 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCalibrated Multi-Preference Optimization for Aligning Diffusion Models
Feb 04, 2025



Aligning text-to-image (T2I) diffusion models with preference optimization is valuable for human-annotated datasets, but the heavy cost of manual data collection limits scalability. Using reward models offers an alternative, however, current preference optimization methods fall short in exploiting the rich information, as they only consider pairwise preference distribution. Furthermore, they lack generalization to multi-preference scenarios and struggle to handle inconsistencies between rewards. To address this, we present Calibrated Preference Optimization (CaPO), a novel method to align T2I diffusion models by incorporating the general preference from multiple reward models without human annotated data. The core of our approach involves a reward calibration method to approximate the general preference by computing the expected win-rate against the samples generated by the pretrained models. Additionally, we propose a frontier-based pair selection method that effectively manages the multi-preference distribution by selecting pairs from Pareto frontiers. Finally, we use regression loss to fine-tune diffusion models to match the difference between calibrated rewards of a selected pair. Experimental results show that CaPO consistently outperforms prior methods, such as Direct Preference Optimization (DPO), in both single and multi-reward settings validated by evaluation on T2I benchmarks, including GenEval and T2I-Compbench.
Focus-N-Fix: Region-Aware Fine-Tuning for Text-to-Image Generation
Jan 11, 2025

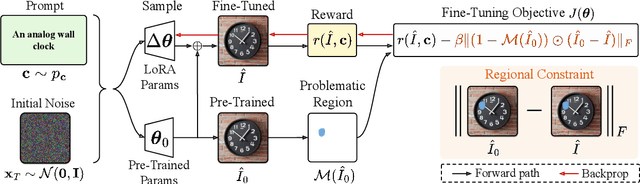
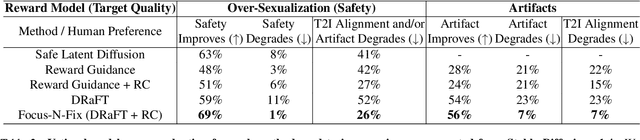
Text-to-image (T2I) generation has made significant advances in recent years, but challenges still remain in the generation of perceptual artifacts, misalignment with complex prompts, and safety. The prevailing approach to address these issues involves collecting human feedback on generated images, training reward models to estimate human feedback, and then fine-tuning T2I models based on the reward models to align them with human preferences. However, while existing reward fine-tuning methods can produce images with higher rewards, they may change model behavior in unexpected ways. For example, fine-tuning for one quality aspect (e.g., safety) may degrade other aspects (e.g., prompt alignment), or may lead to reward hacking (e.g., finding a way to increase rewards without having the intended effect). In this paper, we propose Focus-N-Fix, a region-aware fine-tuning method that trains models to correct only previously problematic image regions. The resulting fine-tuned model generates images with the same high-level structure as the original model but shows significant improvements in regions where the original model was deficient in safety (over-sexualization and violence), plausibility, or other criteria. Our experiments demonstrate that Focus-N-Fix improves these localized quality aspects with little or no degradation to others and typically imperceptible changes in the rest of the image. Disclaimer: This paper contains images that may be overly sexual, violent, offensive, or harmful.
Offline Evaluation of Set-Based Text-to-Image Generation
Oct 22, 2024Text-to-Image (TTI) systems often support people during ideation, the early stages of a creative process when exposure to a broad set of relevant images can help explore the design space. Since ideation is an important subclass of TTI tasks, understanding how to quantitatively evaluate TTI systems according to how well they support ideation is crucial to promoting research and development for these users. However, existing evaluation metrics for TTI remain focused on distributional similarity metrics like Fr\'echet Inception Distance (FID). We take an alternative approach and, based on established methods from ranking evaluation, develop TTI evaluation metrics with explicit models of how users browse and interact with sets of spatially arranged generated images. Our proposed offline evaluation metrics for TTI not only capture how relevant generated images are with respect to the user's ideation need but also take into consideration the diversity and arrangement of the set of generated images. We analyze our proposed family of TTI metrics using human studies on image grids generated by three different TTI systems based on subsets of the widely used benchmarks such as MS-COCO captions and Localized Narratives as well as prompts used in naturalistic settings. Our results demonstrate that grounding metrics in how people use systems is an important and understudied area of benchmark design.
Cropper: Vision-Language Model for Image Cropping through In-Context Learning
Aug 14, 2024



The goal of image cropping is to identify visually appealing crops within an image. Conventional methods rely on specialized architectures trained on specific datasets, which struggle to be adapted to new requirements. Recent breakthroughs in large vision-language models (VLMs) have enabled visual in-context learning without explicit training. However, effective strategies for vision downstream tasks with VLMs remain largely unclear and underexplored. In this paper, we propose an effective approach to leverage VLMs for better image cropping. First, we propose an efficient prompt retrieval mechanism for image cropping to automate the selection of in-context examples. Second, we introduce an iterative refinement strategy to iteratively enhance the predicted crops. The proposed framework, named Cropper, is applicable to a wide range of cropping tasks, including free-form cropping, subject-aware cropping, and aspect ratio-aware cropping. Extensive experiments and a user study demonstrate that Cropper significantly outperforms state-of-the-art methods across several benchmarks.
Beyond Thumbs Up/Down: Untangling Challenges of Fine-Grained Feedback for Text-to-Image Generation
Jun 24, 2024Human feedback plays a critical role in learning and refining reward models for text-to-image generation, but the optimal form the feedback should take for learning an accurate reward function has not been conclusively established. This paper investigates the effectiveness of fine-grained feedback which captures nuanced distinctions in image quality and prompt-alignment, compared to traditional coarse-grained feedback (for example, thumbs up/down or ranking between a set of options). While fine-grained feedback holds promise, particularly for systems catering to diverse societal preferences, we show that demonstrating its superiority to coarse-grained feedback is not automatic. Through experiments on real and synthetic preference data, we surface the complexities of building effective models due to the interplay of model choice, feedback type, and the alignment between human judgment and computational interpretation. We identify key challenges in eliciting and utilizing fine-grained feedback, prompting a reassessment of its assumed benefits and practicality. Our findings -- e.g., that fine-grained feedback can lead to worse models for a fixed budget, in some settings; however, in controlled settings with known attributes, fine grained rewards can indeed be more helpful -- call for careful consideration of feedback attributes and potentially beckon novel modeling approaches to appropriately unlock the potential value of fine-grained feedback in-the-wild.
Parrot: Pareto-optimal Multi-Reward Reinforcement Learning Framework for Text-to-Image Generation
Jan 11, 2024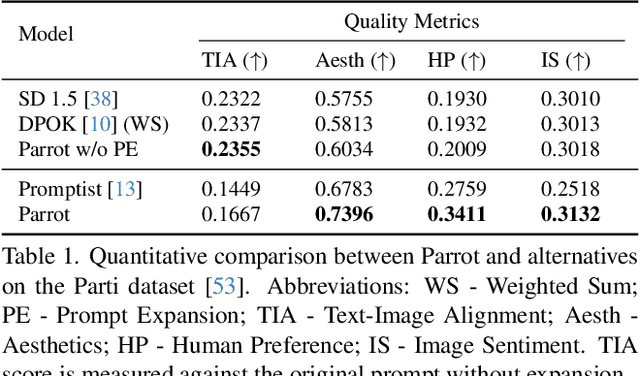
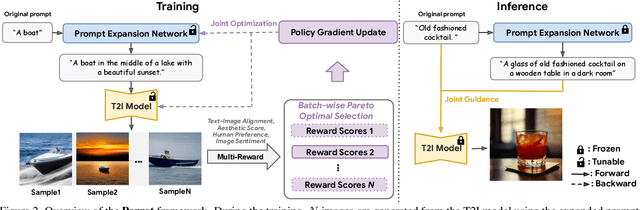


Recent works demonstrate that using reinforcement learning (RL) with quality rewards can enhance the quality of generated images in text-to-image (T2I) generation. However, a simple aggregation of multiple rewards may cause over-optimization in certain metrics and degradation in others, and it is challenging to manually find the optimal weights. An effective strategy to jointly optimize multiple rewards in RL for T2I generation is highly desirable. This paper introduces Parrot, a novel multi-reward RL framework for T2I generation. Through the use of the batch-wise Pareto optimal selection, Parrot automatically identifies the optimal trade-off among different rewards during the RL optimization of the T2I generation. Additionally, Parrot employs a joint optimization approach for the T2I model and the prompt expansion network, facilitating the generation of quality-aware text prompts, thus further enhancing the final image quality. To counteract the potential catastrophic forgetting of the original user prompt due to prompt expansion, we introduce original prompt centered guidance at inference time, ensuring that the generated image remains faithful to the user input. Extensive experiments and a user study demonstrate that Parrot outperforms several baseline methods across various quality criteria, including aesthetics, human preference, image sentiment, and text-image alignment.
Rich Human Feedback for Text-to-Image Generation
Dec 15, 2023
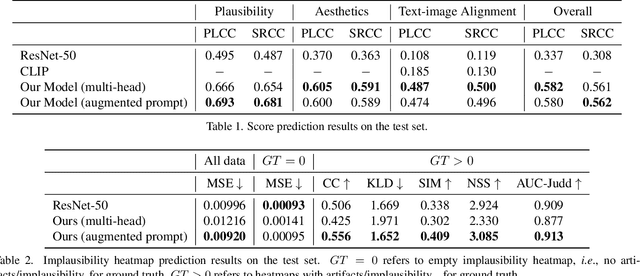
Recent Text-to-Image (T2I) generation models such as Stable Diffusion and Imagen have made significant progress in generating high-resolution images based on text descriptions. However, many generated images still suffer from issues such as artifacts/implausibility, misalignment with text descriptions, and low aesthetic quality. Inspired by the success of Reinforcement Learning with Human Feedback (RLHF) for large language models, prior works collected human-provided scores as feedback on generated images and trained a reward model to improve the T2I generation. In this paper, we enrich the feedback signal by (i) marking image regions that are implausible or misaligned with the text, and (ii) annotating which words in the text prompt are misrepresented or missing on the image. We collect such rich human feedback on 18K generated images and train a multimodal transformer to predict the rich feedback automatically. We show that the predicted rich human feedback can be leveraged to improve image generation, for example, by selecting high-quality training data to finetune and improve the generative models, or by creating masks with predicted heatmaps to inpaint the problematic regions. Notably, the improvements generalize to models (Muse) beyond those used to generate the images on which human feedback data were collected (Stable Diffusion variants).
UniAR: Unifying Human Attention and Response Prediction on Visual Content
Dec 15, 2023Progress in human behavior modeling involves understanding both implicit, early-stage perceptual behavior such as human attention and explicit, later-stage behavior such as subjective ratings/preferences. Yet, most prior research has focused on modeling implicit and explicit human behavior in isolation. Can we build a unified model of human attention and preference behavior that reliably works across diverse types of visual content? Such a model would enable predicting subjective feedback such as overall satisfaction or aesthetic quality ratings, along with the underlying human attention or interaction heatmaps and viewing order, enabling designers and content-creation models to optimize their creation for human-centric improvements. In this paper, we propose UniAR -- a unified model that predicts both implicit and explicit human behavior across different types of visual content. UniAR leverages a multimodal transformer, featuring distinct prediction heads for each facet, and predicts attention heatmap, scanpath or viewing order, and subjective rating/preference. We train UniAR on diverse public datasets spanning natural images, web pages and graphic designs, and achieve leading performance on multiple benchmarks across different image domains and various behavior modeling tasks. Potential applications include providing instant feedback on the effectiveness of UIs/digital designs/images, and serving as a reward model to further optimize design/image creation.
OriWheelBot: An origami-wheeled robot
Sep 29, 2023Origami-inspired robots with multiple advantages, such as being lightweight, requiring less assembly, and exhibiting exceptional deformability, have received substantial and sustained attention. However, the existing origami-inspired robots are usually of limited functionalities and developing feature-rich robots is very challenging. Here, we report an origami-wheeled robot (OriWheelBot) with variable width and outstanding sand walking versatility. The OriWheelBot's ability to adjust wheel width over obstacles is achieved by origami wheels made of Miura origami. An improved version, called iOriWheelBot, is also developed to automatically judge the width of the obstacles. Three actions, namely direct pass, variable width pass, and direct return, will be carried out depending on the width of the channel between the obstacles. We have identified two motion mechanisms, i.e., sand-digging and sand-pushing, with the latter being more conducive to walking on the sand. We have systematically examined numerous sand walking characteristics, including carrying loads, climbing a slope, walking on a slope, and navigating sand pits, small rocks, and sand traps. The OriWheelBot can change its width by 40%, has a loading-carrying ratio of 66.7% on flat sand and can climb a 17-degree sand incline. The OriWheelBot can be useful for planetary subsurface exploration and disaster area rescue.
Deep Saliency Prior for Reducing Visual Distraction
Sep 05, 2021
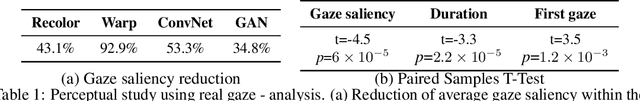


Using only a model that was trained to predict where people look at images, and no additional training data, we can produce a range of powerful editing effects for reducing distraction in images. Given an image and a mask specifying the region to edit, we backpropagate through a state-of-the-art saliency model to parameterize a differentiable editing operator, such that the saliency within the masked region is reduced. We demonstrate several operators, including: a recoloring operator, which learns to apply a color transform that camouflages and blends distractors into their surroundings; a warping operator, which warps less salient image regions to cover distractors, gradually collapsing objects into themselves and effectively removing them (an effect akin to inpainting); a GAN operator, which uses a semantic prior to fully replace image regions with plausible, less salient alternatives. The resulting effects are consistent with cognitive research on the human visual system (e.g., since color mismatch is salient, the recoloring operator learns to harmonize objects' colors with their surrounding to reduce their saliency), and, importantly, are all achieved solely through the guidance of the pretrained saliency model, with no additional supervision. We present results on a variety of natural images and conduct a perceptual study to evaluate and validate the changes in viewers' eye-gaze between the original images and our edited results.