 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGround Reaction Inertial Poser: Physics-based Human Motion Capture from Sparse IMUs and Insole Pressure Sensors
Mar 17, 2026We propose Ground Reaction Inertial Poser (GRIP), a method that reconstructs physically plausible human motion using four wearable devices. Unlike conventional IMU-only approaches, GRIP combines IMU signals with foot pressure data to capture both body dynamics and ground interactions. Furthermore, rather than relying solely on kinematic estimation, GRIP uses a digital twin of a person, in the form of a synthetic humanoid in a physics simulator, to reconstruct realistic and physically plausible motion. At its core, GRIP consists of two modules: KinematicsNet, which estimates body poses and velocities from sensor data, and DynamicsNet, which controls the humanoid in the simulator using the residual between the KinematicsNet prediction and the simulated humanoid state. To enable robust training and fair evaluation, we introduce a large-scale dataset, Pressure and Inertial Sensing for Human Motion and Interaction (PRISM), that captures diverse human motions with synchronized IMUs and insole pressure sensors. Experimental results show that GRIP outperforms existing IMU-only and IMU-pressure fusion methods across all evaluated datasets, achieving higher global pose accuracy and improved physical consistency.
DyaDiT: A Multi-Modal Diffusion Transformer for Socially Favorable Dyadic Gesture Generation
Feb 26, 2026Generating realistic conversational gestures are essential for achieving natural, socially engaging interactions with digital humans. However, existing methods typically map a single audio stream to a single speaker's motion, without considering social context or modeling the mutual dynamics between two people engaging in conversation. We present DyaDiT, a multi-modal diffusion transformer that generates contextually appropriate human motion from dyadic audio signals. Trained on Seamless Interaction Dataset, DyaDiT takes dyadic audio with optional social-context tokens to produce context-appropriate motion. It fuses information from both speakers to capture interaction dynamics, uses a motion dictionary to encode motion priors, and can optionally utilize the conversational partner's gestures to produce more responsive motion. We evaluate DyaDiT on standard motion generation metrics and conduct quantitative user studies, demonstrating that it not only surpasses existing methods on objective metrics but is also strongly preferred by users, highlighting its robustness and socially favorable motion generation. Code and models will be released upon acceptance.
Harmony4D: A Video Dataset for In-The-Wild Close Human Interactions
Oct 27, 2024



Understanding how humans interact with each other is key to building realistic multi-human virtual reality systems. This area remains relatively unexplored due to the lack of large-scale datasets. Recent datasets focusing on this issue mainly consist of activities captured entirely in controlled indoor environments with choreographed actions, significantly affecting their diversity. To address this, we introduce Harmony4D, a multi-view video dataset for human-human interaction featuring in-the-wild activities such as wrestling, dancing, MMA, and more. We use a flexible multi-view capture system to record these dynamic activities and provide annotations for human detection, tracking, 2D/3D pose estimation, and mesh recovery for closely interacting subjects. We propose a novel markerless algorithm to track 3D human poses in severe occlusion and close interaction to obtain our annotations with minimal manual intervention. Harmony4D consists of 1.66 million images and 3.32 million human instances from more than 20 synchronized cameras with 208 video sequences spanning diverse environments and 24 unique subjects. We rigorously evaluate existing state-of-the-art methods for mesh recovery and highlight their significant limitations in modeling close interaction scenarios. Additionally, we fine-tune a pre-trained HMR2.0 model on Harmony4D and demonstrate an improved performance of 54.8% PVE in scenes with severe occlusion and contact. Code and data are available at https://jyuntins.github.io/harmony4d/.
Multi-modal estimation of the properties of containers and their content: survey and evaluation
Jul 27, 2021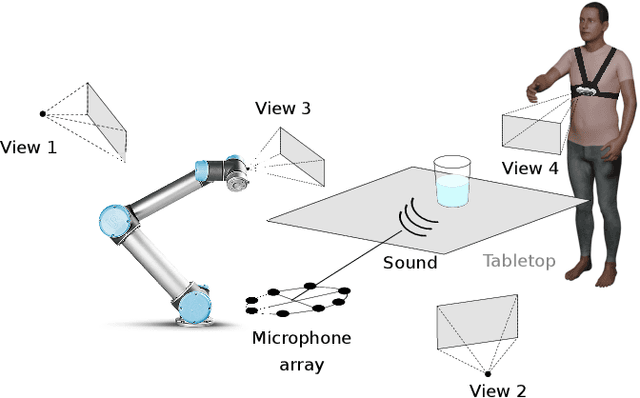


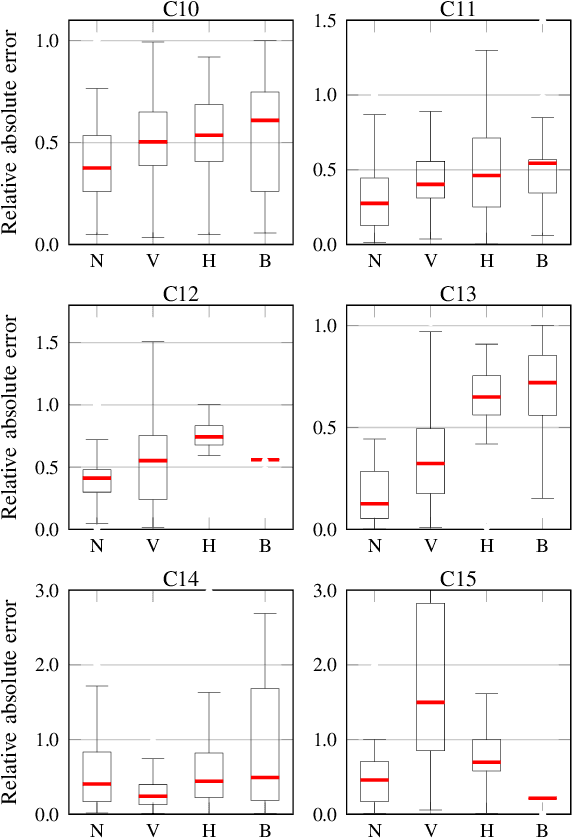
Acoustic and visual sensing can support the contactless estimation of the weight of a container and the amount of its content when the container is manipulated by a person. However, transparencies (both of the container and of the content) and the variability of materials, shapes and sizes make this problem challenging. In this paper, we present an open benchmarking framework and an in-depth comparative analysis of recent methods that estimate the capacity of a container, as well as the type, mass, and amount of its content. These methods use learned and handcrafted features, such as mel-frequency cepstrum coefficients, zero-crossing rate, spectrograms, with different types of classifiers to estimate the type and amount of the content with acoustic data, and geometric approaches with visual data to determine the capacity of the container. Results on a newly distributed dataset show that audio alone is a strong modality and methods achieves a weighted average F1-score up to 81% and 97% for content type and level classification, respectively. Estimating the container capacity with vision-only approaches and filling mass with multi-modal, multi-stage algorithms reaches up to 65% weighted average capacity and mass scores.