 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProgramming Manufacturing Robots with Imperfect AI: LLMs as Tuning Experts for FDM Print Configuration Selection
Mar 23, 2026We use fused deposition modeling (FDM) 3D printing as a case study of how manufacturing robots can use imperfect AI to acquire process expertise. In FDM, print configuration strongly affects output quality. Yet, novice users typically rely on default configurations, trial-and-error, or recommendations from generic AI models (e.g., ChatGPT). These strategies can produce complete prints, but they do not reliably meet specific objectives. Experts iteratively tune print configurations using evidence from prior prints. We present a modular closed-loop approach that treats an LLM as a source of tuning expertise. We embed this source of expertise within a Bayesian optimization loop. An approximate evaluator scores each print configuration and returns structured diagnostics, which the LLM uses to propose natural-language adjustments that are compiled into machine-actionable guidance for optimization. On 100 Thingi10k parts, our LLM-guided loop achieves the best configuration on 78% objects with 0% likely-to-fail cases, while single-shot AI model recommendations are rarely best and exhibit 15% likely-to-fail cases. These results suggest that LLMs provide more value as constrained decision modules in evidence-driven optimization loops than as end-to-end oracles for print configuration selection. We expect this result to extend to broader LLM-based robot programming.
Human Preference Modeling Using Visual Motion Prediction Improves Robot Skill Learning from Egocentric Human Video
Feb 11, 2026We present an approach to robot learning from egocentric human videos by modeling human preferences in a reward function and optimizing robot behavior to maximize this reward. Prior work on reward learning from human videos attempts to measure the long-term value of a visual state as the temporal distance between it and the terminal state in a demonstration video. These approaches make assumptions that limit performance when learning from video. They must also transfer the learned value function across the embodiment and environment gap. Our method models human preferences by learning to predict the motion of tracked points between subsequent images and defines a reward function as the agreement between predicted and observed object motion in a robot's behavior at each step. We then use a modified Soft Actor Critic (SAC) algorithm initialized with 10 on-robot demonstrations to estimate a value function from this reward and optimize a policy that maximizes this value function, all on the robot. Our approach is capable of learning on a real robot, and we show that policies learned with our reward model match or outperform prior work across multiple tasks in both simulation and on the real robot.
Soft Robotic Dynamic In-Hand Pen Spinning
Nov 19, 2024



Dynamic in-hand manipulation remains a challenging task for soft robotic systems that have demonstrated advantages in safe compliant interactions but struggle with high-speed dynamic tasks. In this work, we present SWIFT, a system for learning dynamic tasks using a soft and compliant robotic hand. Unlike previous works that rely on simulation, quasi-static actions and precise object models, the proposed system learns to spin a pen through trial-and-error using only real-world data without requiring explicit prior knowledge of the pen's physical attributes. With self-labeled trials sampled from the real world, the system discovers the set of pen grasping and spinning primitive parameters that enables a soft hand to spin a pen robustly and reliably. After 130 sampled actions per object, SWIFT achieves 100% success rate across three pens with different weights and weight distributions, demonstrating the system's generalizability and robustness to changes in object properties. The results highlight the potential for soft robotic end-effectors to perform dynamic tasks including rapid in-hand manipulation. We also demonstrate that SWIFT generalizes to spinning items with different shapes and weights such as a brush and a screwdriver which we spin with 10/10 and 5/10 success rates respectively. Videos, data, and code are available at https://soft-spin.github.io.
Incorporating dense metric depth into neural 3D representations for view synthesis and relighting
Sep 04, 2024



Synthesizing accurate geometry and photo-realistic appearance of small scenes is an active area of research with compelling use cases in gaming, virtual reality, robotic-manipulation, autonomous driving, convenient product capture, and consumer-level photography. When applying scene geometry and appearance estimation techniques to robotics, we found that the narrow cone of possible viewpoints due to the limited range of robot motion and scene clutter caused current estimation techniques to produce poor quality estimates or even fail. On the other hand, in robotic applications, dense metric depth can often be measured directly using stereo and illumination can be controlled. Depth can provide a good initial estimate of the object geometry to improve reconstruction, while multi-illumination images can facilitate relighting. In this work we demonstrate a method to incorporate dense metric depth into the training of neural 3D representations and address an artifact observed while jointly refining geometry and appearance by disambiguating between texture and geometry edges. We also discuss a multi-flash stereo camera system developed to capture the necessary data for our pipeline and show results on relighting and view synthesis with a few training views.
Controlled illumination for perception and manipulation of Lambertian objects
Apr 24, 2023


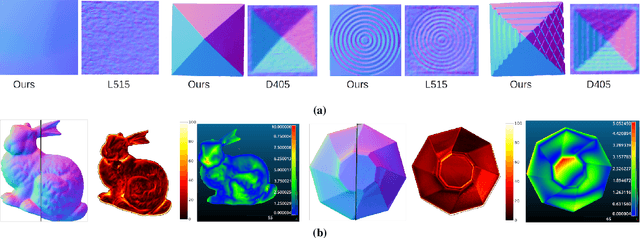
Controlling illumination can generate high quality information about object surface normals and depth discontinuities at a low computational cost. In this work we demonstrate a robot workspace-scaled controlled illumination approach that generates high quality information for table top scale objects for robotic manipulation. With our low angle of incidence directional illumination approach we can precisely capture surface normals and depth discontinuities of Lambertian objects. We demonstrate three use cases of our approach for robotic manipulation. We show that 1) by using the captured information we can perform general purpose grasping with a single point vacuum gripper, 2) we can visually measure the deformation of known objects, and 3) we can estimate pose of known objects and track unknown objects in the robot's workspace. Additional demonstrations of the results presented in the work can be viewed on the project webpage https://anonymousprojectsite.github.io/.
Learning Exploration Strategies to Solve Real-World Marble Runs
Mar 08, 2023

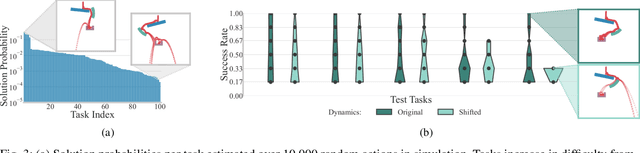

Tasks involving locally unstable or discontinuous dynamics (such as bifurcations and collisions) remain challenging in robotics, because small variations in the environment can have a significant impact on task outcomes. For such tasks, learning a robust deterministic policy is difficult. We focus on structuring exploration with multiple stochastic policies based on a mixture of experts (MoE) policy representation that can be efficiently adapted. The MoE policy is composed of stochastic sub-policies that allow exploration of multiple distinct regions of the action space (or strategies) and a high-level selection policy to guide exploration towards the most promising regions. We develop a robot system to evaluate our approach in a real-world physical problem solving domain. After training the MoE policy in simulation, online learning in the real world demonstrates efficient adaptation within just a few dozen attempts, with a minimal sim2real gap. Our results confirm that representing multiple strategies promotes efficient adaptation in new environments and strategies learned under different dynamics can still provide useful information about where to look for good strategies.
Using Collocated Vision and Tactile Sensors for Visual Servoing and Localization
Apr 27, 2022
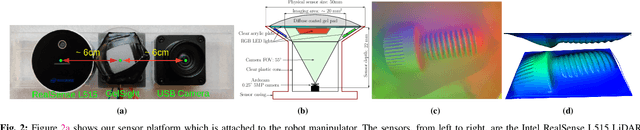


Coordinating proximity and tactile imaging by collocating cameras with tactile sensors can 1) provide useful information before contact such as object pose estimates and visually servo a robot to a target with reduced occlusion and higher resolution compared to head-mounted or external depth cameras, 2) simplify the contact point and pose estimation problems and help tactile sensing avoid erroneous matches when a surface does not have significant texture or has repetitive texture with many possible matches, and 3) use tactile imaging to further refine contact point and object pose estimation. We demonstrate our results with objects that have more surface texture than most objects in standard manipulation datasets. We learn that optic flow needs to be integrated over a substantial amount of camera travel to be useful in predicting movement direction. Most importantly, we also learn that state of the art vision algorithms do not do a good job localizing tactile images on object models, unless a reasonable prior can be provided from collocated cameras.
* This archival version of the manuscript is significantly different in content from the reviewed and published version. The published version can be accessed here: https://ieeexplore.ieee.org/document/9699405. Supplementary materials can be accessed here: https://arkadeepnc.github.io/projects/collocated_vision_touch/index.html
Using Deep Reinforcement Learning to Learn High-Level Policies on the ATRIAS Biped
Sep 28, 2018


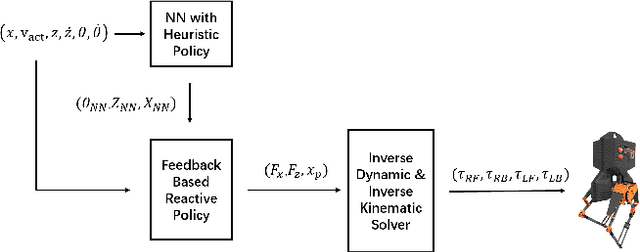
Learning controllers for bipedal robots is a challenging problem, often requiring expert knowledge and extensive tuning of parameters that vary in different situations. Recently, deep reinforcement learning has shown promise at automatically learning controllers for complex systems in simulation. This has been followed by a push towards learning controllers that can be transferred between simulation and hardware, primarily with the use of domain randomization. However, domain randomization can make the problem of finding stable controllers even more challenging, especially for underactuated bipedal robots. In this work, we explore whether policies learned in simulation can be transferred to hardware with the use of high-fidelity simulators and structured controllers. We learn a neural network policy which is a part of a more structured controller. While the neural network is learned in simulation, the rest of the controller stays fixed, and can be tuned by the expert as needed. We show that using this approach can greatly speed up the rate of learning in simulation, as well as enable transfer of policies between simulation and hardware. We present our results on an ATRIAS robot and explore the effect of action spaces and cost functions on the rate of transfer between simulation and hardware. Our results show that structured policies can indeed be learned in simulation and implemented on hardware successfully. This has several advantages, as the structure preserves the intuitive nature of the policy, and the neural network improves the performance of the hand-designed policy. In this way, we propose a way of using neural networks to improve expert designed controllers, while maintaining ease of understanding.
Using Simulation to Improve Sample-Efficiency of Bayesian Optimization for Bipedal Robots
May 07, 2018
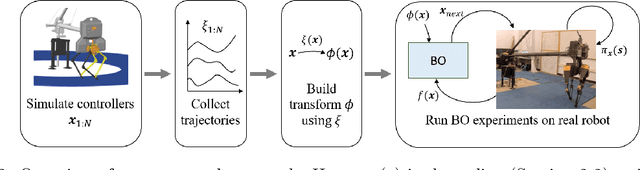

Learning for control can acquire controllers for novel robotic tasks, paving the path for autonomous agents. Such controllers can be expert-designed policies, which typically require tuning of parameters for each task scenario. In this context, Bayesian optimization (BO) has emerged as a promising approach for automatically tuning controllers. However, when performing BO on hardware for high-dimensional policies, sample-efficiency can be an issue. Here, we develop an approach that utilizes simulation to map the original parameter space into a domain-informed space. During BO, similarity between controllers is now calculated in this transformed space. Experiments on the ATRIAS robot hardware and another bipedal robot simulation show that our approach succeeds at sample-efficiently learning controllers for multiple robots. Another question arises: What if the simulation significantly differs from hardware? To answer this, we create increasingly approximate simulators and study the effect of increasing simulation-hardware mismatch on the performance of Bayesian optimization. We also compare our approach to other approaches from literature, and find it to be more reliable, especially in cases of high mismatch. Our experiments show that our approach succeeds across different controller types, bipedal robot models and simulator fidelity levels, making it applicable to a wide range of bipedal locomotion problems.
Deep Kernels for Optimizing Locomotion Controllers
Nov 08, 2017
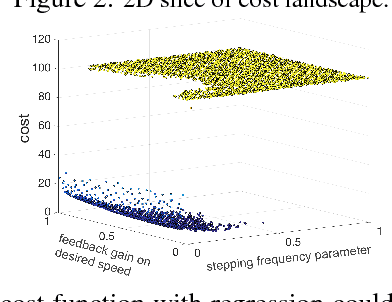
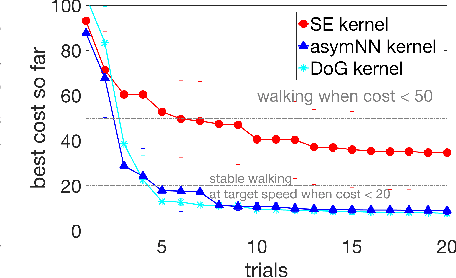
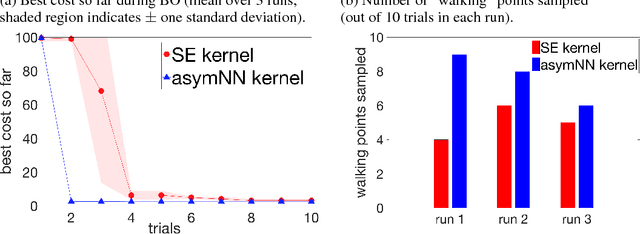
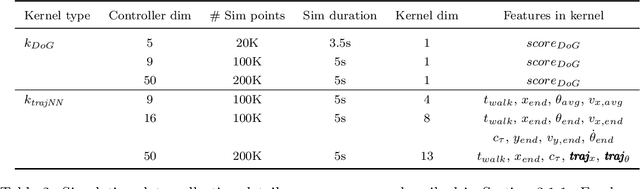
Sample efficiency is important when optimizing parameters of locomotion controllers, since hardware experiments are time consuming and expensive. Bayesian Optimization, a sample-efficient optimization framework, has recently been widely applied to address this problem, but further improvements in sample efficiency are needed for practical applicability to real-world robots and high-dimensional controllers. To address this, prior work has proposed using domain expertise for constructing custom distance metrics for locomotion. In this work we show how to learn such a distance metric automatically. We use a neural network to learn an informed distance metric from data obtained in high-fidelity simulations. We conduct experiments on two different controllers and robot architectures. First, we demonstrate improvement in sample efficiency when optimizing a 5-dimensional controller on the ATRIAS robot hardware. We then conduct simulation experiments to optimize a 16-dimensional controller for a 7-link robot model and obtain significant improvements even when optimizing in perturbed environments. This demonstrates that our approach is able to enhance sample efficiency for two different controllers, hence is a fitting candidate for further experiments on hardware in the future.
* (Rika Antonova and Akshara Rai contributed equally)