 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-modal estimation of the properties of containers and their content: survey and evaluation
Jul 27, 2021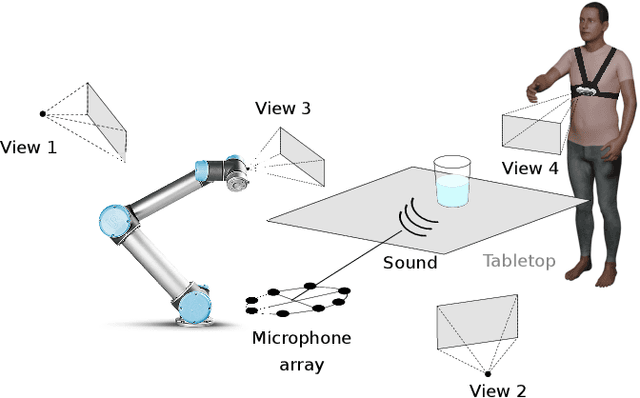


Acoustic and visual sensing can support the contactless estimation of the weight of a container and the amount of its content when the container is manipulated by a person. However, transparencies (both of the container and of the content) and the variability of materials, shapes and sizes make this problem challenging. In this paper, we present an open benchmarking framework and an in-depth comparative analysis of recent methods that estimate the capacity of a container, as well as the type, mass, and amount of its content. These methods use learned and handcrafted features, such as mel-frequency cepstrum coefficients, zero-crossing rate, spectrograms, with different types of classifiers to estimate the type and amount of the content with acoustic data, and geometric approaches with visual data to determine the capacity of the container. Results on a newly distributed dataset show that audio alone is a strong modality and methods achieves a weighted average F1-score up to 81% and 97% for content type and level classification, respectively. Estimating the container capacity with vision-only approaches and filling mass with multi-modal, multi-stage algorithms reaches up to 65% weighted average capacity and mass scores.
Audio classification of the content of food containers and drinking glasses
Mar 30, 2021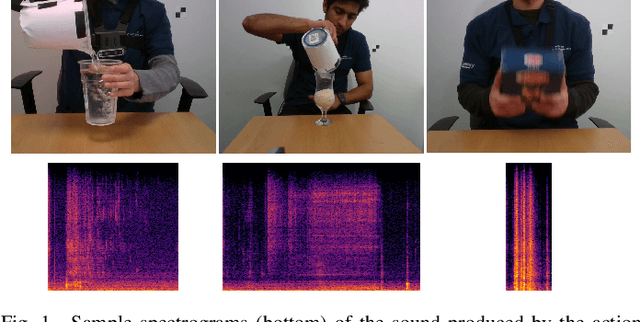
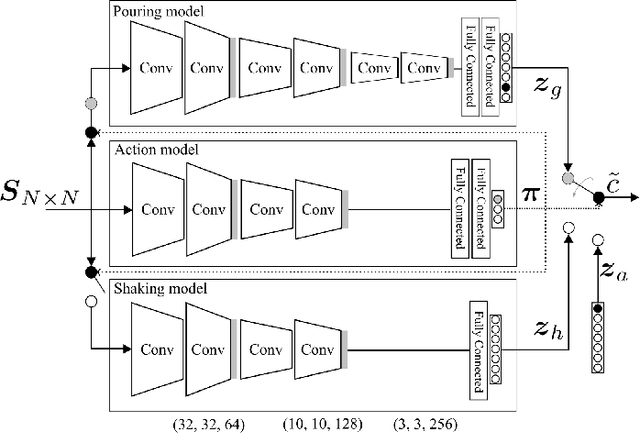
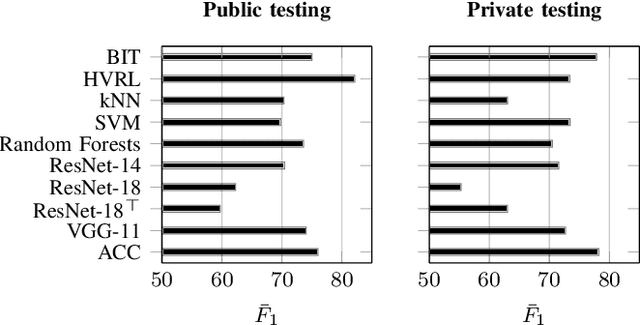
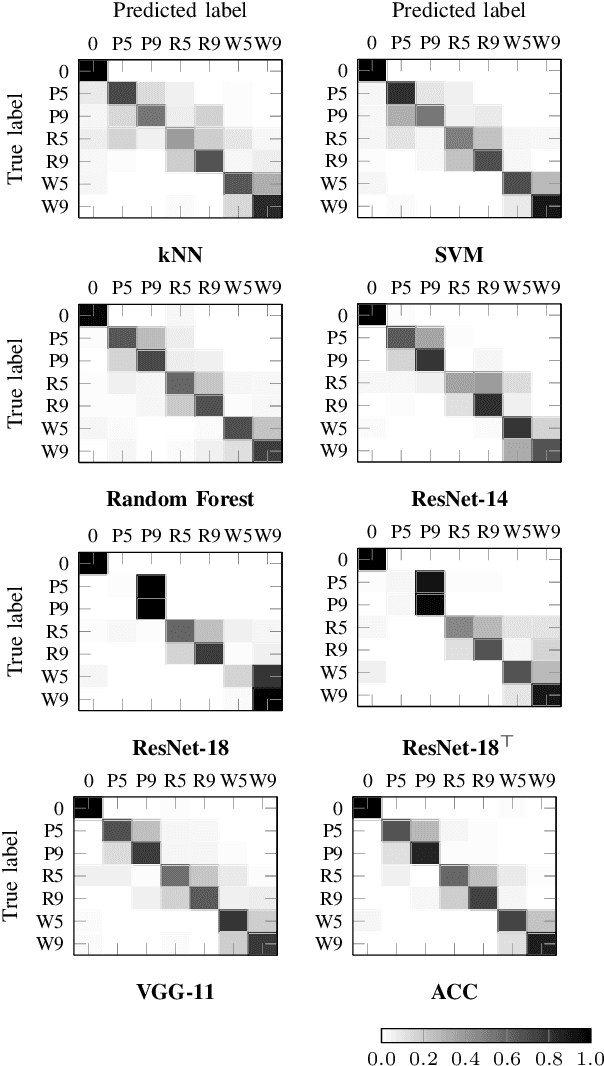
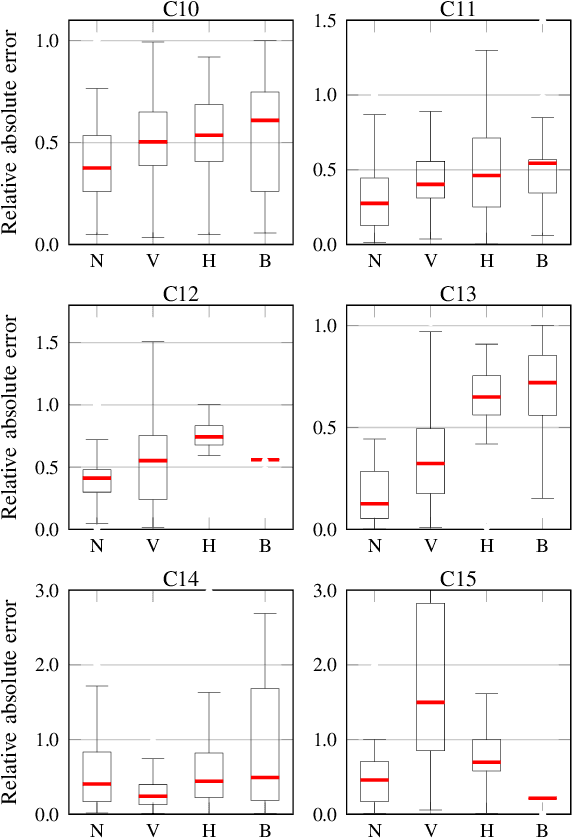
Food containers, drinking glasses and cups handled by a person generate sounds that vary with the type and amount of their content. In this paper, we propose a new model for sound-based classification of the type and amount of content in a container. The proposed model is based on the decomposition of the problem into two steps, namely action recognition and content classification. We consider the scenario of the recent CORSMAL Containers Manipulation dataset and consider two actions (shaking and pouring), and seven material and filling level combinations. The first step identifies the action a person performs while manipulating a container. The second step is an appropriate classifier trained for the specific interaction identified by the first step to classify the amount and type of content. Experiments show that the proposed model achieves 76.02, 78.24, and 41.89 weighted average F1 score on the three test sets, respectively, and outperforms baselines and existing approaches that classify either independently content level and content type or directly the combination of content type and level together.