 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEmbodied Scene-aware Human Pose Estimation
Paper and Code

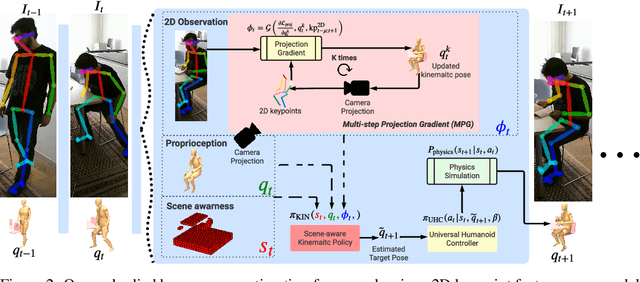


We propose embodied scene-aware human pose estimation where we estimate 3D poses based on a simulated agent's proprioception and scene awareness, along with external third-person observations. Unlike prior methods that often resort to multistage optimization, non-causal inference, and complex contact modeling to estimate human pose and human scene interactions, our method is one stage, causal, and recovers global 3D human poses in a simulated environment. Since 2D third-person observations are coupled with the camera pose, we propose to disentangle the camera pose and use a multi-step projection gradient defined in the global coordinate frame as the movement cue for our embodied agent. Leveraging a physics simulation and prescanned scenes (e.g., 3D mesh), we simulate our agent in everyday environments (libraries, offices, bedrooms, etc.) and equip our agent with environmental sensors to intelligently navigate and interact with scene geometries. Our method also relies only on 2D keypoints and can be trained on synthetic datasets derived from popular human motion databases. To evaluate, we use the popular H36M and PROX datasets and, for the first time, achieve a success rate of 96.7% on the challenging PROX dataset without ever using PROX motion sequences for training.