 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVLA Foundry: A Unified Framework for Training Vision-Language-Action Models
Apr 21, 2026We present VLA Foundry, an open-source framework that unifies LLM, VLM, and VLA training in a single codebase. Most open-source VLA efforts specialize on the action training stage, often stitching together incompatible pretraining pipelines. VLA Foundry instead provides a shared training stack with end-to-end control, from language pretraining to action-expert fine-tuning. VLA Foundry supports both from-scratch training and pretrained backbones from Hugging Face. To demonstrate the utility of our framework, we train and release two types of models: the first trained fully from scratch through our LLM-->VLM-->VLA pipeline and the second built on the pretrained Qwen3-VL backbone. We evaluate closed-loop policy performance of both models on LBM Eval, an open-data, open-source simulator. We also contribute usability improvements to the simulator and the STEP analysis tools for easier public use. In the nominal evaluation setting, our fully-open from-scratch model is on par with our prior closed-source work and substituting in the Qwen3-VL backbone leads to a strong multi-task table top manipulation policy outperforming our baseline by a wide margin. The VLA Foundry codebase is available at https://github.com/TRI-ML/vla_foundry and all multi-task model weights are released on https://huggingface.co/collections/TRI-ML/vla-foundry. Additional qualitative videos are available on the project website https://tri-ml.github.io/vla_foundry.
AnyView: Synthesizing Any Novel View in Dynamic Scenes
Jan 23, 2026Modern generative video models excel at producing convincing, high-quality outputs, but struggle to maintain multi-view and spatiotemporal consistency in highly dynamic real-world environments. In this work, we introduce \textbf{AnyView}, a diffusion-based video generation framework for \emph{dynamic view synthesis} with minimal inductive biases or geometric assumptions. We leverage multiple data sources with various levels of supervision, including monocular (2D), multi-view static (3D) and multi-view dynamic (4D) datasets, to train a generalist spatiotemporal implicit representation capable of producing zero-shot novel videos from arbitrary camera locations and trajectories. We evaluate AnyView on standard benchmarks, showing competitive results with the current state of the art, and propose \textbf{AnyViewBench}, a challenging new benchmark tailored towards \emph{extreme} dynamic view synthesis in diverse real-world scenarios. In this more dramatic setting, we find that most baselines drastically degrade in performance, as they require significant overlap between viewpoints, while AnyView maintains the ability to produce realistic, plausible, and spatiotemporally consistent videos when prompted from \emph{any} viewpoint. Results, data, code, and models can be viewed at: https://tri-ml.github.io/AnyView/
GTR: Gaussian Splatting Tracking and Reconstruction of Unknown Objects Based on Appearance and Geometric Complexity
May 17, 2025We present a novel method for 6-DoF object tracking and high-quality 3D reconstruction from monocular RGBD video. Existing methods, while achieving impressive results, often struggle with complex objects, particularly those exhibiting symmetry, intricate geometry or complex appearance. To bridge these gaps, we introduce an adaptive method that combines 3D Gaussian Splatting, hybrid geometry/appearance tracking, and key frame selection to achieve robust tracking and accurate reconstructions across a diverse range of objects. Additionally, we present a benchmark covering these challenging object classes, providing high-quality annotations for evaluating both tracking and reconstruction performance. Our approach demonstrates strong capabilities in recovering high-fidelity object meshes, setting a new standard for single-sensor 3D reconstruction in open-world environments.
Steerable Scene Generation with Post Training and Inference-Time Search
May 07, 2025Training robots in simulation requires diverse 3D scenes that reflect the specific challenges of downstream tasks. However, scenes that satisfy strict task requirements, such as high-clutter environments with plausible spatial arrangement, are rare and costly to curate manually. Instead, we generate large-scale scene data using procedural models that approximate realistic environments for robotic manipulation, and adapt it to task-specific goals. We do this by training a unified diffusion-based generative model that predicts which objects to place from a fixed asset library, along with their SE(3) poses. This model serves as a flexible scene prior that can be adapted using reinforcement learning-based post training, conditional generation, or inference-time search, steering generation toward downstream objectives even when they differ from the original data distribution. Our method enables goal-directed scene synthesis that respects physical feasibility and scales across scene types. We introduce a novel MCTS-based inference-time search strategy for diffusion models, enforce feasibility via projection and simulation, and release a dataset of over 44 million SE(3) scenes spanning five diverse environments. Website with videos, code, data, and model weights: https://steerable-scene-generation.github.io/
ZeroGrasp: Zero-Shot Shape Reconstruction Enabled Robotic Grasping
Apr 15, 2025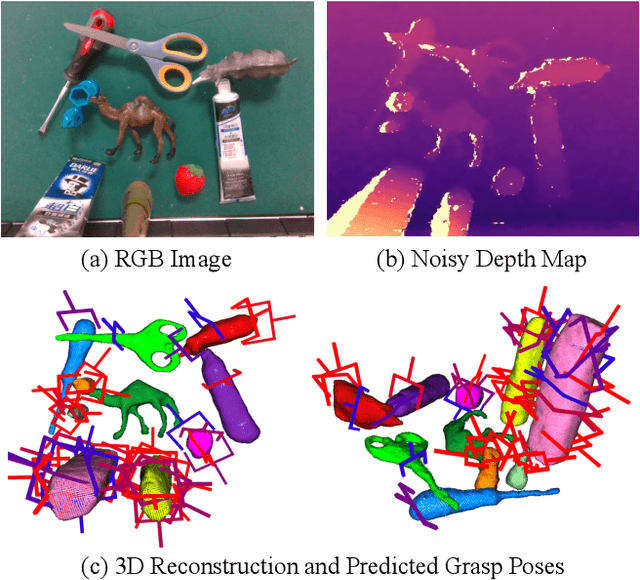
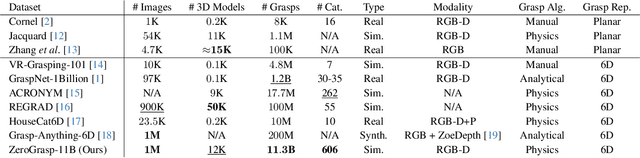
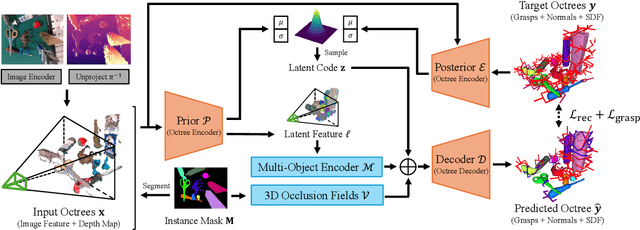
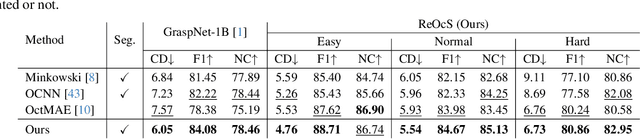
Robotic grasping is a cornerstone capability of embodied systems. Many methods directly output grasps from partial information without modeling the geometry of the scene, leading to suboptimal motion and even collisions. To address these issues, we introduce ZeroGrasp, a novel framework that simultaneously performs 3D reconstruction and grasp pose prediction in near real-time. A key insight of our method is that occlusion reasoning and modeling the spatial relationships between objects is beneficial for both accurate reconstruction and grasping. We couple our method with a novel large-scale synthetic dataset, which comprises 1M photo-realistic images, high-resolution 3D reconstructions and 11.3B physically-valid grasp pose annotations for 12K objects from the Objaverse-LVIS dataset. We evaluate ZeroGrasp on the GraspNet-1B benchmark as well as through real-world robot experiments. ZeroGrasp achieves state-of-the-art performance and generalizes to novel real-world objects by leveraging synthetic data.
On the Relationship Between Double Descent of CNNs and Shape/Texture Bias Under Learning Process
Mar 04, 2025The double descent phenomenon, which deviates from the traditional bias-variance trade-off theory, attracts considerable research attention; however, the mechanism of its occurrence is not fully understood. On the other hand, in the study of convolutional neural networks (CNNs) for image recognition, methods are proposed to quantify the bias on shape features versus texture features in images, determining which features the CNN focuses on more. In this work, we hypothesize that there is a relationship between the shape/texture bias in the learning process of CNNs and epoch-wise double descent, and we conduct verification. As a result, we discover double descent/ascent of shape/texture bias synchronized with double descent of test error under conditions where epoch-wise double descent is observed. Quantitative evaluations confirm this correlation between the test errors and the bias values from the initial decrease to the full increase in test error. Interestingly, double descent/ascent of shape/texture bias is observed in some cases even in conditions without label noise, where double descent is thought not to occur. These experimental results are considered to contribute to the understanding of the mechanisms behind the double descent phenomenon and the learning process of CNNs in image recognition.
Generalizable Neural Human Renderer
Apr 22, 2024While recent advancements in animatable human rendering have achieved remarkable results, they require test-time optimization for each subject which can be a significant limitation for real-world applications. To address this, we tackle the challenging task of learning a Generalizable Neural Human Renderer (GNH), a novel method for rendering animatable humans from monocular video without any test-time optimization. Our core method focuses on transferring appearance information from the input video to the output image plane by utilizing explicit body priors and multi-view geometry. To render the subject in the intended pose, we utilize a straightforward CNN-based image renderer, foregoing the more common ray-sampling or rasterizing-based rendering modules. Our GNH achieves remarkable generalizable, photorealistic rendering with unseen subjects with a three-stage process. We quantitatively and qualitatively demonstrate that GNH significantly surpasses current state-of-the-art methods, notably achieving a 31.3% improvement in LPIPS.
Zero-Shot Multi-Object Shape Completion
Mar 21, 2024We present a 3D shape completion method that recovers the complete geometry of multiple objects in complex scenes from a single RGB-D image. Despite notable advancements in single object 3D shape completion, high-quality reconstructions in highly cluttered real-world multi-object scenes remains a challenge. To address this issue, we propose OctMAE, an architecture that leverages an Octree U-Net and a latent 3D MAE to achieve high-quality and near real-time multi-object shape completion through both local and global geometric reasoning. Because a na\"ive 3D MAE can be computationally intractable and memory intensive even in the latent space, we introduce a novel occlusion masking strategy and adopt 3D rotary embeddings, which significantly improves the runtime and shape completion quality. To generalize to a wide range of objects in diverse scenes, we create a large-scale photorealistic dataset, featuring a diverse set of 12K 3D object models from the Objaverse dataset which are rendered in multi-object scenes with physics-based positioning. Our method outperforms the current state-of-the-art on both synthetic and real-world datasets and demonstrates a strong zero-shot capability.
RelightableHands: Efficient Neural Relighting of Articulated Hand Models
Feb 09, 2023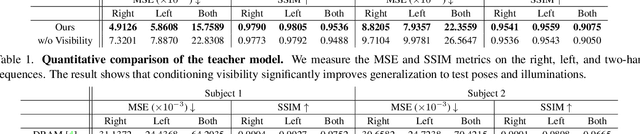
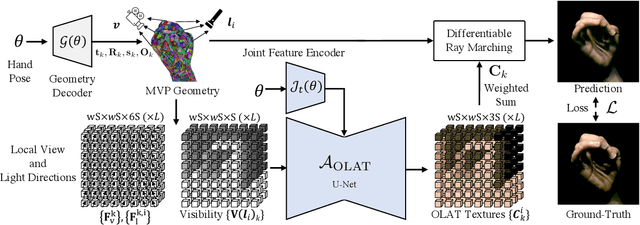

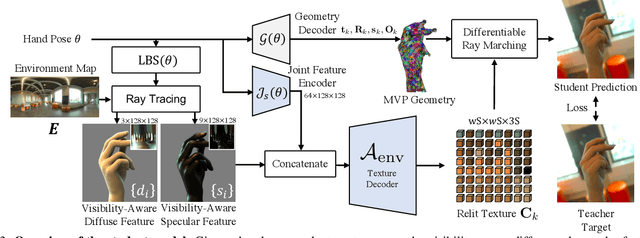
We present the first neural relighting approach for rendering high-fidelity personalized hands that can be animated in real-time under novel illumination. Our approach adopts a teacher-student framework, where the teacher learns appearance under a single point light from images captured in a light-stage, allowing us to synthesize hands in arbitrary illuminations but with heavy compute. Using images rendered by the teacher model as training data, an efficient student model directly predicts appearance under natural illuminations in real-time. To achieve generalization, we condition the student model with physics-inspired illumination features such as visibility, diffuse shading, and specular reflections computed on a coarse proxy geometry, maintaining a small computational overhead. Our key insight is that these features have strong correlation with subsequent global light transport effects, which proves sufficient as conditioning data for the neural relighting network. Moreover, in contrast to bottleneck illumination conditioning, these features are spatially aligned based on underlying geometry, leading to better generalization to unseen illuminations and poses. In our experiments, we demonstrate the efficacy of our illumination feature representations, outperforming baseline approaches. We also show that our approach can photorealistically relight two interacting hands at real-time speeds. https://sh8.io/#/relightable_hands
Embodied Scene-aware Human Pose Estimation
Jun 18, 2022
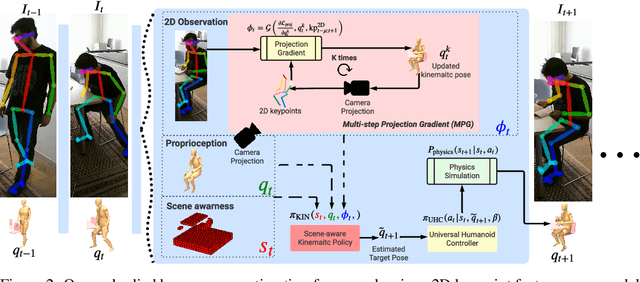


We propose embodied scene-aware human pose estimation where we estimate 3D poses based on a simulated agent's proprioception and scene awareness, along with external third-person observations. Unlike prior methods that often resort to multistage optimization, non-causal inference, and complex contact modeling to estimate human pose and human scene interactions, our method is one stage, causal, and recovers global 3D human poses in a simulated environment. Since 2D third-person observations are coupled with the camera pose, we propose to disentangle the camera pose and use a multi-step projection gradient defined in the global coordinate frame as the movement cue for our embodied agent. Leveraging a physics simulation and prescanned scenes (e.g., 3D mesh), we simulate our agent in everyday environments (libraries, offices, bedrooms, etc.) and equip our agent with environmental sensors to intelligently navigate and interact with scene geometries. Our method also relies only on 2D keypoints and can be trained on synthetic datasets derived from popular human motion databases. To evaluate, we use the popular H36M and PROX datasets and, for the first time, achieve a success rate of 96.7% on the challenging PROX dataset without ever using PROX motion sequences for training.