 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving satellite imagery segmentation using multiple Sentinel-2 revisits
Sep 25, 2024In recent years, analysis of remote sensing data has benefited immensely from borrowing techniques from the broader field of computer vision, such as the use of shared models pre-trained on large and diverse datasets. However, satellite imagery has unique features that are not accounted for in traditional computer vision, such as the existence of multiple revisits of the same location. Here, we explore the best way to use revisits in the framework of fine-tuning pre-trained remote sensing models. We focus on an applied research question of relevance to climate change mitigation -- power substation segmentation -- that is representative of applied uses of pre-trained models more generally. Through extensive tests of different multi-temporal input schemes across diverse model architectures, we find that fusing representations from multiple revisits in the model latent space is superior to other methods of using revisits, including as a form of data augmentation. We also find that a SWIN Transformer-based architecture performs better than U-nets and ViT-based models. We verify the generality of our results on a separate building density estimation task.
Multilevel Interpretability Of Artificial Neural Networks: Leveraging Framework And Methods From Neuroscience
Aug 26, 2024
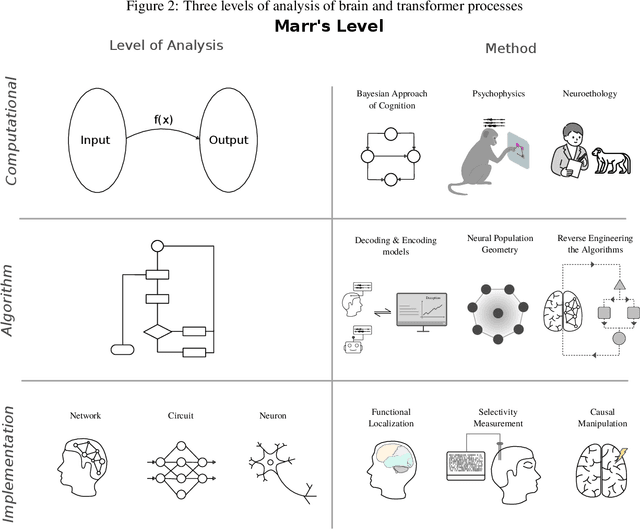
As deep learning systems are scaled up to many billions of parameters, relating their internal structure to external behaviors becomes very challenging. Although daunting, this problem is not new: Neuroscientists and cognitive scientists have accumulated decades of experience analyzing a particularly complex system - the brain. In this work, we argue that interpreting both biological and artificial neural systems requires analyzing those systems at multiple levels of analysis, with different analytic tools for each level. We first lay out a joint grand challenge among scientists who study the brain and who study artificial neural networks: understanding how distributed neural mechanisms give rise to complex cognition and behavior. We then present a series of analytical tools that can be used to analyze biological and artificial neural systems, organizing those tools according to Marr's three levels of analysis: computation/behavior, algorithm/representation, and implementation. Overall, the multilevel interpretability framework provides a principled way to tackle neural system complexity; links structure, computation, and behavior; clarifies assumptions and research priorities at each level; and paves the way toward a unified effort for understanding intelligent systems, may they be biological or artificial.
Testing the Tools of Systems Neuroscience on Artificial Neural Networks
Feb 14, 2022

Neuroscientists apply a range of common analysis tools to recorded neural activity in order to glean insights into how neural circuits implement computations. Despite the fact that these tools shape the progress of the field as a whole, we have little empirical evidence that they are effective at quickly identifying the phenomena of interest. Here I argue that these tools should be explicitly tested and that artificial neural networks (ANNs) are an appropriate testing grounds for them. The recent resurgence of the use of ANNs as models of everything from perception to memory to motor control stems from a rough similarity between artificial and biological neural networks and the ability to train these networks to perform complex high-dimensional tasks. These properties, combined with the ability to perfectly observe and manipulate these systems, makes them well-suited for vetting the tools of systems and cognitive neuroscience. I provide here both a roadmap for performing this testing and a list of tools that are suitable to be tested on ANNs. Using ANNs to reflect on the extent to which these tools provide a productive understanding of neural systems -- and on exactly what understanding should mean here -- has the potential to expedite progress in the study of the brain.
Divergent representations of ethological visual inputs emerge from supervised, unsupervised, and reinforcement learning
Dec 03, 2021



Artificial neural systems trained using reinforcement, supervised, and unsupervised learning all acquire internal representations of high dimensional input. To what extent these representations depend on the different learning objectives is largely unknown. Here we compare the representations learned by eight different convolutional neural networks, each with identical ResNet architectures and trained on the same family of egocentric images, but embedded within different learning systems. Specifically, the representations are trained to guide action in a compound reinforcement learning task; to predict one or a combination of three task-related targets with supervision; or using one of three different unsupervised objectives. Using representational similarity analysis, we find that the network trained with reinforcement learning differs most from the other networks. Through further analysis using metrics inspired by the neuroscience literature, we find that the model trained with reinforcement learning has a sparse and high-dimensional representation wherein individual images are represented with very different patterns of neural activity. Further analysis suggests these representations may arise in order to guide long-term behavior and goal-seeking in the RL agent. Our results provide insights into how the properties of neural representations are influenced by objective functions and can inform transfer learning approaches.
Convolutional Neural Networks as a Model of the Visual System: Past, Present, and Future
Feb 10, 2020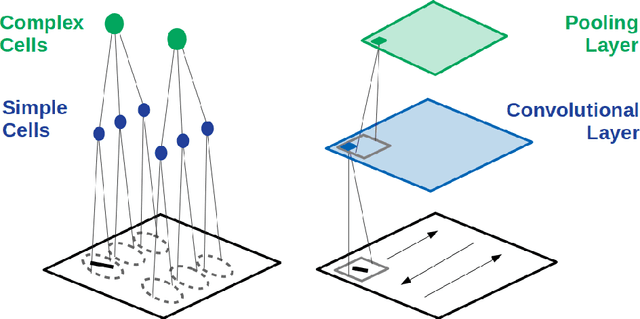


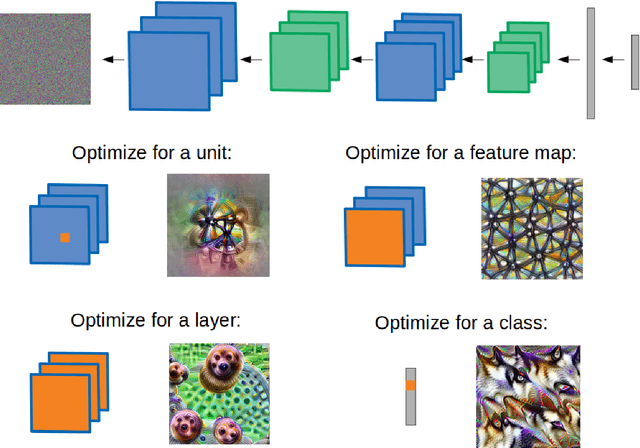
Convolutional neural networks (CNNs) were inspired by early findings in the study of biological vision. They have since become successful tools in computer vision and state-of-the-art models of both neural activity and behavior on visual tasks. This review highlights what, in the context of CNNs, it means to be a good model in computational neuroscience and the various ways models can provide insight. Specifically, it covers the origins of CNNs and the methods by which we validate them as models of biological vision. It then goes on to elaborate on what we can learn about biological vision by understanding and experimenting on CNNs and discusses emerging opportunities for the use of CNNS in vision research beyond basic object recognition.
Feature-based Attention in Convolutional Neural Networks
Dec 09, 2015



Convolutional neural networks (CNNs) have proven effective for image processing tasks, such as object recognition and classification. Recently, CNNs have been enhanced with concepts of attention, similar to those found in biology. Much of this work on attention has focused on effective serial spatial processing. In this paper, I introduce a simple procedure for applying feature-based attention (FBA) to CNNs and compare multiple implementation options. FBA is a top-down signal applied globally to an input image which aides in detecting chosen objects in cluttered or noisy settings. The concept of FBA and the implementation details tested here were derived from what is known (and debated) about biological object- and feature-based attention. The implementations of FBA described here increase performance on challenging object detection tasks using a procedure that is simple, fast, and does not require additional iterative training. Furthermore, the comparisons performed here suggest that a proposed model of biological FBA (the "feature similarity gain model") is effective in increasing performance.