 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre they lovers or friends? Evaluating LLMs' Social Reasoning in English and Korean Dialogues
Oct 21, 2025As large language models (LLMs) are increasingly used in human-AI interactions, their social reasoning capabilities in interpersonal contexts are critical. We introduce SCRIPTS, a 1k-dialogue dataset in English and Korean, sourced from movie scripts. The task involves evaluating models' social reasoning capability to infer the interpersonal relationships (e.g., friends, sisters, lovers) between speakers in each dialogue. Each dialogue is annotated with probabilistic relational labels (Highly Likely, Less Likely, Unlikely) by native (or equivalent) Korean and English speakers from Korea and the U.S. Evaluating nine models on our task, current proprietary LLMs achieve around 75-80% on the English dataset, whereas their performance on Korean drops to 58-69%. More strikingly, models select Unlikely relationships in 10-25% of their responses. Furthermore, we find that thinking models and chain-of-thought prompting, effective for general reasoning, provide minimal benefits for social reasoning and occasionally amplify social biases. Our findings reveal significant limitations in current LLMs' social reasoning capabilities, highlighting the need for efforts to develop socially-aware language models.
Death of the Novel(ty): Beyond n-Gram Novelty as a Metric for Textual Creativity
Sep 26, 2025N-gram novelty is widely used to evaluate language models' ability to generate text outside of their training data. More recently, it has also been adopted as a metric for measuring textual creativity. However, theoretical work on creativity suggests that this approach may be inadequate, as it does not account for creativity's dual nature: novelty (how original the text is) and appropriateness (how sensical and pragmatic it is). We investigate the relationship between this notion of creativity and n-gram novelty through 7542 expert writer annotations (n=26) of novelty, pragmaticality, and sensicality via close reading of human and AI-generated text. We find that while n-gram novelty is positively associated with expert writer-judged creativity, ~91% of top-quartile expressions by n-gram novelty are not judged as creative, cautioning against relying on n-gram novelty alone. Furthermore, unlike human-written text, higher n-gram novelty in open-source LLMs correlates with lower pragmaticality. In an exploratory study with frontier close-source models, we additionally confirm that they are less likely to produce creative expressions than humans. Using our dataset, we test whether zero-shot, few-shot, and finetuned models are able to identify creative expressions (a positive aspect of writing) and non-pragmatic ones (a negative aspect). Overall, frontier LLMs exhibit performance much higher than random but leave room for improvement, especially struggling to identify non-pragmatic expressions. We further find that LLM-as-a-Judge novelty scores from the best-performing model were predictive of expert writer preferences.
Vision-and-Language Training Helps Deploy Taxonomic Knowledge but Does Not Fundamentally Alter It
Jul 17, 2025Does vision-and-language (VL) training change the linguistic representations of language models in meaningful ways? Most results in the literature have shown inconsistent or marginal differences, both behaviorally and representationally. In this work, we start from the hypothesis that the domain in which VL training could have a significant effect is lexical-conceptual knowledge, in particular its taxonomic organization. Through comparing minimal pairs of text-only LMs and their VL-trained counterparts, we first show that the VL models often outperform their text-only counterparts on a text-only question-answering task that requires taxonomic understanding of concepts mentioned in the questions. Using an array of targeted behavioral and representational analyses, we show that the LMs and VLMs do not differ significantly in terms of their taxonomic knowledge itself, but they differ in how they represent questions that contain concepts in a taxonomic relation vs. a non-taxonomic relation. This implies that the taxonomic knowledge itself does not change substantially through additional VL training, but VL training does improve the deployment of this knowledge in the context of a specific task, even when the presentation of the task is purely linguistic.
Is analogy enough to draw novel adjective-noun inferences?
Mar 31, 2025Recent work (Ross et al., 2025, 2024) has argued that the ability of humans and LLMs respectively to generalize to novel adjective-noun combinations shows that they each have access to a compositional mechanism to determine the phrase's meaning and derive inferences. We study whether these inferences can instead be derived by analogy to known inferences, without need for composition. We investigate this by (1) building a model of analogical reasoning using similarity over lexical items, and (2) asking human participants to reason by analogy. While we find that this strategy works well for a large proportion of the dataset of Ross et al. (2025), there are novel combinations for which both humans and LLMs derive convergent inferences but which are not well handled by analogy. We thus conclude that the mechanism humans and LLMs use to generalize in these cases cannot be fully reduced to analogy, and likely involves composition.
Transformers Struggle to Learn to Search
Dec 06, 2024



Search is an ability foundational in many important tasks, and recent studies have shown that large language models (LLMs) struggle to perform search robustly. It is unknown whether this inability is due to a lack of data, insufficient model parameters, or fundamental limitations of the transformer architecture. In this work, we use the foundational graph connectivity problem as a testbed to generate effectively limitless high-coverage data to train small transformers and test whether they can learn to perform search. We find that, when given the right training distribution, the transformer is able to learn to search. We analyze the algorithm that the transformer has learned through a novel mechanistic interpretability technique that enables us to extract the computation graph from the trained model. We find that for each vertex in the input graph, transformers compute the set of vertices reachable from that vertex. Each layer then progressively expands these sets, allowing the model to search over a number of vertices exponential in the number of layers. However, we find that as the input graph size increases, the transformer has greater difficulty in learning the task. This difficulty is not resolved even as the number of parameters is increased, suggesting that increasing model scale will not lead to robust search abilities. We also find that performing search in-context (i.e., chain-of-thought) does not resolve this inability to learn to search on larger graphs.
Is artificial intelligence still intelligence? LLMs generalize to novel adjective-noun pairs, but don't mimic the full human distribution
Oct 23, 2024



Inferences from adjective-noun combinations like "Is artificial intelligence still intelligence?" provide a good test bed for LLMs' understanding of meaning and compositional generalization capability, since there are many combinations which are novel to both humans and LLMs but nevertheless elicit convergent human judgments. We study a range of LLMs and find that the largest models we tested are able to draw human-like inferences when the inference is determined by context and can generalize to unseen adjective-noun combinations. We also propose three methods to evaluate LLMs on these inferences out of context, where there is a distribution of human-like answers rather than a single correct answer. We find that LLMs show a human-like distribution on at most 75\% of our dataset, which is promising but still leaves room for improvement.
Generating novel experimental hypotheses from language models: A case study on cross-dative generalization
Aug 09, 2024Neural network language models (LMs) have been shown to successfully capture complex linguistic knowledge. However, their utility for understanding language acquisition is still debated. We contribute to this debate by presenting a case study where we use LMs as simulated learners to derive novel experimental hypotheses to be tested with humans. We apply this paradigm to study cross-dative generalization (CDG): productive generalization of novel verbs across dative constructions (she pilked me the ball/she pilked the ball to me) -- acquisition of which is known to involve a large space of contextual features -- using LMs trained on child-directed speech. We specifically ask: "what properties of the training exposure facilitate a novel verb's generalization to the (unmodeled) alternate construction?" To answer this, we systematically vary the exposure context in which a novel dative verb occurs in terms of the properties of the theme and recipient, and then analyze the LMs' usage of the novel verb in the unmodeled dative construction. We find LMs to replicate known patterns of children's CDG, as a precondition to exploring novel hypotheses. Subsequent simulations reveal a nuanced role of the features of the novel verbs' exposure context on the LMs' CDG. We find CDG to be facilitated when the first postverbal argument of the exposure context is pronominal, definite, short, and conforms to the prototypical animacy expectations of the exposure dative. These patterns are characteristic of harmonic alignment in datives, where the argument with features ranking higher on the discourse prominence scale tends to precede the other. This gives rise to a novel hypothesis that CDG is facilitated insofar as the features of the exposure context -- in particular, its first postverbal argument -- are harmonically aligned. We conclude by proposing future experiments that can test this hypothesis in children.
Beyond Thumbs Up/Down: Untangling Challenges of Fine-Grained Feedback for Text-to-Image Generation
Jun 24, 2024Human feedback plays a critical role in learning and refining reward models for text-to-image generation, but the optimal form the feedback should take for learning an accurate reward function has not been conclusively established. This paper investigates the effectiveness of fine-grained feedback which captures nuanced distinctions in image quality and prompt-alignment, compared to traditional coarse-grained feedback (for example, thumbs up/down or ranking between a set of options). While fine-grained feedback holds promise, particularly for systems catering to diverse societal preferences, we show that demonstrating its superiority to coarse-grained feedback is not automatic. Through experiments on real and synthetic preference data, we surface the complexities of building effective models due to the interplay of model choice, feedback type, and the alignment between human judgment and computational interpretation. We identify key challenges in eliciting and utilizing fine-grained feedback, prompting a reassessment of its assumed benefits and practicality. Our findings -- e.g., that fine-grained feedback can lead to worse models for a fixed budget, in some settings; however, in controlled settings with known attributes, fine grained rewards can indeed be more helpful -- call for careful consideration of feedback attributes and potentially beckon novel modeling approaches to appropriately unlock the potential value of fine-grained feedback in-the-wild.
Code Pretraining Improves Entity Tracking Abilities of Language Models
May 31, 2024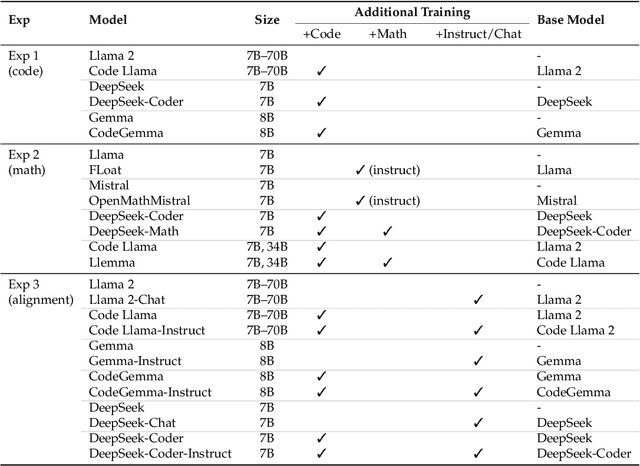
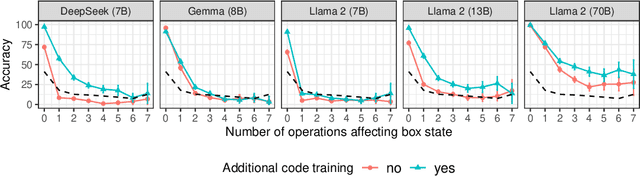
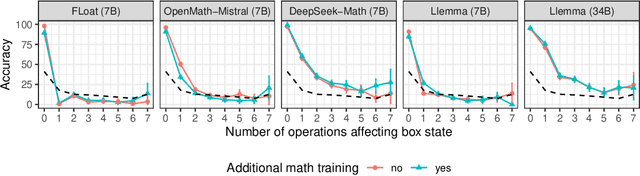

Recent work has provided indirect evidence that pretraining language models on code improves the ability of models to track state changes of discourse entities expressed in natural language. In this work, we systematically test this claim by comparing pairs of language models on their entity tracking performance. Critically, the pairs consist of base models and models trained on top of these base models with additional code data. We extend this analysis to additionally examine the effect of math training, another highly structured data type, and alignment tuning, an important step for enhancing the usability of models. We find clear evidence that models additionally trained on large amounts of code outperform the base models. On the other hand, we find no consistent benefit of additional math training or alignment tuning across various model families.
Syn-QA2: Evaluating False Assumptions in Long-tail Questions with Synthetic QA Datasets
Mar 18, 2024Sensitivity to false assumptions (or false premises) in information-seeking questions is critical for robust question-answering (QA) systems. Recent work has shown that false assumptions in naturally occurring questions pose challenges to current models, with low performance on both generative QA and simple detection tasks (Kim et al. 2023). However, the focus of existing work on naturally occurring questions leads to a gap in the analysis of model behavior on the long tail of the distribution of possible questions. To this end, we introduce Syn-(QA)$^2$, a set of two synthetically generated QA datasets: one generated using perturbed relations from Wikidata, and the other by perturbing HotpotQA (Yang et al. 2018). Our findings from evaluating a range of large language models are threefold: (1) false assumptions in QA are challenging, echoing the findings of prior work, (2) the binary detection task is challenging even compared to the difficulty of generative QA itself, possibly due to the linguistic structure of the problem, and (3) the detection task is more challenging with long-tail questions compared to naturally occurring questions, highlighting the utility of our synthetic datasets and generation method.