 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultilevel Interpretability Of Artificial Neural Networks: Leveraging Framework And Methods From Neuroscience
Aug 26, 2024
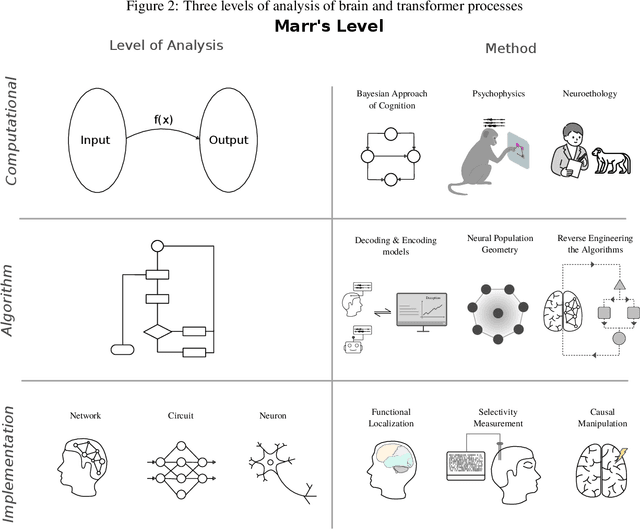
As deep learning systems are scaled up to many billions of parameters, relating their internal structure to external behaviors becomes very challenging. Although daunting, this problem is not new: Neuroscientists and cognitive scientists have accumulated decades of experience analyzing a particularly complex system - the brain. In this work, we argue that interpreting both biological and artificial neural systems requires analyzing those systems at multiple levels of analysis, with different analytic tools for each level. We first lay out a joint grand challenge among scientists who study the brain and who study artificial neural networks: understanding how distributed neural mechanisms give rise to complex cognition and behavior. We then present a series of analytical tools that can be used to analyze biological and artificial neural systems, organizing those tools according to Marr's three levels of analysis: computation/behavior, algorithm/representation, and implementation. Overall, the multilevel interpretability framework provides a principled way to tackle neural system complexity; links structure, computation, and behavior; clarifies assumptions and research priorities at each level; and paves the way toward a unified effort for understanding intelligent systems, may they be biological or artificial.
Rich Human Feedback for Text-to-Image Generation
Dec 15, 2023
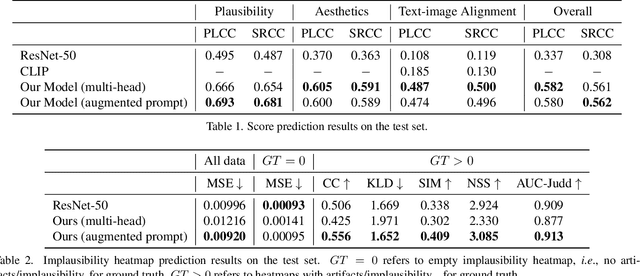
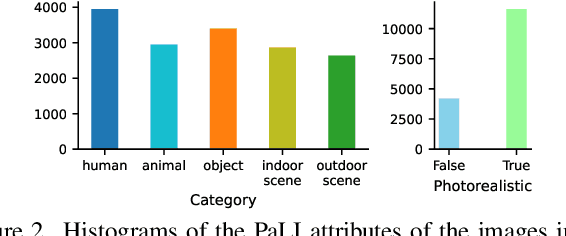
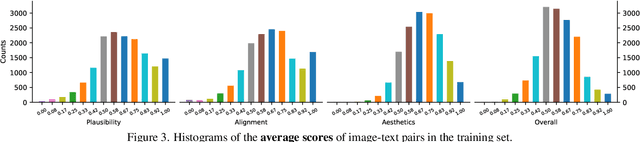
Recent Text-to-Image (T2I) generation models such as Stable Diffusion and Imagen have made significant progress in generating high-resolution images based on text descriptions. However, many generated images still suffer from issues such as artifacts/implausibility, misalignment with text descriptions, and low aesthetic quality. Inspired by the success of Reinforcement Learning with Human Feedback (RLHF) for large language models, prior works collected human-provided scores as feedback on generated images and trained a reward model to improve the T2I generation. In this paper, we enrich the feedback signal by (i) marking image regions that are implausible or misaligned with the text, and (ii) annotating which words in the text prompt are misrepresented or missing on the image. We collect such rich human feedback on 18K generated images and train a multimodal transformer to predict the rich feedback automatically. We show that the predicted rich human feedback can be leveraged to improve image generation, for example, by selecting high-quality training data to finetune and improve the generative models, or by creating masks with predicted heatmaps to inpaint the problematic regions. Notably, the improvements generalize to models (Muse) beyond those used to generate the images on which human feedback data were collected (Stable Diffusion variants).