 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneSmith: Agentic Generation of Simulation-Ready Indoor Scenes
Feb 09, 2026Simulation has become a key tool for training and evaluating home robots at scale, yet existing environments fail to capture the diversity and physical complexity of real indoor spaces. Current scene synthesis methods produce sparsely furnished rooms that lack the dense clutter, articulated furniture, and physical properties essential for robotic manipulation. We introduce SceneSmith, a hierarchical agentic framework that generates simulation-ready indoor environments from natural language prompts. SceneSmith constructs scenes through successive stages$\unicode{x2013}$from architectural layout to furniture placement to small object population$\unicode{x2013}$each implemented as an interaction among VLM agents: designer, critic, and orchestrator. The framework tightly integrates asset generation through text-to-3D synthesis for static objects, dataset retrieval for articulated objects, and physical property estimation. SceneSmith generates 3-6x more objects than prior methods, with <2% inter-object collisions and 96% of objects remaining stable under physics simulation. In a user study with 205 participants, it achieves 92% average realism and 91% average prompt faithfulness win rates against baselines. We further demonstrate that these environments can be used in an end-to-end pipeline for automatic robot policy evaluation.
AnyView: Synthesizing Any Novel View in Dynamic Scenes
Jan 23, 2026Modern generative video models excel at producing convincing, high-quality outputs, but struggle to maintain multi-view and spatiotemporal consistency in highly dynamic real-world environments. In this work, we introduce \textbf{AnyView}, a diffusion-based video generation framework for \emph{dynamic view synthesis} with minimal inductive biases or geometric assumptions. We leverage multiple data sources with various levels of supervision, including monocular (2D), multi-view static (3D) and multi-view dynamic (4D) datasets, to train a generalist spatiotemporal implicit representation capable of producing zero-shot novel videos from arbitrary camera locations and trajectories. We evaluate AnyView on standard benchmarks, showing competitive results with the current state of the art, and propose \textbf{AnyViewBench}, a challenging new benchmark tailored towards \emph{extreme} dynamic view synthesis in diverse real-world scenarios. In this more dramatic setting, we find that most baselines drastically degrade in performance, as they require significant overlap between viewpoints, while AnyView maintains the ability to produce realistic, plausible, and spatiotemporally consistent videos when prompted from \emph{any} viewpoint. Results, data, code, and models can be viewed at: https://tri-ml.github.io/AnyView/
PolaRiS: Scalable Real-to-Sim Evaluations for Generalist Robot Policies
Dec 18, 2025A significant challenge for robot learning research is our ability to accurately measure and compare the performance of robot policies. Benchmarking in robotics is historically challenging due to the stochasticity, reproducibility, and time-consuming nature of real-world rollouts. This challenge is exacerbated for recent generalist policies, which has to be evaluated across a wide variety of scenes and tasks. Evaluation in simulation offers a scalable complement to real world evaluations, but the visual and physical domain gap between existing simulation benchmarks and the real world has made them an unreliable signal for policy improvement. Furthermore, building realistic and diverse simulated environments has traditionally required significant human effort and expertise. To bridge the gap, we introduce Policy Evaluation and Environment Reconstruction in Simulation (PolaRiS), a scalable real-to-sim framework for high-fidelity simulated robot evaluation. PolaRiS utilizes neural reconstruction methods to turn short video scans of real-world scenes into interactive simulation environments. Additionally, we develop a simple simulation data co-training recipe that bridges remaining real-to-sim gaps and enables zero-shot evaluation in unseen simulation environments. Through extensive paired evaluations between simulation and the real world, we demonstrate that PolaRiS evaluations provide a much stronger correlation to real world generalist policy performance than existing simulated benchmarks. Its simplicity also enables rapid creation of diverse simulated environments. As such, this work takes a step towards distributed and democratized evaluation for the next generation of robotic foundation models.
GTR: Gaussian Splatting Tracking and Reconstruction of Unknown Objects Based on Appearance and Geometric Complexity
May 17, 2025We present a novel method for 6-DoF object tracking and high-quality 3D reconstruction from monocular RGBD video. Existing methods, while achieving impressive results, often struggle with complex objects, particularly those exhibiting symmetry, intricate geometry or complex appearance. To bridge these gaps, we introduce an adaptive method that combines 3D Gaussian Splatting, hybrid geometry/appearance tracking, and key frame selection to achieve robust tracking and accurate reconstructions across a diverse range of objects. Additionally, we present a benchmark covering these challenging object classes, providing high-quality annotations for evaluating both tracking and reconstruction performance. Our approach demonstrates strong capabilities in recovering high-fidelity object meshes, setting a new standard for single-sensor 3D reconstruction in open-world environments.
Steerable Scene Generation with Post Training and Inference-Time Search
May 07, 2025Training robots in simulation requires diverse 3D scenes that reflect the specific challenges of downstream tasks. However, scenes that satisfy strict task requirements, such as high-clutter environments with plausible spatial arrangement, are rare and costly to curate manually. Instead, we generate large-scale scene data using procedural models that approximate realistic environments for robotic manipulation, and adapt it to task-specific goals. We do this by training a unified diffusion-based generative model that predicts which objects to place from a fixed asset library, along with their SE(3) poses. This model serves as a flexible scene prior that can be adapted using reinforcement learning-based post training, conditional generation, or inference-time search, steering generation toward downstream objectives even when they differ from the original data distribution. Our method enables goal-directed scene synthesis that respects physical feasibility and scales across scene types. We introduce a novel MCTS-based inference-time search strategy for diffusion models, enforce feasibility via projection and simulation, and release a dataset of over 44 million SE(3) scenes spanning five diverse environments. Website with videos, code, data, and model weights: https://steerable-scene-generation.github.io/
ZeroGrasp: Zero-Shot Shape Reconstruction Enabled Robotic Grasping
Apr 15, 2025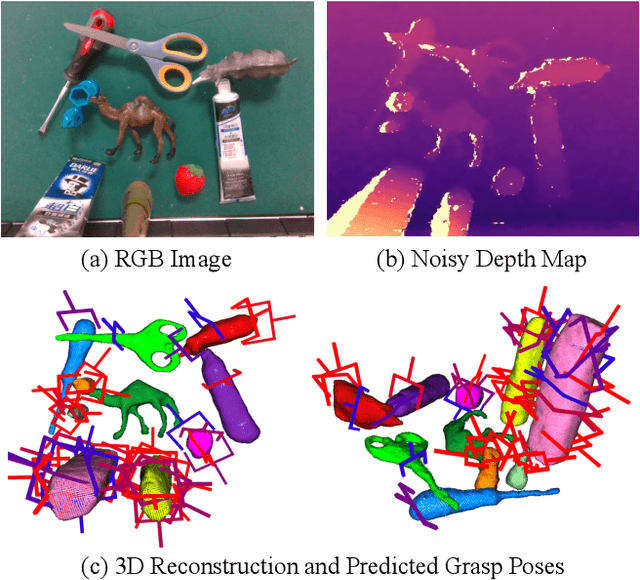
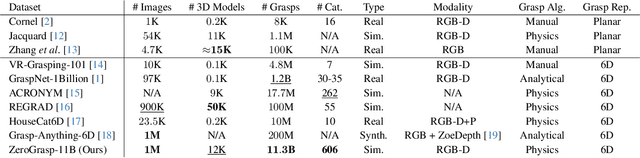
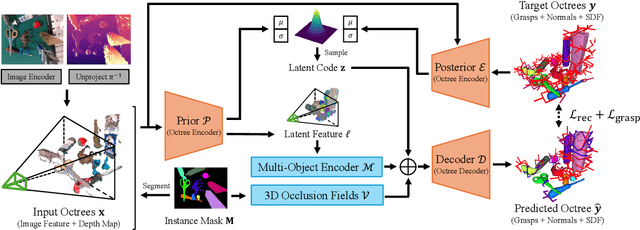
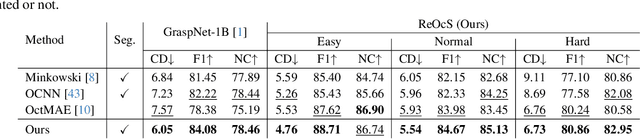
Robotic grasping is a cornerstone capability of embodied systems. Many methods directly output grasps from partial information without modeling the geometry of the scene, leading to suboptimal motion and even collisions. To address these issues, we introduce ZeroGrasp, a novel framework that simultaneously performs 3D reconstruction and grasp pose prediction in near real-time. A key insight of our method is that occlusion reasoning and modeling the spatial relationships between objects is beneficial for both accurate reconstruction and grasping. We couple our method with a novel large-scale synthetic dataset, which comprises 1M photo-realistic images, high-resolution 3D reconstructions and 11.3B physically-valid grasp pose annotations for 12K objects from the Objaverse-LVIS dataset. We evaluate ZeroGrasp on the GraspNet-1B benchmark as well as through real-world robot experiments. ZeroGrasp achieves state-of-the-art performance and generalizes to novel real-world objects by leveraging synthetic data.
$SE(3)$ Equivariant Ray Embeddings for Implicit Multi-View Depth Estimation
Nov 11, 2024Incorporating inductive bias by embedding geometric entities (such as rays) as input has proven successful in multi-view learning. However, the methods adopting this technique typically lack equivariance, which is crucial for effective 3D learning. Equivariance serves as a valuable inductive prior, aiding in the generation of robust multi-view features for 3D scene understanding. In this paper, we explore the application of equivariant multi-view learning to depth estimation, not only recognizing its significance for computer vision and robotics but also addressing the limitations of previous research. Most prior studies have either overlooked equivariance in this setting or achieved only approximate equivariance through data augmentation, which often leads to inconsistencies across different reference frames. To address this issue, we propose to embed $SE(3)$ equivariance into the Perceiver IO architecture. We employ Spherical Harmonics for positional encoding to ensure 3D rotation equivariance, and develop a specialized equivariant encoder and decoder within the Perceiver IO architecture. To validate our model, we applied it to the task of stereo depth estimation, achieving state of the art results on real-world datasets without explicit geometric constraints or extensive data augmentation.
View-Invariant Policy Learning via Zero-Shot Novel View Synthesis
Sep 05, 2024Large-scale visuomotor policy learning is a promising approach toward developing generalizable manipulation systems. Yet, policies that can be deployed on diverse embodiments, environments, and observational modalities remain elusive. In this work, we investigate how knowledge from large-scale visual data of the world may be used to address one axis of variation for generalizable manipulation: observational viewpoint. Specifically, we study single-image novel view synthesis models, which learn 3D-aware scene-level priors by rendering images of the same scene from alternate camera viewpoints given a single input image. For practical application to diverse robotic data, these models must operate zero-shot, performing view synthesis on unseen tasks and environments. We empirically analyze view synthesis models within a simple data-augmentation scheme that we call View Synthesis Augmentation (VISTA) to understand their capabilities for learning viewpoint-invariant policies from single-viewpoint demonstration data. Upon evaluating the robustness of policies trained with our method to out-of-distribution camera viewpoints, we find that they outperform baselines in both simulated and real-world manipulation tasks. Videos and additional visualizations are available at https://s-tian.github.io/projects/vista.
Incorporating dense metric depth into neural 3D representations for view synthesis and relighting
Sep 04, 2024



Synthesizing accurate geometry and photo-realistic appearance of small scenes is an active area of research with compelling use cases in gaming, virtual reality, robotic-manipulation, autonomous driving, convenient product capture, and consumer-level photography. When applying scene geometry and appearance estimation techniques to robotics, we found that the narrow cone of possible viewpoints due to the limited range of robot motion and scene clutter caused current estimation techniques to produce poor quality estimates or even fail. On the other hand, in robotic applications, dense metric depth can often be measured directly using stereo and illumination can be controlled. Depth can provide a good initial estimate of the object geometry to improve reconstruction, while multi-illumination images can facilitate relighting. In this work we demonstrate a method to incorporate dense metric depth into the training of neural 3D representations and address an artifact observed while jointly refining geometry and appearance by disambiguating between texture and geometry edges. We also discuss a multi-flash stereo camera system developed to capture the necessary data for our pipeline and show results on relighting and view synthesis with a few training views.
ReFiNe: Recursive Field Networks for Cross-modal Multi-scene Representation
Jun 06, 2024



The common trade-offs of state-of-the-art methods for multi-shape representation (a single model "packing" multiple objects) involve trading modeling accuracy against memory and storage. We show how to encode multiple shapes represented as continuous neural fields with a higher degree of precision than previously possible and with low memory usage. Key to our approach is a recursive hierarchical formulation that exploits object self-similarity, leading to a highly compressed and efficient shape latent space. Thanks to the recursive formulation, our method supports spatial and global-to-local latent feature fusion without needing to initialize and maintain auxiliary data structures, while still allowing for continuous field queries to enable applications such as raytracing. In experiments on a set of diverse datasets, we provide compelling qualitative results and demonstrate state-of-the-art multi-scene reconstruction and compression results with a single network per dataset.