 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Deep Reinforcement Learning to Learn High-Level Policies on the ATRIAS Biped
Paper and Code
Sep 28, 2018


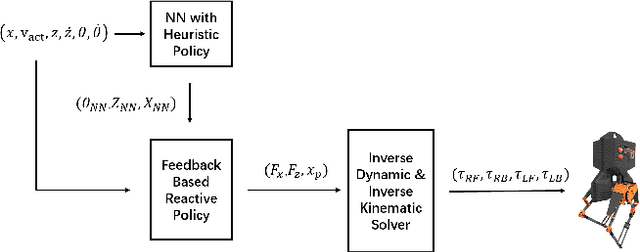
Learning controllers for bipedal robots is a challenging problem, often requiring expert knowledge and extensive tuning of parameters that vary in different situations. Recently, deep reinforcement learning has shown promise at automatically learning controllers for complex systems in simulation. This has been followed by a push towards learning controllers that can be transferred between simulation and hardware, primarily with the use of domain randomization. However, domain randomization can make the problem of finding stable controllers even more challenging, especially for underactuated bipedal robots. In this work, we explore whether policies learned in simulation can be transferred to hardware with the use of high-fidelity simulators and structured controllers. We learn a neural network policy which is a part of a more structured controller. While the neural network is learned in simulation, the rest of the controller stays fixed, and can be tuned by the expert as needed. We show that using this approach can greatly speed up the rate of learning in simulation, as well as enable transfer of policies between simulation and hardware. We present our results on an ATRIAS robot and explore the effect of action spaces and cost functions on the rate of transfer between simulation and hardware. Our results show that structured policies can indeed be learned in simulation and implemented on hardware successfully. This has several advantages, as the structure preserves the intuitive nature of the policy, and the neural network improves the performance of the hand-designed policy. In this way, we propose a way of using neural networks to improve expert designed controllers, while maintaining ease of understanding.