 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSafe Reinforcement Learning for Real-World Engine Control
Jan 28, 2025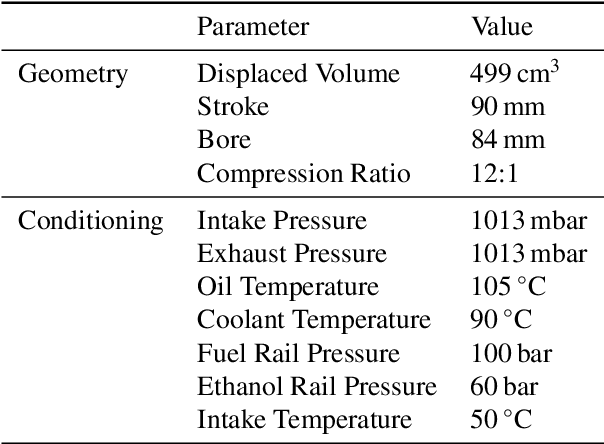
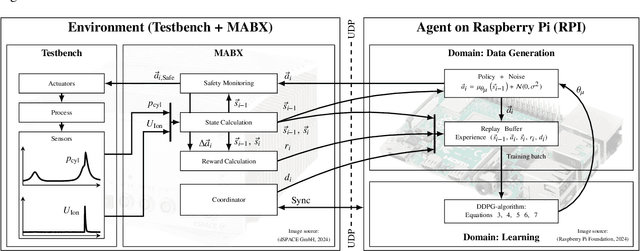
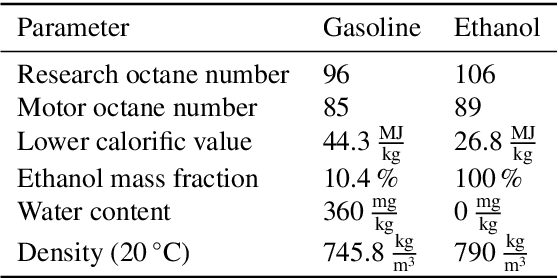
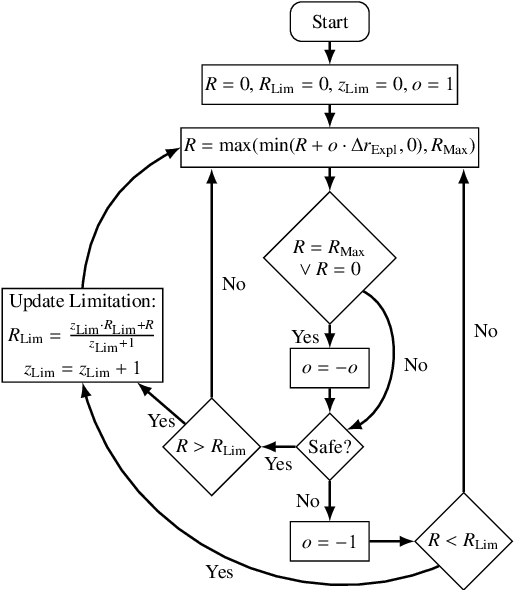
This work introduces a toolchain for applying Reinforcement Learning (RL), specifically the Deep Deterministic Policy Gradient (DDPG) algorithm, in safety-critical real-world environments. As an exemplary application, transient load control is demonstrated on a single-cylinder internal combustion engine testbench in Homogeneous Charge Compression Ignition (HCCI) mode, that offers high thermal efficiency and low emissions. However, HCCI poses challenges for traditional control methods due to its nonlinear, autoregressive, and stochastic nature. RL provides a viable solution, however, safety concerns, such as excessive pressure rise rates, must be addressed when applying to HCCI. A single unsuitable control input can severely damage the engine or cause misfiring and shut down. Additionally, operating limits are not known a priori and must be determined experimentally. To mitigate these risks, real-time safety monitoring based on the k-nearest neighbor algorithm is implemented, enabling safe interaction with the testbench. The feasibility of this approach is demonstrated as the RL agent learns a control policy through interaction with the testbench. A root mean square error of 0.1374 bar is achieved for the indicated mean effective pressure, comparable to neural network-based controllers from the literature. The toolchain's flexibility is further demonstrated by adapting the agent's policy to increase ethanol energy shares, promoting renewable fuel use while maintaining safety. This RL approach addresses the longstanding challenge of applying RL to safety-critical real-world environments. The developed toolchain, with its adaptability and safety mechanisms, paves the way for future applicability of RL in engine testbenches and other safety-critical settings.
Grasping Diverse Objects with Simulated Humanoids
Jul 16, 2024We present a method for controlling a simulated humanoid to grasp an object and move it to follow an object trajectory. Due to the challenges in controlling a humanoid with dexterous hands, prior methods often use a disembodied hand and only consider vertical lifts or short trajectories. This limited scope hampers their applicability for object manipulation required for animation and simulation. To close this gap, we learn a controller that can pick up a large number (>1200) of objects and carry them to follow randomly generated trajectories. Our key insight is to leverage a humanoid motion representation that provides human-like motor skills and significantly speeds up training. Using only simplistic reward, state, and object representations, our method shows favorable scalability on diverse object and trajectories. For training, we do not need dataset of paired full-body motion and object trajectories. At test time, we only require the object mesh and desired trajectories for grasping and transporting. To demonstrate the capabilities of our method, we show state-of-the-art success rates in following object trajectories and generalizing to unseen objects. Code and models will be released.
Real-Time Simulated Avatar from Head-Mounted Sensors
Mar 11, 2024



We present SimXR, a method for controlling a simulated avatar from information (headset pose and cameras) obtained from AR / VR headsets. Due to the challenging viewpoint of head-mounted cameras, the human body is often clipped out of view, making traditional image-based egocentric pose estimation challenging. On the other hand, headset poses provide valuable information about overall body motion, but lack fine-grained details about the hands and feet. To synergize headset poses with cameras, we control a humanoid to track headset movement while analyzing input images to decide body movement. When body parts are seen, the movements of hands and feet will be guided by the images; when unseen, the laws of physics guide the controller to generate plausible motion. We design an end-to-end method that does not rely on any intermediate representations and learns to directly map from images and headset poses to humanoid control signals. To train our method, we also propose a large-scale synthetic dataset created using camera configurations compatible with a commercially available VR headset (Quest 2) and show promising results on real-world captures. To demonstrate the applicability of our framework, we also test it on an AR headset with a forward-facing camera.
RoHM: Robust Human Motion Reconstruction via Diffusion
Jan 16, 2024



We propose RoHM, an approach for robust 3D human motion reconstruction from monocular RGB(-D) videos in the presence of noise and occlusions. Most previous approaches either train neural networks to directly regress motion in 3D or learn data-driven motion priors and combine them with optimization at test time. The former do not recover globally coherent motion and fail under occlusions; the latter are time-consuming, prone to local minima, and require manual tuning. To overcome these shortcomings, we exploit the iterative, denoising nature of diffusion models. RoHM is a novel diffusion-based motion model that, conditioned on noisy and occluded input data, reconstructs complete, plausible motions in consistent global coordinates. Given the complexity of the problem -- requiring one to address different tasks (denoising and infilling) in different solution spaces (local and global motion) -- we decompose it into two sub-tasks and learn two models, one for global trajectory and one for local motion. To capture the correlations between the two, we then introduce a novel conditioning module, combining it with an iterative inference scheme. We apply RoHM to a variety of tasks -- from motion reconstruction and denoising to spatial and temporal infilling. Extensive experiments on three popular datasets show that our method outperforms state-of-the-art approaches qualitatively and quantitatively, while being faster at test time. The code will be available at https://sanweiliti.github.io/ROHM/ROHM.html.
Introducing a Deep Neural Network-based Model Predictive Control Framework for Rapid Controller Implementation
Oct 12, 2023Model Predictive Control (MPC) provides an optimal control solution based on a cost function while allowing for the implementation of process constraints. As a model-based optimal control technique, the performance of MPC strongly depends on the model used where a trade-off between model computation time and prediction performance exists. One solution is the integration of MPC with a machine learning (ML) based process model which are quick to evaluate online. This work presents the experimental implementation of a deep neural network (DNN) based nonlinear MPC for Homogeneous Charge Compression Ignition (HCCI) combustion control. The DNN model consists of a Long Short-Term Memory (LSTM) network surrounded by fully connected layers which was trained using experimental engine data and showed acceptable prediction performance with under 5% error for all outputs. Using this model, the MPC is designed to track the Indicated Mean Effective Pressure (IMEP) and combustion phasing trajectories, while minimizing several parameters. Using the acados software package to enable the real-time implementation of the MPC on an ARM Cortex A72, the optimization calculations are completed within 1.4 ms. The external A72 processor is integrated with the prototyping engine controller using a UDP connection allowing for rapid experimental deployment of the NMPC. The IMEP trajectory following of the developed controller was excellent, with a root-mean-square error of 0.133 bar, in addition to observing process constraints.
Universal Humanoid Motion Representations for Physics-Based Control
Oct 06, 2023
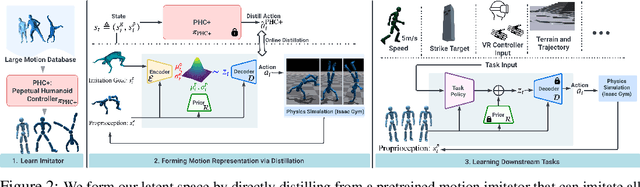
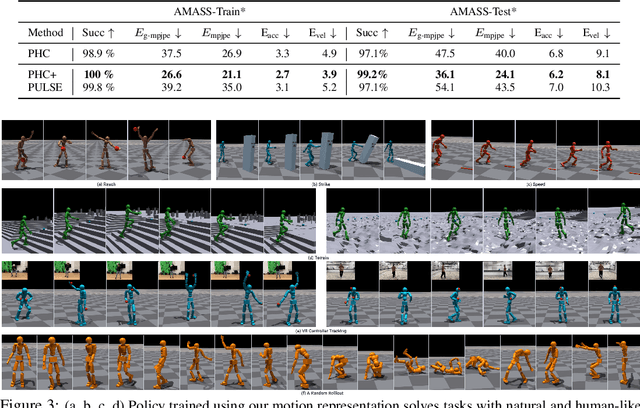

We present a universal motion representation that encompasses a comprehensive range of motor skills for physics-based humanoid control. Due to the high-dimensionality of humanoid control as well as the inherent difficulties in reinforcement learning, prior methods have focused on learning skill embeddings for a narrow range of movement styles (e.g. locomotion, game characters) from specialized motion datasets. This limited scope hampers its applicability in complex tasks. Our work closes this gap, significantly increasing the coverage of motion representation space. To achieve this, we first learn a motion imitator that can imitate all of human motion from a large, unstructured motion dataset. We then create our motion representation by distilling skills directly from the imitator. This is achieved using an encoder-decoder structure with a variational information bottleneck. Additionally, we jointly learn a prior conditioned on proprioception (humanoid's own pose and velocities) to improve model expressiveness and sampling efficiency for downstream tasks. Sampling from the prior, we can generate long, stable, and diverse human motions. Using this latent space for hierarchical RL, we show that our policies solve tasks using natural and realistic human behavior. We demonstrate the effectiveness of our motion representation by solving generative tasks (e.g. strike, terrain traversal) and motion tracking using VR controllers.
Physics-based Motion Retargeting from Sparse Inputs
Jul 04, 2023



Avatars are important to create interactive and immersive experiences in virtual worlds. One challenge in animating these characters to mimic a user's motion is that commercial AR/VR products consist only of a headset and controllers, providing very limited sensor data of the user's pose. Another challenge is that an avatar might have a different skeleton structure than a human and the mapping between them is unclear. In this work we address both of these challenges. We introduce a method to retarget motions in real-time from sparse human sensor data to characters of various morphologies. Our method uses reinforcement learning to train a policy to control characters in a physics simulator. We only require human motion capture data for training, without relying on artist-generated animations for each avatar. This allows us to use large motion capture datasets to train general policies that can track unseen users from real and sparse data in real-time. We demonstrate the feasibility of our approach on three characters with different skeleton structure: a dinosaur, a mouse-like creature and a human. We show that the avatar poses often match the user surprisingly well, despite having no sensor information of the lower body available. We discuss and ablate the important components in our framework, specifically the kinematic retargeting step, the imitation, contact and action reward as well as our asymmetric actor-critic observations. We further explore the robustness of our method in a variety of settings including unbalancing, dancing and sports motions.
QuestEnvSim: Environment-Aware Simulated Motion Tracking from Sparse Sensors
Jun 09, 2023

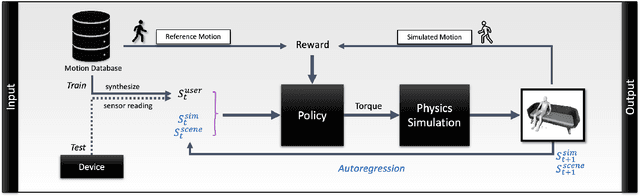

Replicating a user's pose from only wearable sensors is important for many AR/VR applications. Most existing methods for motion tracking avoid environment interaction apart from foot-floor contact due to their complex dynamics and hard constraints. However, in daily life people regularly interact with their environment, e.g. by sitting on a couch or leaning on a desk. Using Reinforcement Learning, we show that headset and controller pose, if combined with physics simulation and environment observations can generate realistic full-body poses even in highly constrained environments. The physics simulation automatically enforces the various constraints necessary for realistic poses, instead of manually specifying them as in many kinematic approaches. These hard constraints allow us to achieve high-quality interaction motions without typical artifacts such as penetration or contact sliding. We discuss three features, the environment representation, the contact reward and scene randomization, crucial to the performance of the method. We demonstrate the generality of the approach through various examples, such as sitting on chairs, a couch and boxes, stepping over boxes, rocking a chair and turning an office chair. We believe these are some of the highest-quality results achieved for motion tracking from sparse sensor with scene interaction.
Perpetual Humanoid Control for Real-time Simulated Avatars
May 24, 2023



We present a physics-based humanoid controller that achieves high-fidelity motion imitation and fault-tolerant behavior in the presence of noisy input (e.g. pose estimates from video or generated from language) and unexpected falls. Our controller scales up to learning ten thousand motion clips without using any external stabilizing forces and learns to naturally recover from fail-state. Given reference motion, our controller can perpetually control simulated avatars without requiring resets. At its core, we propose the progressive multiplicative control policy (PMCP), which dynamically allocates new network capacity to learn harder and harder motion sequences. PMCP allows efficient scaling for learning from large-scale motion databases and adding new tasks, such as fail-state recovery, without catastrophic forgetting. We demonstrate the effectiveness of our controller by using it to imitate noisy poses from video-based pose estimators and language-based motion generators in a live and real-time multi-person avatar use case.
QuestSim: Human Motion Tracking from Sparse Sensors with Simulated Avatars
Sep 20, 2022
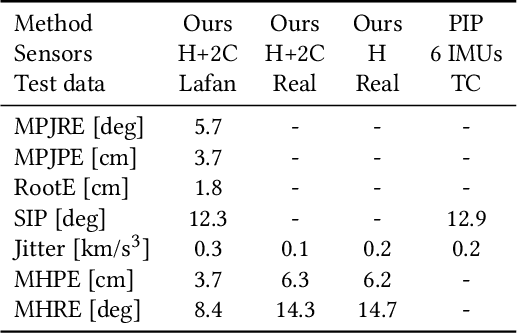
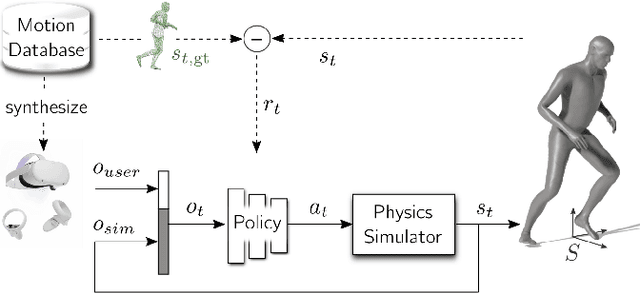

Real-time tracking of human body motion is crucial for interactive and immersive experiences in AR/VR. However, very limited sensor data about the body is available from standalone wearable devices such as HMDs (Head Mounted Devices) or AR glasses. In this work, we present a reinforcement learning framework that takes in sparse signals from an HMD and two controllers, and simulates plausible and physically valid full body motions. Using high quality full body motion as dense supervision during training, a simple policy network can learn to output appropriate torques for the character to balance, walk, and jog, while closely following the input signals. Our results demonstrate surprisingly similar leg motions to ground truth without any observations of the lower body, even when the input is only the 6D transformations of the HMD. We also show that a single policy can be robust to diverse locomotion styles, different body sizes, and novel environments.