 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHaptic Stiffness Perception Using Hand Exoskeletons in Tactile Robotic Telemanipulation
Dec 03, 2024Robotic telemanipulation - the human-guided manipulation of remote objects - plays a pivotal role in several applications, from healthcare to operations in harsh environments. While visual feedback from cameras can provide valuable information to the human operator, haptic feedback is essential for accessing specific object properties that are difficult to be perceived by vision, such as stiffness. For the first time, we present a participant study demonstrating that operators can perceive the stiffness of remote objects during real-world telemanipulation with a dexterous robotic hand, when haptic feedback is generated from tactile sensing fingertips. Participants were tasked with squeezing soft objects by teleoperating a robotic hand, using two methods of haptic feedback: one based solely on the measured contact force, while the second also includes the squeezing displacement between the leader and follower devices. Our results demonstrate that operators are indeed capable of discriminating objects of different stiffness, relying on haptic feedback alone and without any visual feedback. Additionally, our findings suggest that the displacement feedback component may enhance discrimination with objects of similar stiffness.
Leveraging Tactile Sensing to Render both Haptic Feedback and Virtual Reality 3D Object Reconstruction in Robotic Telemanipulation
Dec 03, 2024


Dexterous robotic manipulator teleoperation is widely used in many applications, either where it is convenient to keep the human inside the control loop, or to train advanced robot agents. So far, this technology has been used in combination with camera systems with remarkable success. On the other hand, only a limited number of studies have focused on leveraging haptic feedback from tactile sensors in contexts where camera-based systems fail, such as due to self-occlusions or poor light conditions like smoke. This study demonstrates the feasibility of precise pick-and-place teleoperation without cameras by leveraging tactile-based 3D object reconstruction in VR and providing haptic feedback to a blindfolded user. Our preliminary results show that integrating these technologies enables the successful completion of telemanipulation tasks previously dependent on cameras, paving the way for more complex future applications.
DexSkills: Skill Segmentation Using Haptic Data for Learning Autonomous Long-Horizon Robotic Manipulation Tasks
May 06, 2024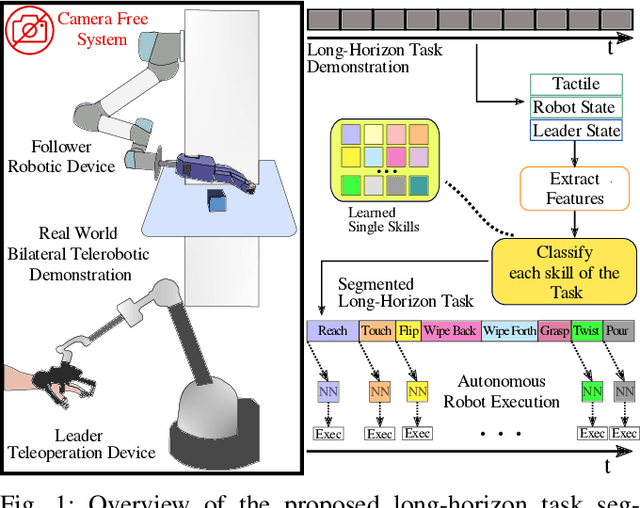
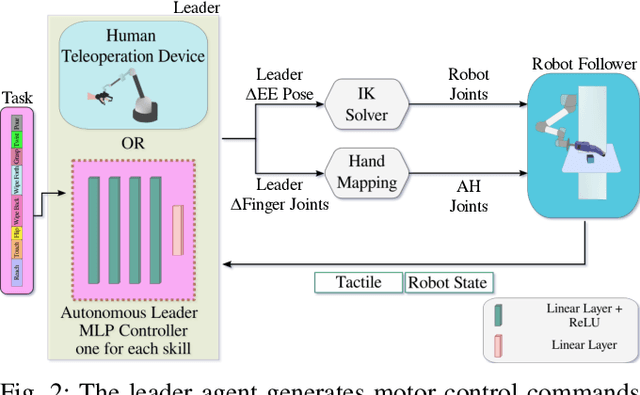
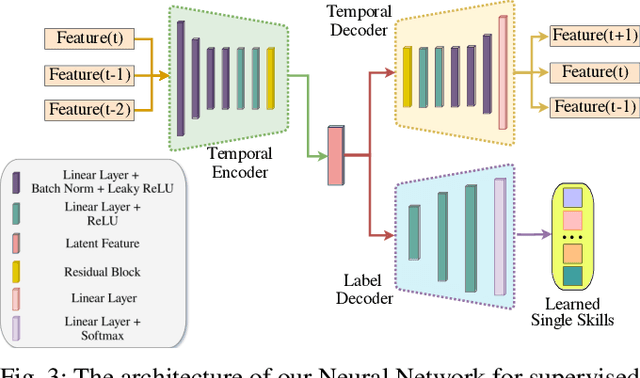
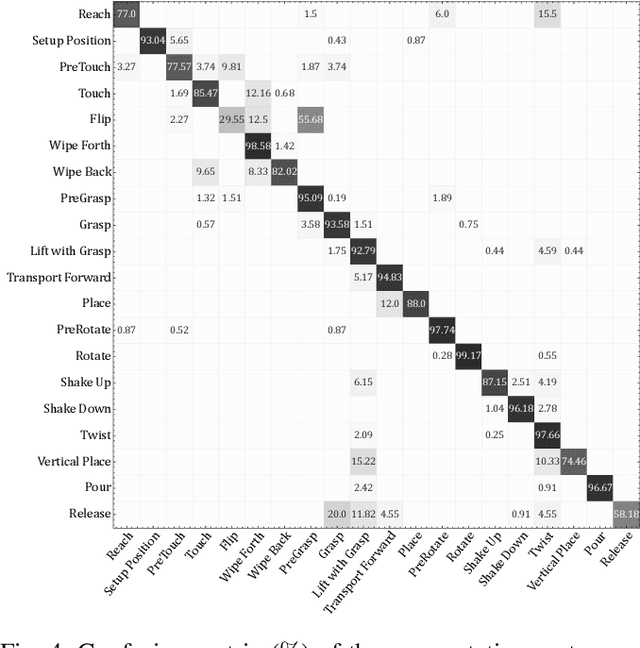
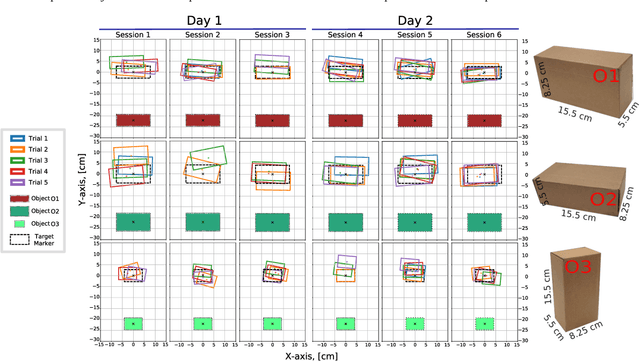
Effective execution of long-horizon tasks with dexterous robotic hands remains a significant challenge in real-world problems. While learning from human demonstrations have shown encouraging results, they require extensive data collection for training. Hence, decomposing long-horizon tasks into reusable primitive skills is a more efficient approach. To achieve so, we developed DexSkills, a novel supervised learning framework that addresses long-horizon dexterous manipulation tasks using primitive skills. DexSkills is trained to recognize and replicate a select set of skills using human demonstration data, which can then segment a demonstrated long-horizon dexterous manipulation task into a sequence of primitive skills to achieve one-shot execution by the robot directly. Significantly, DexSkills operates solely on proprioceptive and tactile data, i.e., haptic data. Our real-world robotic experiments show that DexSkills can accurately segment skills, thereby enabling autonomous robot execution of a diverse range of tasks.
Learning Decoupled Multi-touch Force Estimation, Localization and Stretch for Soft Capacitive E-skin
Mar 10, 2023



Distributed sensor arrays capable of detecting multiple spatially distributed stimuli are considered an important element in the realisation of exteroceptive and proprioceptive soft robots. This paper expands upon the previously presented idea of decoupling the measurements of pressure and location of a local indentation from global deformation, using the overall stretch experienced by a soft capacitive e-skin. We employed machine learning methods to decouple and predict these highly coupled deformation stimuli, collecting data from a soft sensor e-skin which was then fed to a machine learning system comprising of linear regressor, gaussian process regressor, SVM and random forest classifier for stretch, force, detection and localisation respectively. We also studied how the localisation and forces are affected when two forces are applied simultaneously. Soft sensor arrays aided by appropriately chosen machine learning techniques can pave the way to e-skins capable of deciphering multi-modal stimuli in soft robots.
Multi-modal estimation of the properties of containers and their content: survey and evaluation
Jul 27, 2021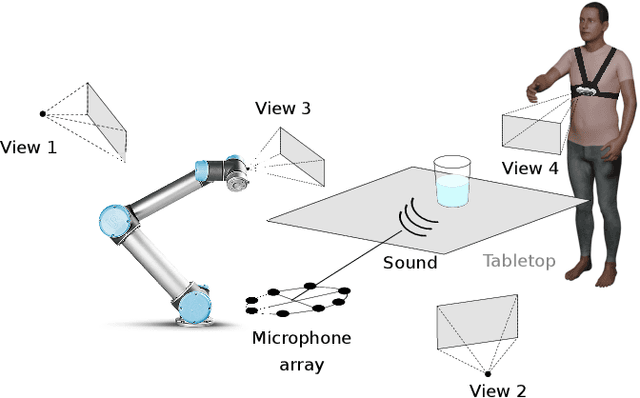


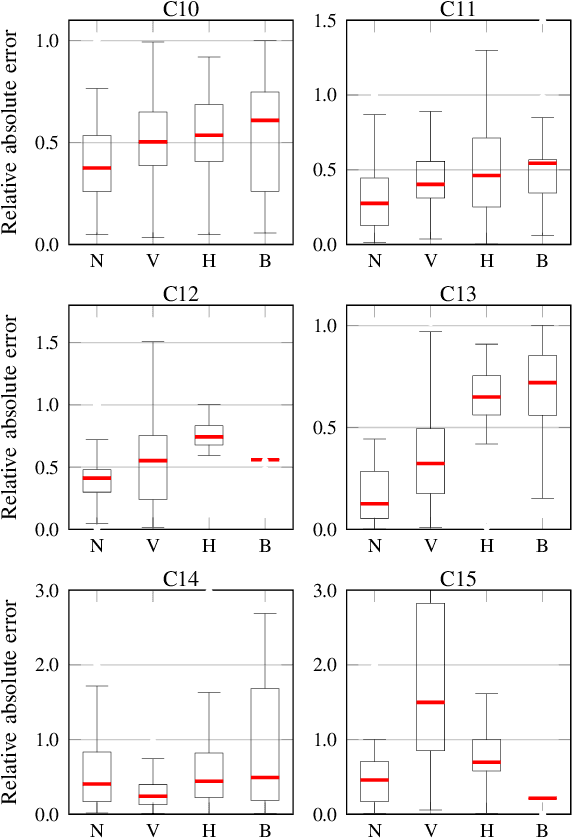
Acoustic and visual sensing can support the contactless estimation of the weight of a container and the amount of its content when the container is manipulated by a person. However, transparencies (both of the container and of the content) and the variability of materials, shapes and sizes make this problem challenging. In this paper, we present an open benchmarking framework and an in-depth comparative analysis of recent methods that estimate the capacity of a container, as well as the type, mass, and amount of its content. These methods use learned and handcrafted features, such as mel-frequency cepstrum coefficients, zero-crossing rate, spectrograms, with different types of classifiers to estimate the type and amount of the content with acoustic data, and geometric approaches with visual data to determine the capacity of the container. Results on a newly distributed dataset show that audio alone is a strong modality and methods achieves a weighted average F1-score up to 81% and 97% for content type and level classification, respectively. Estimating the container capacity with vision-only approaches and filling mass with multi-modal, multi-stage algorithms reaches up to 65% weighted average capacity and mass scores.
Top-1 CORSMAL Challenge 2020 Submission: Filling Mass Estimation Using Multi-modal Observations of Human-robot Handovers
Dec 02, 2020
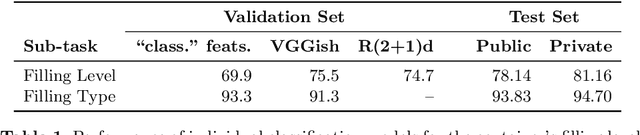
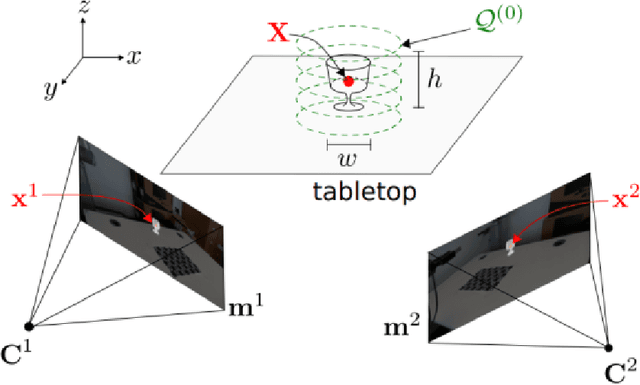
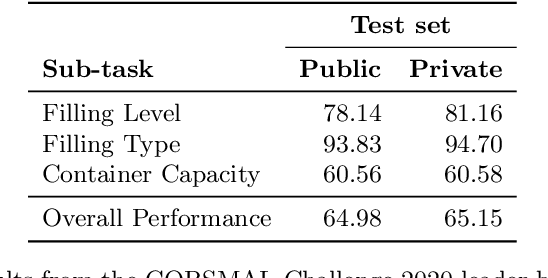
Human-robot object handover is a key skill for the future of human-robot collaboration. CORSMAL 2020 Challenge focuses on the perception part of this problem: the robot needs to estimate the filling mass of a container held by a human. Although there are powerful methods in image processing and audio processing individually, answering such a problem requires processing data from multiple sensors together. The appearance of the container, the sound of the filling, and the depth data provide essential information. We propose a multi-modal method to predict three key indicators of the filling mass: filling type, filling level, and container capacity. These indicators are then combined to estimate the filling mass of a container. Our method obtained Top-1 overall performance among all submissions to CORSMAL 2020 Challenge on both public and private subsets while showing no evidence of overfitting. Our source code is publicly available: https://github.com/v-iashin/CORSMAL