 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRAIL: Generating Humanoid Loco-Manipulation from 3D Assets and Video Priors
Jun 03, 2026Scaling humanoid loco-manipulation requires robot-compatible demonstrations across diverse objects, whole-body motions, and scene geometries, but teleoperation and motion capture are difficult to scale because each collection depends on physical setups, instrumented actors, and robot operation. We present GRAIL, a digital generation pipeline that remains fully virtual until deployment: it composes 3D assets, simulator-ready scenes, and priors from video foundation models (VFMs) to synthesize interactions without rebuilding physical environments or teleoperating the robot. Rather than reconstructing unconstrained in-the-wild videos, GRAIL starts from fully specified 3D configurations in which object geometry, camera parameters, metric scale, environment depth, and a robot-proportioned character are known before video generation and reused during reconstruction. This privileged setup better conditions 4D recovery, allowing model-based object tracking, human motion estimation, and interaction-aware optimization to reconstruct metric 4D human-object interaction (HOI) trajectories with reduced depth ambiguity and morphology mismatch. We retarget the recovered motions to a humanoid robot and train complementary task-general trackers: an object-aware latent adaptor for manipulation and a scene-aware tracker for terrain traversal. GRAIL produces over 20,000 sequences spanning pick-up, object manipulation, sitting, and terrain traversal. Using only GRAIL-generated data, we train egocentric visual policies through a sim-to-real pipeline and deploy them on a Unitree G1 humanoid, achieving 84\% real-world success on diverse object pick-up and 90\% success on stair-climbing.
MotionBricks: Scalable Real-Time Motions with Modular Latent Generative Model and Smart Primitives
Apr 27, 2026Despite transformative advances in generative motion synthesis, real-time interactive motion control remains dominated by traditional techniques. In this work, we identify two key challenges in bridging research and production: 1) Real-time scalability: Industry applications demand real-time generation of a vast repertoire of motion skills, while generative methods exhibit significant degradation in quality and scalability under real-time computation constraints, and 2) Integration: Industry applications demand fine-grained multi-modal control involving velocity commands, style selection, and precise keyframes, a need largely unmet by existing text- or tag-driven models. To overcome these limitations, we introduce MotionBricks: a large-scale, real-time generative framework with a two-fold solution. First, we propose a large-scale modular latent generative backbone tailored for robust real-time motion generation, effectively modeling a dataset of over 350,000 motion clips with a single model. Second, we introduce smart primitives that provide a unified, robust, and intuitive interface for authoring both navigation and object interaction. Applications can be designed in a plug-and-play manner like assembling bricks without expert animation knowledge. Quantitatively, we show that MotionBricks produces state-of-the-art motion quality on open-source and proprietary datasets of various scales, while also achieving a real-time throughput of 15,000 FPS with 2ms latency. We demonstrate the flexibility and robustness of MotionBricks in a complete production-level animation demo, covering navigation and object-scene interaction across various styles with a unified model. To showcase our framework's application beyond animation, we deploy MotionBricks on the Unitree G1 humanoid robot to demonstrate its flexibility and generalization for real-time robotic control.
Ground Reaction Inertial Poser: Physics-based Human Motion Capture from Sparse IMUs and Insole Pressure Sensors
Mar 17, 2026We propose Ground Reaction Inertial Poser (GRIP), a method that reconstructs physically plausible human motion using four wearable devices. Unlike conventional IMU-only approaches, GRIP combines IMU signals with foot pressure data to capture both body dynamics and ground interactions. Furthermore, rather than relying solely on kinematic estimation, GRIP uses a digital twin of a person, in the form of a synthetic humanoid in a physics simulator, to reconstruct realistic and physically plausible motion. At its core, GRIP consists of two modules: KinematicsNet, which estimates body poses and velocities from sensor data, and DynamicsNet, which controls the humanoid in the simulator using the residual between the KinematicsNet prediction and the simulated humanoid state. To enable robust training and fair evaluation, we introduce a large-scale dataset, Pressure and Inertial Sensing for Human Motion and Interaction (PRISM), that captures diverse human motions with synchronized IMUs and insole pressure sensors. Experimental results show that GRIP outperforms existing IMU-only and IMU-pressure fusion methods across all evaluated datasets, achieving higher global pose accuracy and improved physical consistency.
CHIP: Adaptive Compliance for Humanoid Control through Hindsight Perturbation
Dec 16, 2025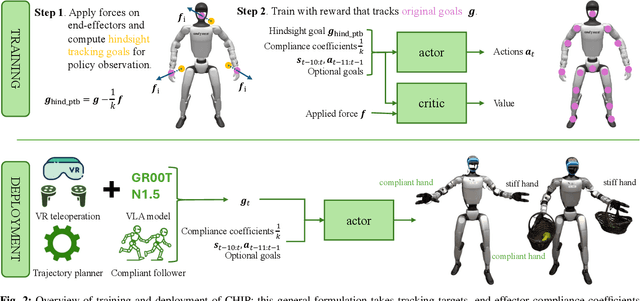
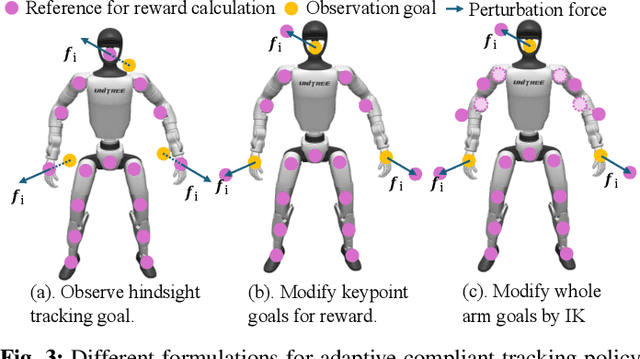
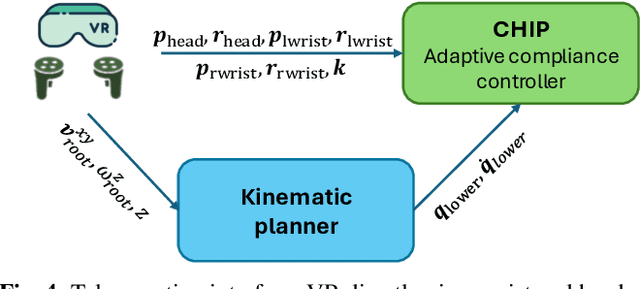

Recent progress in humanoid robots has unlocked agile locomotion skills, including backflipping, running, and crawling. Yet it remains challenging for a humanoid robot to perform forceful manipulation tasks such as moving objects, wiping, and pushing a cart. We propose adaptive Compliance Humanoid control through hIsight Perturbation (CHIP), a plug-and-play module that enables controllable end-effector stiffness while preserving agile tracking of dynamic reference motions. CHIP is easy to implement and requires neither data augmentation nor additional reward tuning. We show that a generalist motion-tracking controller trained with CHIP can perform a diverse set of forceful manipulation tasks that require different end-effector compliance, such as multi-robot collaboration, wiping, box delivery, and door opening.
VIRAL: Visual Sim-to-Real at Scale for Humanoid Loco-Manipulation
Nov 19, 2025
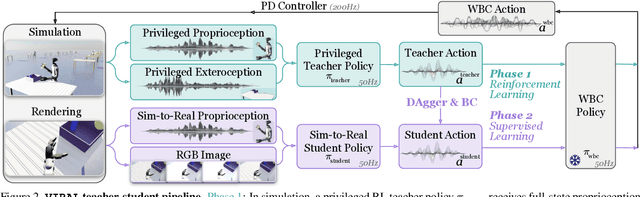
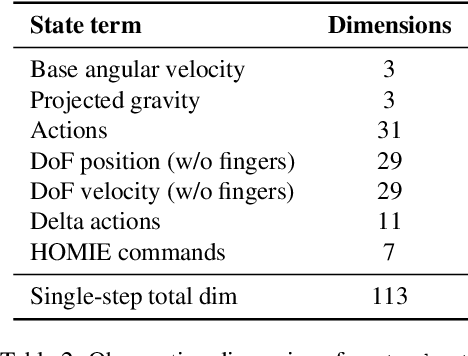

A key barrier to the real-world deployment of humanoid robots is the lack of autonomous loco-manipulation skills. We introduce VIRAL, a visual sim-to-real framework that learns humanoid loco-manipulation entirely in simulation and deploys it zero-shot to real hardware. VIRAL follows a teacher-student design: a privileged RL teacher, operating on full state, learns long-horizon loco-manipulation using a delta action space and reference state initialization. A vision-based student policy is then distilled from the teacher via large-scale simulation with tiled rendering, trained with a mixture of online DAgger and behavior cloning. We find that compute scale is critical: scaling simulation to tens of GPUs (up to 64) makes both teacher and student training reliable, while low-compute regimes often fail. To bridge the sim-to-real gap, VIRAL combines large-scale visual domain randomization over lighting, materials, camera parameters, image quality, and sensor delays--with real-to-sim alignment of the dexterous hands and cameras. Deployed on a Unitree G1 humanoid, the resulting RGB-based policy performs continuous loco-manipulation for up to 54 cycles, generalizing to diverse spatial and appearance variations without any real-world fine-tuning, and approaching expert-level teleoperation performance. Extensive ablations dissect the key design choices required to make RGB-based humanoid loco-manipulation work in practice.
SONIC: Supersizing Motion Tracking for Natural Humanoid Whole-Body Control
Nov 11, 2025Despite the rise of billion-parameter foundation models trained across thousands of GPUs, similar scaling gains have not been shown for humanoid control. Current neural controllers for humanoids remain modest in size, target a limited behavior set, and are trained on a handful of GPUs over several days. We show that scaling up model capacity, data, and compute yields a generalist humanoid controller capable of creating natural and robust whole-body movements. Specifically, we posit motion tracking as a natural and scalable task for humanoid control, leverageing dense supervision from diverse motion-capture data to acquire human motion priors without manual reward engineering. We build a foundation model for motion tracking by scaling along three axes: network size (from 1.2M to 42M parameters), dataset volume (over 100M frames, 700 hours of high-quality motion data), and compute (9k GPU hours). Beyond demonstrating the benefits of scale, we show the practical utility of our model through two mechanisms: (1) a real-time universal kinematic planner that bridges motion tracking to downstream task execution, enabling natural and interactive control, and (2) a unified token space that supports various motion input interfaces, such as VR teleoperation devices, human videos, and vision-language-action (VLA) models, all using the same policy. Scaling motion tracking exhibits favorable properties: performance improves steadily with increased compute and data diversity, and learned representations generalize to unseen motions, establishing motion tracking at scale as a practical foundation for humanoid control.
BFM-Zero: A Promptable Behavioral Foundation Model for Humanoid Control Using Unsupervised Reinforcement Learning
Nov 06, 2025Building Behavioral Foundation Models (BFMs) for humanoid robots has the potential to unify diverse control tasks under a single, promptable generalist policy. However, existing approaches are either exclusively deployed on simulated humanoid characters, or specialized to specific tasks such as tracking. We propose BFM-Zero, a framework that learns an effective shared latent representation that embeds motions, goals, and rewards into a common space, enabling a single policy to be prompted for multiple downstream tasks without retraining. This well-structured latent space in BFM-Zero enables versatile and robust whole-body skills on a Unitree G1 humanoid in the real world, via diverse inference methods, including zero-shot motion tracking, goal reaching, and reward optimization, and few-shot optimization-based adaptation. Unlike prior on-policy reinforcement learning (RL) frameworks, BFM-Zero builds upon recent advancements in unsupervised RL and Forward-Backward (FB) models, which offer an objective-centric, explainable, and smooth latent representation of whole-body motions. We further extend BFM-Zero with critical reward shaping, domain randomization, and history-dependent asymmetric learning to bridge the sim-to-real gap. Those key design choices are quantitatively ablated in simulation. A first-of-its-kind model, BFM-Zero establishes a step toward scalable, promptable behavioral foundation models for whole-body humanoid control.
MaskedManipulator: Versatile Whole-Body Control for Loco-Manipulation
May 25, 2025Humans interact with their world while leveraging precise full-body control to achieve versatile goals. This versatility allows them to solve long-horizon, underspecified problems, such as placing a cup in a sink, by seamlessly sequencing actions like approaching the cup, grasping, transporting it, and finally placing it in the sink. Such goal-driven control can enable new procedural tools for animation systems, enabling users to define partial objectives while the system naturally ``fills in'' the intermediate motions. However, while current methods for whole-body dexterous manipulation in physics-based animation achieve success in specific interaction tasks, they typically employ control paradigms (e.g., detailed kinematic motion tracking, continuous object trajectory following, or direct VR teleoperation) that offer limited versatility for high-level goal specification across the entire coupled human-object system. To bridge this gap, we present MaskedManipulator, a unified and generative policy developed through a two-stage learning approach. First, our system trains a tracking controller to physically reconstruct complex human-object interactions from large-scale human mocap datasets. This tracking controller is then distilled into MaskedManipulator, which provides users with intuitive control over both the character's body and the manipulated object. As a result, MaskedManipulator enables users to specify complex loco-manipulation tasks through intuitive high-level objectives (e.g., target object poses, key character stances), and MaskedManipulator then synthesizes the necessary full-body actions for a physically simulated humanoid to achieve these goals, paving the way for more interactive and life-like virtual characters.
Emergent Active Perception and Dexterity of Simulated Humanoids from Visual Reinforcement Learning
May 18, 2025Human behavior is fundamentally shaped by visual perception -- our ability to interact with the world depends on actively gathering relevant information and adapting our movements accordingly. Behaviors like searching for objects, reaching, and hand-eye coordination naturally emerge from the structure of our sensory system. Inspired by these principles, we introduce Perceptive Dexterous Control (PDC), a framework for vision-driven dexterous whole-body control with simulated humanoids. PDC operates solely on egocentric vision for task specification, enabling object search, target placement, and skill selection through visual cues, without relying on privileged state information (e.g., 3D object positions and geometries). This perception-as-interface paradigm enables learning a single policy to perform multiple household tasks, including reaching, grasping, placing, and articulated object manipulation. We also show that training from scratch with reinforcement learning can produce emergent behaviors such as active search. These results demonstrate how vision-driven control and complex tasks induce human-like behaviors and can serve as the key ingredients in closing the perception-action loop for animation, robotics, and embodied AI.
UniPhys: Unified Planner and Controller with Diffusion for Flexible Physics-Based Character Control
Apr 17, 2025Generating natural and physically plausible character motion remains challenging, particularly for long-horizon control with diverse guidance signals. While prior work combines high-level diffusion-based motion planners with low-level physics controllers, these systems suffer from domain gaps that degrade motion quality and require task-specific fine-tuning. To tackle this problem, we introduce UniPhys, a diffusion-based behavior cloning framework that unifies motion planning and control into a single model. UniPhys enables flexible, expressive character motion conditioned on multi-modal inputs such as text, trajectories, and goals. To address accumulated prediction errors over long sequences, UniPhys is trained with the Diffusion Forcing paradigm, learning to denoise noisy motion histories and handle discrepancies introduced by the physics simulator. This design allows UniPhys to robustly generate physically plausible, long-horizon motions. Through guided sampling, UniPhys generalizes to a wide range of control signals, including unseen ones, without requiring task-specific fine-tuning. Experiments show that UniPhys outperforms prior methods in motion naturalness, generalization, and robustness across diverse control tasks.