 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Generators are Robot Policies
Aug 01, 2025Despite tremendous progress in dexterous manipulation, current visuomotor policies remain fundamentally limited by two challenges: they struggle to generalize under perceptual or behavioral distribution shifts, and their performance is constrained by the size of human demonstration data. In this paper, we use video generation as a proxy for robot policy learning to address both limitations simultaneously. We propose Video Policy, a modular framework that combines video and action generation that can be trained end-to-end. Our results demonstrate that learning to generate videos of robot behavior allows for the extraction of policies with minimal demonstration data, significantly improving robustness and sample efficiency. Our method shows strong generalization to unseen objects, backgrounds, and tasks, both in simulation and the real world. We further highlight that task success is closely tied to the generated video, with action-free video data providing critical benefits for generalizing to novel tasks. By leveraging large-scale video generative models, we achieve superior performance compared to traditional behavior cloning, paving the way for more scalable and data-efficient robot policy learning.
AllTracker: Efficient Dense Point Tracking at High Resolution
Jun 08, 2025We introduce AllTracker: a model that estimates long-range point tracks by way of estimating the flow field between a query frame and every other frame of a video. Unlike existing point tracking methods, our approach delivers high-resolution and dense (all-pixel) correspondence fields, which can be visualized as flow maps. Unlike existing optical flow methods, our approach corresponds one frame to hundreds of subsequent frames, rather than just the next frame. We develop a new architecture for this task, blending techniques from existing work in optical flow and point tracking: the model performs iterative inference on low-resolution grids of correspondence estimates, propagating information spatially via 2D convolution layers, and propagating information temporally via pixel-aligned attention layers. The model is fast and parameter-efficient (16 million parameters), and delivers state-of-the-art point tracking accuracy at high resolution (i.e., tracking 768x1024 pixels, on a 40G GPU). A benefit of our design is that we can train on a wider set of datasets, and we find that doing so is crucial for top performance. We provide an extensive ablation study on our architecture details and training recipe, making it clear which details matter most. Our code and model weights are available at https://alltracker.github.io .
GTR: Gaussian Splatting Tracking and Reconstruction of Unknown Objects Based on Appearance and Geometric Complexity
May 17, 2025We present a novel method for 6-DoF object tracking and high-quality 3D reconstruction from monocular RGBD video. Existing methods, while achieving impressive results, often struggle with complex objects, particularly those exhibiting symmetry, intricate geometry or complex appearance. To bridge these gaps, we introduce an adaptive method that combines 3D Gaussian Splatting, hybrid geometry/appearance tracking, and key frame selection to achieve robust tracking and accurate reconstructions across a diverse range of objects. Additionally, we present a benchmark covering these challenging object classes, providing high-quality annotations for evaluating both tracking and reconstruction performance. Our approach demonstrates strong capabilities in recovering high-fidelity object meshes, setting a new standard for single-sensor 3D reconstruction in open-world environments.
ZeroGrasp: Zero-Shot Shape Reconstruction Enabled Robotic Grasping
Apr 15, 2025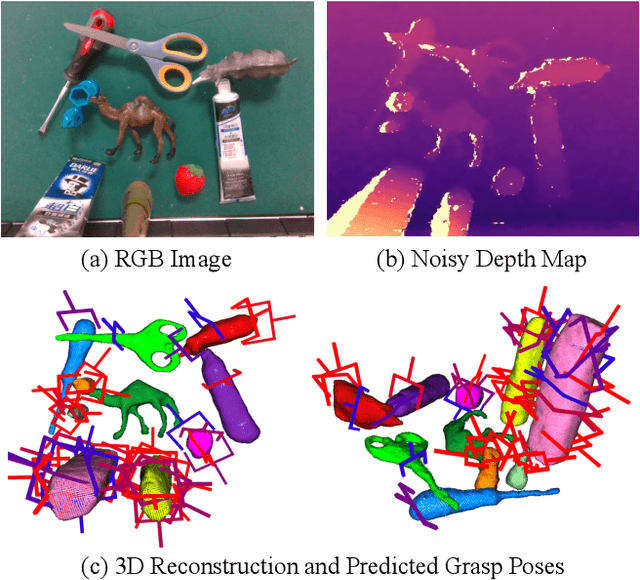
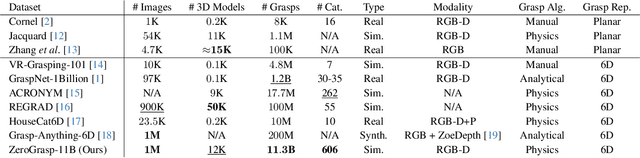
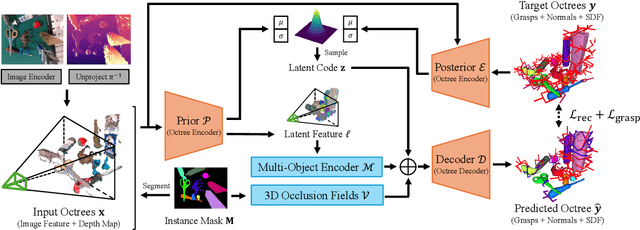
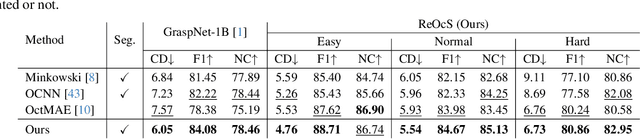
Robotic grasping is a cornerstone capability of embodied systems. Many methods directly output grasps from partial information without modeling the geometry of the scene, leading to suboptimal motion and even collisions. To address these issues, we introduce ZeroGrasp, a novel framework that simultaneously performs 3D reconstruction and grasp pose prediction in near real-time. A key insight of our method is that occlusion reasoning and modeling the spatial relationships between objects is beneficial for both accurate reconstruction and grasping. We couple our method with a novel large-scale synthetic dataset, which comprises 1M photo-realistic images, high-resolution 3D reconstructions and 11.3B physically-valid grasp pose annotations for 12K objects from the Objaverse-LVIS dataset. We evaluate ZeroGrasp on the GraspNet-1B benchmark as well as through real-world robot experiments. ZeroGrasp achieves state-of-the-art performance and generalizes to novel real-world objects by leveraging synthetic data.
Can We Detect Failures Without Failure Data? Uncertainty-Aware Runtime Failure Detection for Imitation Learning Policies
Mar 11, 2025Recent years have witnessed impressive robotic manipulation systems driven by advances in imitation learning and generative modeling, such as diffusion- and flow-based approaches. As robot policy performance increases, so does the complexity and time horizon of achievable tasks, inducing unexpected and diverse failure modes that are difficult to predict a priori. To enable trustworthy policy deployment in safety-critical human environments, reliable runtime failure detection becomes important during policy inference. However, most existing failure detection approaches rely on prior knowledge of failure modes and require failure data during training, which imposes a significant challenge in practicality and scalability. In response to these limitations, we present FAIL-Detect, a modular two-stage approach for failure detection in imitation learning-based robotic manipulation. To accurately identify failures from successful training data alone, we frame the problem as sequential out-of-distribution (OOD) detection. We first distill policy inputs and outputs into scalar signals that correlate with policy failures and capture epistemic uncertainty. FAIL-Detect then employs conformal prediction (CP) as a versatile framework for uncertainty quantification with statistical guarantees. Empirically, we thoroughly investigate both learned and post-hoc scalar signal candidates on diverse robotic manipulation tasks. Our experiments show learned signals to be mostly consistently effective, particularly when using our novel flow-based density estimator. Furthermore, our method detects failures more accurately and faster than state-of-the-art (SOTA) failure detection baselines. These results highlight the potential of FAIL-Detect to enhance the safety and reliability of imitation learning-based robotic systems as they progress toward real-world deployment.
Zero-Shot Novel View and Depth Synthesis with Multi-View Geometric Diffusion
Jan 30, 2025



Current methods for 3D scene reconstruction from sparse posed images employ intermediate 3D representations such as neural fields, voxel grids, or 3D Gaussians, to achieve multi-view consistent scene appearance and geometry. In this paper we introduce MVGD, a diffusion-based architecture capable of direct pixel-level generation of images and depth maps from novel viewpoints, given an arbitrary number of input views. Our method uses raymap conditioning to both augment visual features with spatial information from different viewpoints, as well as to guide the generation of images and depth maps from novel views. A key aspect of our approach is the multi-task generation of images and depth maps, using learnable task embeddings to guide the diffusion process towards specific modalities. We train this model on a collection of more than 60 million multi-view samples from publicly available datasets, and propose techniques to enable efficient and consistent learning in such diverse conditions. We also propose a novel strategy that enables the efficient training of larger models by incrementally fine-tuning smaller ones, with promising scaling behavior. Through extensive experiments, we report state-of-the-art results in multiple novel view synthesis benchmarks, as well as multi-view stereo and video depth estimation.
Espresso: High Compression For Rich Extraction From Videos for Your Vision-Language Model
Dec 06, 2024Most of the current vision-language models (VLMs) for videos struggle to understand videos longer than a few seconds. This is primarily due to the fact that they do not scale to utilizing a large number of frames. In order to address this limitation, we propose Espresso, a novel method that extracts and compresses spatial and temporal information separately. Through extensive evaluations, we show that spatial and temporal compression in Espresso each have a positive impact on the long-form video understanding capabilities; when combined, their positive impact increases. Furthermore, we show that Espresso's performance scales well with more training data, and that Espresso is far more effective than the existing projectors for VLMs in long-form video understanding. Moreover, we devise a more difficult evaluation setting for EgoSchema called "needle-in-a-haystack" that multiplies the lengths of the input videos. Espresso achieves SOTA performance on this task, outperforming the SOTA VLMs that have been trained on much more training data.
$SE(3)$ Equivariant Ray Embeddings for Implicit Multi-View Depth Estimation
Nov 11, 2024Incorporating inductive bias by embedding geometric entities (such as rays) as input has proven successful in multi-view learning. However, the methods adopting this technique typically lack equivariance, which is crucial for effective 3D learning. Equivariance serves as a valuable inductive prior, aiding in the generation of robust multi-view features for 3D scene understanding. In this paper, we explore the application of equivariant multi-view learning to depth estimation, not only recognizing its significance for computer vision and robotics but also addressing the limitations of previous research. Most prior studies have either overlooked equivariance in this setting or achieved only approximate equivariance through data augmentation, which often leads to inconsistencies across different reference frames. To address this issue, we propose to embed $SE(3)$ equivariance into the Perceiver IO architecture. We employ Spherical Harmonics for positional encoding to ensure 3D rotation equivariance, and develop a specialized equivariant encoder and decoder within the Perceiver IO architecture. To validate our model, we applied it to the task of stereo depth estimation, achieving state of the art results on real-world datasets without explicit geometric constraints or extensive data augmentation.
Neural Fields in Robotics: A Survey
Oct 26, 2024



Neural Fields have emerged as a transformative approach for 3D scene representation in computer vision and robotics, enabling accurate inference of geometry, 3D semantics, and dynamics from posed 2D data. Leveraging differentiable rendering, Neural Fields encompass both continuous implicit and explicit neural representations enabling high-fidelity 3D reconstruction, integration of multi-modal sensor data, and generation of novel viewpoints. This survey explores their applications in robotics, emphasizing their potential to enhance perception, planning, and control. Their compactness, memory efficiency, and differentiability, along with seamless integration with foundation and generative models, make them ideal for real-time applications, improving robot adaptability and decision-making. This paper provides a thorough review of Neural Fields in robotics, categorizing applications across various domains and evaluating their strengths and limitations, based on over 200 papers. First, we present four key Neural Fields frameworks: Occupancy Networks, Signed Distance Fields, Neural Radiance Fields, and Gaussian Splatting. Second, we detail Neural Fields' applications in five major robotics domains: pose estimation, manipulation, navigation, physics, and autonomous driving, highlighting key works and discussing takeaways and open challenges. Finally, we outline the current limitations of Neural Fields in robotics and propose promising directions for future research. Project page: https://robonerf.github.io
GRIN: Zero-Shot Metric Depth with Pixel-Level Diffusion
Sep 15, 2024



3D reconstruction from a single image is a long-standing problem in computer vision. Learning-based methods address its inherent scale ambiguity by leveraging increasingly large labeled and unlabeled datasets, to produce geometric priors capable of generating accurate predictions across domains. As a result, state of the art approaches show impressive performance in zero-shot relative and metric depth estimation. Recently, diffusion models have exhibited remarkable scalability and generalizable properties in their learned representations. However, because these models repurpose tools originally designed for image generation, they can only operate on dense ground-truth, which is not available for most depth labels, especially in real-world settings. In this paper we present GRIN, an efficient diffusion model designed to ingest sparse unstructured training data. We use image features with 3D geometric positional encodings to condition the diffusion process both globally and locally, generating depth predictions at a pixel-level. With comprehensive experiments across eight indoor and outdoor datasets, we show that GRIN establishes a new state of the art in zero-shot metric monocular depth estimation even when trained from scratch.