harmful, as false negatives expose users to attacks while false positives degrade trust. Existing uncertainty-based detectors can flag potential errors, but possibly be deceived and offer limited interpretability. This paper presents X-MAP, an eXplainable Misclassification Analysis and Profilling framework that reveals topic-level semantic patterns behind model failures. X-MAP combines SHAP-based feature attributions with non-negative matrix factorization to build interpretable topic profiles for reliably classified spam/phishing and legitimate messages, and measures each message's deviation from these profiles using Jensen-Shannon divergence. Experiments on SMS and phishing datasets show that misclassified messages exhibit at least two times larger divergence than correctly classified ones. As a detector, X-MAP achieves up to 0.98 AUROC and lowers the false-rejection rate at 95% TRR to 0.089 on positive predictions. When used as a repair layer on base detectors, it recovers up to 97% of falsely rejected correct predictions with moderate leakage. These results demonstrate X-MAP's effectiveness and interpretability for improving spam and phishing detection.
Expert Knowledge-Guided Decision Calibration for Accurate Fine-Grained Tree Species Classification
Jan 23, 2026Accurate fine-grained tree species classification is critical for forest inventory and biodiversity monitoring. Existing methods predominantly focus on designing complex architectures to fit local data distributions. However, they often overlook the long-tailed distributions and high inter-class similarity inherent in limited data, thereby struggling to distinguish between few-shot or confusing categories. In the process of knowledge dissemination in the human world, individuals will actively seek expert assistance to transcend the limitations of local thinking. Inspired by this, we introduce an external "Domain Expert" and propose an Expert Knowledge-Guided Classification Decision Calibration Network (EKDC-Net) to overcome these challenges. Our framework addresses two core issues: expert knowledge extraction and utilization. Specifically, we first develop a Local Prior Guided Knowledge Extraction Module (LPKEM). By leveraging Class Activation Map (CAM) analysis, LPKEM guides the domain expert to focus exclusively on discriminative features essential for classification. Subsequently, to effectively integrate this knowledge, we design an Uncertainty-Guided Decision Calibration Module (UDCM). This module dynamically corrects the local model's decisions by considering both overall category uncertainty and instance-level prediction uncertainty. Furthermore, we present a large-scale classification dataset covering 102 tree species, named CU-Tree102 to address the issue of scarce diversity in current benchmarks. Experiments on three benchmark datasets demonstrate that our approach achieves state-of-the-art performance. Crucially, as a lightweight plug-and-play module, EKDC-Net improves backbone accuracy by 6.42% and precision by 11.46% using only 0.08M additional learnable parameters. The dataset, code, and pre-trained models are available at https://github.com/WHU-USI3DV/TreeCLS.
AnyView: Synthesizing Any Novel View in Dynamic Scenes
Jan 23, 2026Modern generative video models excel at producing convincing, high-quality outputs, but struggle to maintain multi-view and spatiotemporal consistency in highly dynamic real-world environments. In this work, we introduce \textbf{AnyView}, a diffusion-based video generation framework for \emph{dynamic view synthesis} with minimal inductive biases or geometric assumptions. We leverage multiple data sources with various levels of supervision, including monocular (2D), multi-view static (3D) and multi-view dynamic (4D) datasets, to train a generalist spatiotemporal implicit representation capable of producing zero-shot novel videos from arbitrary camera locations and trajectories. We evaluate AnyView on standard benchmarks, showing competitive results with the current state of the art, and propose \textbf{AnyViewBench}, a challenging new benchmark tailored towards \emph{extreme} dynamic view synthesis in diverse real-world scenarios. In this more dramatic setting, we find that most baselines drastically degrade in performance, as they require significant overlap between viewpoints, while AnyView maintains the ability to produce realistic, plausible, and spatiotemporally consistent videos when prompted from \emph{any} viewpoint. Results, data, code, and models can be viewed at: https://tri-ml.github.io/AnyView/
RecGPT-V2 Technical Report
Dec 16, 2025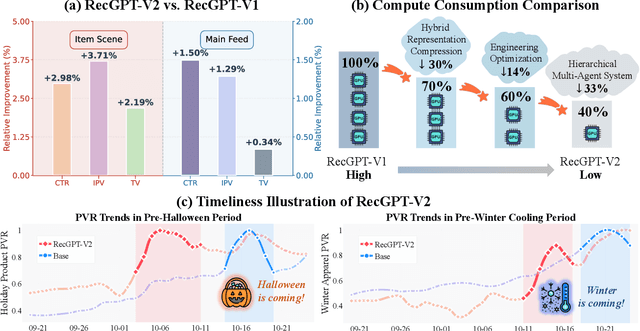
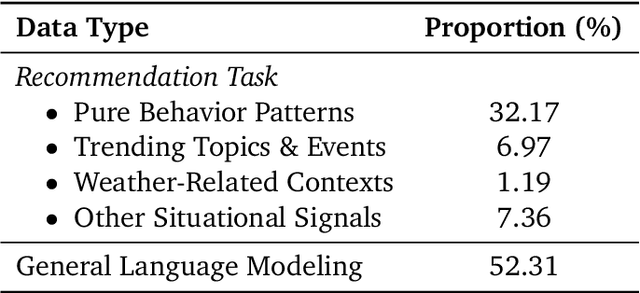
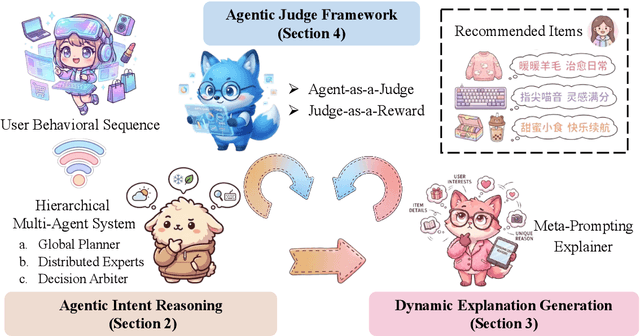

Large language models (LLMs) have demonstrated remarkable potential in transforming recommender systems from implicit behavioral pattern matching to explicit intent reasoning. While RecGPT-V1 successfully pioneered this paradigm by integrating LLM-based reasoning into user interest mining and item tag prediction, it suffers from four fundamental limitations: (1) computational inefficiency and cognitive redundancy across multiple reasoning routes; (2) insufficient explanation diversity in fixed-template generation; (3) limited generalization under supervised learning paradigms; and (4) simplistic outcome-focused evaluation that fails to match human standards. To address these challenges, we present RecGPT-V2 with four key innovations. First, a Hierarchical Multi-Agent System restructures intent reasoning through coordinated collaboration, eliminating cognitive duplication while enabling diverse intent coverage. Combined with Hybrid Representation Inference that compresses user-behavior contexts, our framework reduces GPU consumption by 60% and improves exclusive recall from 9.39% to 10.99%. Second, a Meta-Prompting framework dynamically generates contextually adaptive prompts, improving explanation diversity by +7.3%. Third, constrained reinforcement learning mitigates multi-reward conflicts, achieving +24.1% improvement in tag prediction and +13.0% in explanation acceptance. Fourth, an Agent-as-a-Judge framework decomposes assessment into multi-step reasoning, improving human preference alignment. Online A/B tests on Taobao demonstrate significant improvements: +2.98% CTR, +3.71% IPV, +2.19% TV, and +11.46% NER. RecGPT-V2 establishes both the technical feasibility and commercial viability of deploying LLM-powered intent reasoning at scale, bridging the gap between cognitive exploration and industrial utility.
GeoPep: A geometry-aware masked language model for protein-peptide binding site prediction
Oct 30, 2025Multimodal approaches that integrate protein structure and sequence have achieved remarkable success in protein-protein interface prediction. However, extending these methods to protein-peptide interactions remains challenging due to the inherent conformational flexibility of peptides and the limited availability of structural data that hinder direct training of structure-aware models. To address these limitations, we introduce GeoPep, a novel framework for peptide binding site prediction that leverages transfer learning from ESM3, a multimodal protein foundation model. GeoPep fine-tunes ESM3's rich pre-learned representations from protein-protein binding to address the limited availability of protein-peptide binding data. The fine-tuned model is further integrated with a parameter-efficient neural network architecture capable of learning complex patterns from sparse data. Furthermore, the model is trained using distance-based loss functions that exploit 3D structural information to enhance binding site prediction. Comprehensive evaluations demonstrate that GeoPep significantly outperforms existing methods in protein-peptide binding site prediction by effectively capturing sparse and heterogeneous binding patterns.
UniLDiff: Unlocking the Power of Diffusion Priors for All-in-One Image Restoration
Jul 31, 2025



All-in-One Image Restoration (AiOIR) has emerged as a promising yet challenging research direction. To address its core challenges, we propose a novel unified image restoration framework based on latent diffusion models (LDMs). Our approach structurally integrates low-quality visual priors into the diffusion process, unlocking the powerful generative capacity of diffusion models for diverse degradations. Specifically, we design a Degradation-Aware Feature Fusion (DAFF) module to enable adaptive handling of diverse degradation types. Furthermore, to mitigate detail loss caused by the high compression and iterative sampling of LDMs, we design a Detail-Aware Expert Module (DAEM) in the decoder to enhance texture and fine-structure recovery. Extensive experiments across multi-task and mixed degradation settings demonstrate that our method consistently achieves state-of-the-art performance, highlighting the practical potential of diffusion priors for unified image restoration. Our code will be released.
XSpecMesh: Quality-Preserving Auto-Regressive Mesh Generation Acceleration via Multi-Head Speculative Decoding
Jul 31, 2025Current auto-regressive models can generate high-quality, topologically precise meshes; however, they necessitate thousands-or even tens of thousands-of next-token predictions during inference, resulting in substantial latency. We introduce XSpecMesh, a quality-preserving acceleration method for auto-regressive mesh generation models. XSpecMesh employs a lightweight, multi-head speculative decoding scheme to predict multiple tokens in parallel within a single forward pass, thereby accelerating inference. We further propose a verification and resampling strategy: the backbone model verifies each predicted token and resamples any tokens that do not meet the quality criteria. In addition, we propose a distillation strategy that trains the lightweight decoding heads by distilling from the backbone model, encouraging their prediction distributions to align and improving the success rate of speculative predictions. Extensive experiments demonstrate that our method achieves a 1.7x speedup without sacrificing generation quality. Our code will be released.