 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFauna Sprout: A lightweight, approachable, developer-ready humanoid robot
Jan 26, 2026Recent advances in learned control, large-scale simulation, and generative models have accelerated progress toward general-purpose robotic controllers, yet the field still lacks platforms suitable for safe, expressive, long-term deployment in human environments. Most existing humanoids are either closed industrial systems or academic prototypes that are difficult to deploy and operate around people, limiting progress in robotics. We introduce Sprout, a developer platform designed to address these limitations through an emphasis on safety, expressivity, and developer accessibility. Sprout adopts a lightweight form factor with compliant control, limited joint torques, and soft exteriors to support safe operation in shared human spaces. The platform integrates whole-body control, manipulation with integrated grippers, and virtual-reality-based teleoperation within a unified hardware-software stack. An expressive head further enables social interaction -- a domain that remains underexplored on most utilitarian humanoids. By lowering physical and technical barriers to deployment, Sprout expands access to capable humanoid platforms and provides a practical basis for developing embodied intelligence in real human environments.
emg2pose: A Large and Diverse Benchmark for Surface Electromyographic Hand Pose Estimation
Dec 02, 2024



Hands are the primary means through which humans interact with the world. Reliable and always-available hand pose inference could yield new and intuitive control schemes for human-computer interactions, particularly in virtual and augmented reality. Computer vision is effective but requires one or multiple cameras and can struggle with occlusions, limited field of view, and poor lighting. Wearable wrist-based surface electromyography (sEMG) presents a promising alternative as an always-available modality sensing muscle activities that drive hand motion. However, sEMG signals are strongly dependent on user anatomy and sensor placement, and existing sEMG models have required hundreds of users and device placements to effectively generalize. To facilitate progress on sEMG pose inference, we introduce the emg2pose benchmark, the largest publicly available dataset of high-quality hand pose labels and wrist sEMG recordings. emg2pose contains 2kHz, 16 channel sEMG and pose labels from a 26-camera motion capture rig for 193 users, 370 hours, and 29 stages with diverse gestures - a scale comparable to vision-based hand pose datasets. We provide competitive baselines and challenging tasks evaluating real-world generalization scenarios: held-out users, sensor placements, and stages. emg2pose provides the machine learning community a platform for exploring complex generalization problems, holding potential to significantly enhance the development of sEMG-based human-computer interactions.
Deep Dive into Model-free Reinforcement Learning for Biological and Robotic Systems: Theory and Practice
May 19, 2024


Animals and robots exist in a physical world and must coordinate their bodies to achieve behavioral objectives. With recent developments in deep reinforcement learning, it is now possible for scientists and engineers to obtain sensorimotor strategies (policies) for specific tasks using physically simulated bodies and environments. However, the utility of these methods goes beyond the constraints of a specific task; they offer an exciting framework for understanding the organization of an animal sensorimotor system in connection to its morphology and physical interaction with the environment, as well as for deriving general design rules for sensing and actuation in robotic systems. Algorithms and code implementing both learning agents and environments are increasingly available, but the basic assumptions and choices that go into the formulation of an embodied feedback control problem using deep reinforcement learning may not be immediately apparent. Here, we present a concise exposition of the mathematical and algorithmic aspects of model-free reinforcement learning, specifically through the use of \textit{actor-critic} methods, as a tool for investigating the feedback control underlying animal and robotic behavior.
Universal Humanoid Motion Representations for Physics-Based Control
Oct 06, 2023
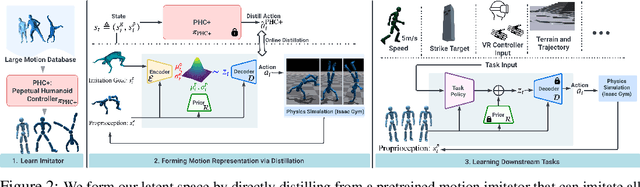
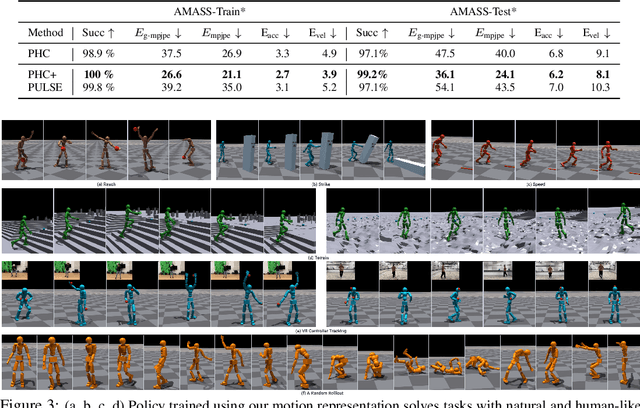

We present a universal motion representation that encompasses a comprehensive range of motor skills for physics-based humanoid control. Due to the high-dimensionality of humanoid control as well as the inherent difficulties in reinforcement learning, prior methods have focused on learning skill embeddings for a narrow range of movement styles (e.g. locomotion, game characters) from specialized motion datasets. This limited scope hampers its applicability in complex tasks. Our work closes this gap, significantly increasing the coverage of motion representation space. To achieve this, we first learn a motion imitator that can imitate all of human motion from a large, unstructured motion dataset. We then create our motion representation by distilling skills directly from the imitator. This is achieved using an encoder-decoder structure with a variational information bottleneck. Additionally, we jointly learn a prior conditioned on proprioception (humanoid's own pose and velocities) to improve model expressiveness and sampling efficiency for downstream tasks. Sampling from the prior, we can generate long, stable, and diverse human motions. Using this latent space for hierarchical RL, we show that our policies solve tasks using natural and realistic human behavior. We demonstrate the effectiveness of our motion representation by solving generative tasks (e.g. strike, terrain traversal) and motion tracking using VR controllers.
Data augmentation for efficient learning from parametric experts
May 23, 2022



We present a simple, yet powerful data-augmentation technique to enable data-efficient learning from parametric experts for reinforcement and imitation learning. We focus on what we call the policy cloning setting, in which we use online or offline queries of an expert or expert policy to inform the behavior of a student policy. This setting arises naturally in a number of problems, for instance as variants of behavior cloning, or as a component of other algorithms such as DAGGER, policy distillation or KL-regularized RL. Our approach, augmented policy cloning (APC), uses synthetic states to induce feedback-sensitivity in a region around sampled trajectories, thus dramatically reducing the environment interactions required for successful cloning of the expert. We achieve highly data-efficient transfer of behavior from an expert to a student policy for high-degrees-of-freedom control problems. We demonstrate the benefit of our method in the context of several existing and widely used algorithms that include policy cloning as a constituent part. Moreover, we highlight the benefits of our approach in two practically relevant settings (a) expert compression, i.e. transfer to a student with fewer parameters; and (b) transfer from privileged experts, i.e. where the expert has a different observation space than the student, usually including access to privileged information.
Imitate and Repurpose: Learning Reusable Robot Movement Skills From Human and Animal Behaviors
Mar 31, 2022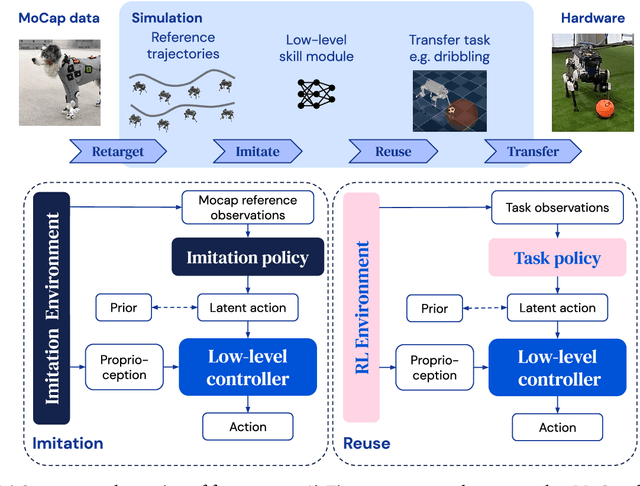

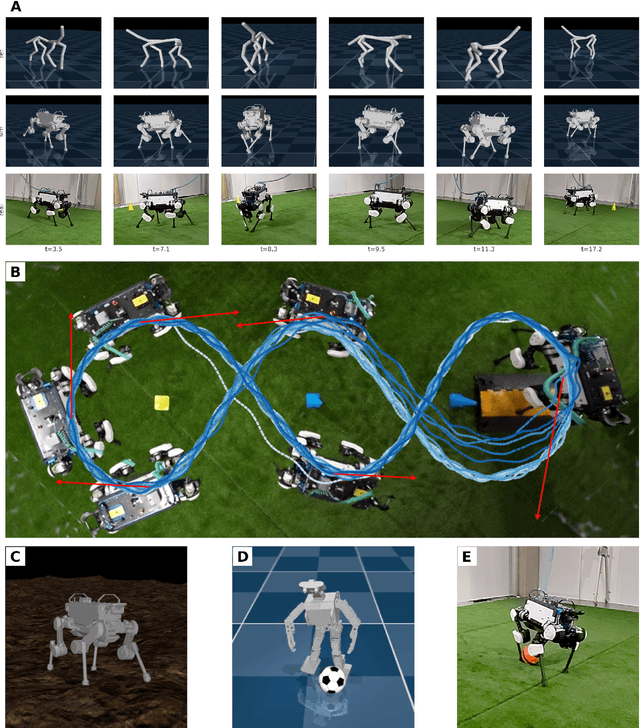
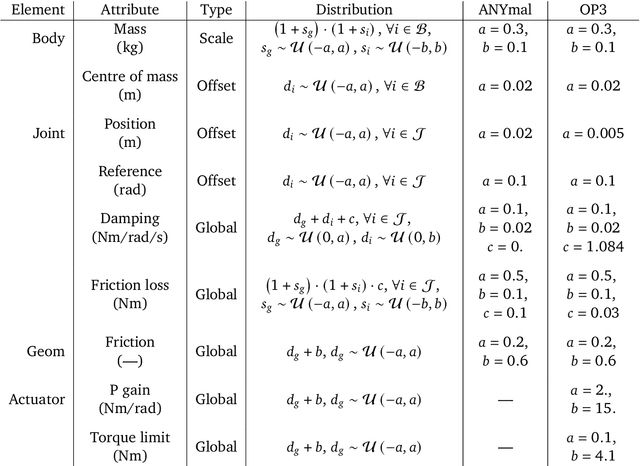
We investigate the use of prior knowledge of human and animal movement to learn reusable locomotion skills for real legged robots. Our approach builds upon previous work on imitating human or dog Motion Capture (MoCap) data to learn a movement skill module. Once learned, this skill module can be reused for complex downstream tasks. Importantly, due to the prior imposed by the MoCap data, our approach does not require extensive reward engineering to produce sensible and natural looking behavior at the time of reuse. This makes it easy to create well-regularized, task-oriented controllers that are suitable for deployment on real robots. We demonstrate how our skill module can be used for imitation, and train controllable walking and ball dribbling policies for both the ANYmal quadruped and OP3 humanoid. These policies are then deployed on hardware via zero-shot simulation-to-reality transfer. Accompanying videos are available at https://bit.ly/robot-npmp.
NeuPL: Neural Population Learning
Feb 15, 2022



Learning in strategy games (e.g. StarCraft, poker) requires the discovery of diverse policies. This is often achieved by iteratively training new policies against existing ones, growing a policy population that is robust to exploit. This iterative approach suffers from two issues in real-world games: a) under finite budget, approximate best-response operators at each iteration needs truncating, resulting in under-trained good-responses populating the population; b) repeated learning of basic skills at each iteration is wasteful and becomes intractable in the presence of increasingly strong opponents. In this work, we propose Neural Population Learning (NeuPL) as a solution to both issues. NeuPL offers convergence guarantees to a population of best-responses under mild assumptions. By representing a population of policies within a single conditional model, NeuPL enables transfer learning across policies. Empirically, we show the generality, improved performance and efficiency of NeuPL across several test domains. Most interestingly, we show that novel strategies become more accessible, not less, as the neural population expands.
Learning Transferable Motor Skills with Hierarchical Latent Mixture Policies
Dec 09, 2021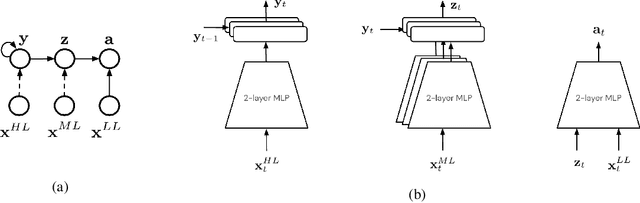
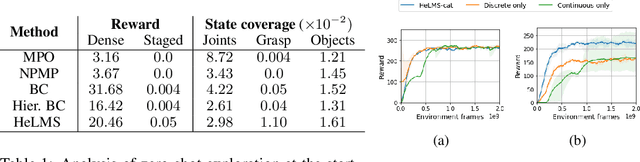
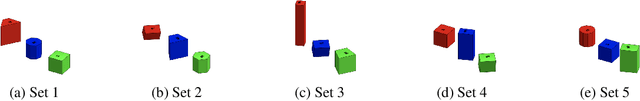
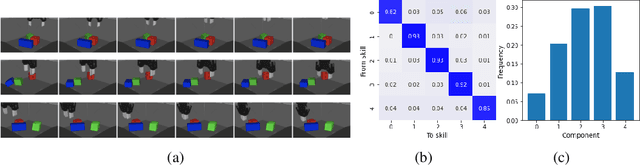
For robots operating in the real world, it is desirable to learn reusable behaviours that can effectively be transferred and adapted to numerous tasks and scenarios. We propose an approach to learn abstract motor skills from data using a hierarchical mixture latent variable model. In contrast to existing work, our method exploits a three-level hierarchy of both discrete and continuous latent variables, to capture a set of high-level behaviours while allowing for variance in how they are executed. We demonstrate in manipulation domains that the method can effectively cluster offline data into distinct, executable behaviours, while retaining the flexibility of a continuous latent variable model. The resulting skills can be transferred and fine-tuned on new tasks, unseen objects, and from state to vision-based policies, yielding better sample efficiency and asymptotic performance compared to existing skill- and imitation-based methods. We further analyse how and when the skills are most beneficial: they encourage directed exploration to cover large regions of the state space relevant to the task, making them most effective in challenging sparse-reward settings.
Divergent representations of ethological visual inputs emerge from supervised, unsupervised, and reinforcement learning
Dec 03, 2021



Artificial neural systems trained using reinforcement, supervised, and unsupervised learning all acquire internal representations of high dimensional input. To what extent these representations depend on the different learning objectives is largely unknown. Here we compare the representations learned by eight different convolutional neural networks, each with identical ResNet architectures and trained on the same family of egocentric images, but embedded within different learning systems. Specifically, the representations are trained to guide action in a compound reinforcement learning task; to predict one or a combination of three task-related targets with supervision; or using one of three different unsupervised objectives. Using representational similarity analysis, we find that the network trained with reinforcement learning differs most from the other networks. Through further analysis using metrics inspired by the neuroscience literature, we find that the model trained with reinforcement learning has a sparse and high-dimensional representation wherein individual images are represented with very different patterns of neural activity. Further analysis suggests these representations may arise in order to guide long-term behavior and goal-seeking in the RL agent. Our results provide insights into how the properties of neural representations are influenced by objective functions and can inform transfer learning approaches.
Evaluating model-based planning and planner amortization for continuous control
Oct 07, 2021
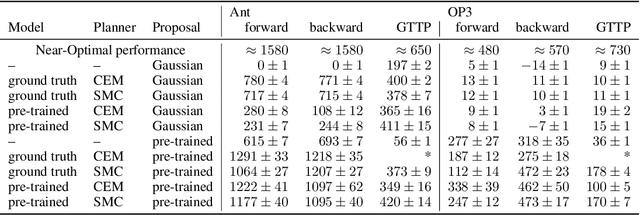
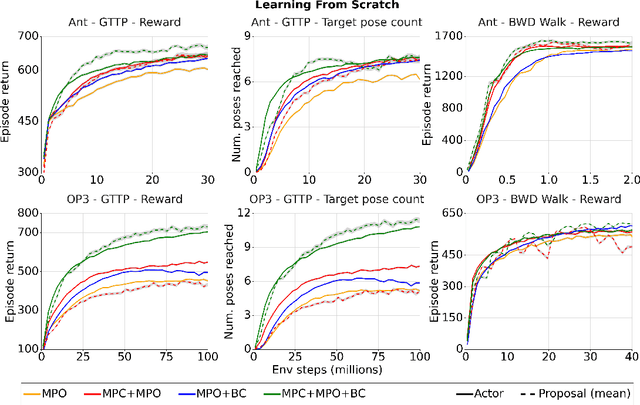
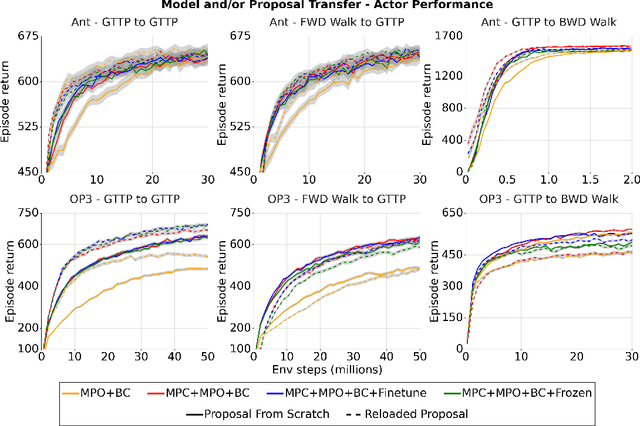
There is a widespread intuition that model-based control methods should be able to surpass the data efficiency of model-free approaches. In this paper we attempt to evaluate this intuition on various challenging locomotion tasks. We take a hybrid approach, combining model predictive control (MPC) with a learned model and model-free policy learning; the learned policy serves as a proposal for MPC. We find that well-tuned model-free agents are strong baselines even for high DoF control problems but MPC with learned proposals and models (trained on the fly or transferred from related tasks) can significantly improve performance and data efficiency in hard multi-task/multi-goal settings. Finally, we show that it is possible to distil a model-based planner into a policy that amortizes the planning computation without any loss of performance. Videos of agents performing different tasks can be seen at https://sites.google.com/view/mbrl-amortization/home.