 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
NVIDIA Nemotron 3: Efficient and Open Intelligence
Dec 24, 2025We introduce the Nemotron 3 family of models - Nano, Super, and Ultra. These models deliver strong agentic, reasoning, and conversational capabilities. The Nemotron 3 family uses a Mixture-of-Experts hybrid Mamba-Transformer architecture to provide best-in-class throughput and context lengths of up to 1M tokens. Super and Ultra models are trained with NVFP4 and incorporate LatentMoE, a novel approach that improves model quality. The two larger models also include MTP layers for faster text generation. All Nemotron 3 models are post-trained using multi-environment reinforcement learning enabling reasoning, multi-step tool use, and support granular reasoning budget control. Nano, the smallest model, outperforms comparable models in accuracy while remaining extremely cost-efficient for inference. Super is optimized for collaborative agents and high-volume workloads such as IT ticket automation. Ultra, the largest model, provides state-of-the-art accuracy and reasoning performance. Nano is released together with its technical report and this white paper, while Super and Ultra will follow in the coming months. We will openly release the model weights, pre- and post-training software, recipes, and all data for which we hold redistribution rights.
Nemotron 3 Nano: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Dec 23, 2025We present Nemotron 3 Nano 30B-A3B, a Mixture-of-Experts hybrid Mamba-Transformer language model. Nemotron 3 Nano was pretrained on 25 trillion text tokens, including more than 3 trillion new unique tokens over Nemotron 2, followed by supervised fine tuning and large-scale RL on diverse environments. Nemotron 3 Nano achieves better accuracy than our previous generation Nemotron 2 Nano while activating less than half of the parameters per forward pass. It achieves up to 3.3x higher inference throughput than similarly-sized open models like GPT-OSS-20B and Qwen3-30B-A3B-Thinking-2507, while also being more accurate on popular benchmarks. Nemotron 3 Nano demonstrates enhanced agentic, reasoning, and chat abilities and supports context lengths up to 1M tokens. We release both our pretrained Nemotron 3 Nano 30B-A3B Base and post-trained Nemotron 3 Nano 30B-A3B checkpoints on Hugging Face.
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Aug 21, 2025



We introduce Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. Nemotron-Nano-9B-v2 builds on the Nemotron-H architecture, in which the majority of the self-attention layers in the common Transformer architecture are replaced with Mamba-2 layers, to achieve improved inference speed when generating the long thinking traces needed for reasoning. We create Nemotron-Nano-9B-v2 by first pre-training a 12-billion-parameter model (Nemotron-Nano-12B-v2-Base) on 20 trillion tokens using an FP8 training recipe. After aligning Nemotron-Nano-12B-v2-Base, we employ the Minitron strategy to compress and distill the model with the goal of enabling inference on up to 128k tokens on a single NVIDIA A10G GPU (22GiB of memory, bfloat16 precision). Compared to existing similarly-sized models (e.g., Qwen3-8B), we show that Nemotron-Nano-9B-v2 achieves on-par or better accuracy on reasoning benchmarks while achieving up to 6x higher inference throughput in reasoning settings like 8k input and 16k output tokens. We are releasing Nemotron-Nano-9B-v2, Nemotron-Nano12B-v2-Base, and Nemotron-Nano-9B-v2-Base checkpoints along with the majority of our pre- and post-training datasets on Hugging Face.
When2Call: When (not) to Call Tools
Apr 26, 2025Leveraging external tools is a key feature for modern Language Models (LMs) to expand their capabilities and integrate them into existing systems. However, existing benchmarks primarily focus on the accuracy of tool calling -- whether the correct tool is called with the correct parameters -- and less on evaluating when LMs should (not) call tools. We develop a new benchmark, When2Call, which evaluates tool-calling decision-making: when to generate a tool call, when to ask follow-up questions and when to admit the question can't be answered with the tools provided. We find that state-of-the-art tool-calling LMs show significant room for improvement on When2Call, indicating the importance of this benchmark. We also develop a training set for When2Call and leverage the multiple-choice nature of the benchmark to develop a preference optimization training regime, which shows considerably more improvement than traditional fine-tuning. We release the benchmark and training data as well as evaluation scripts at https://github.com/NVIDIA/When2Call.
Is analogy enough to draw novel adjective-noun inferences?
Mar 31, 2025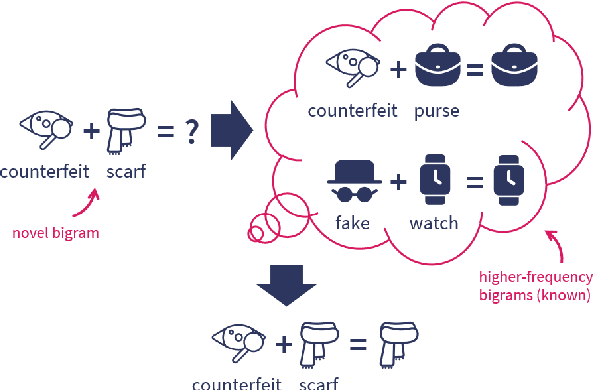
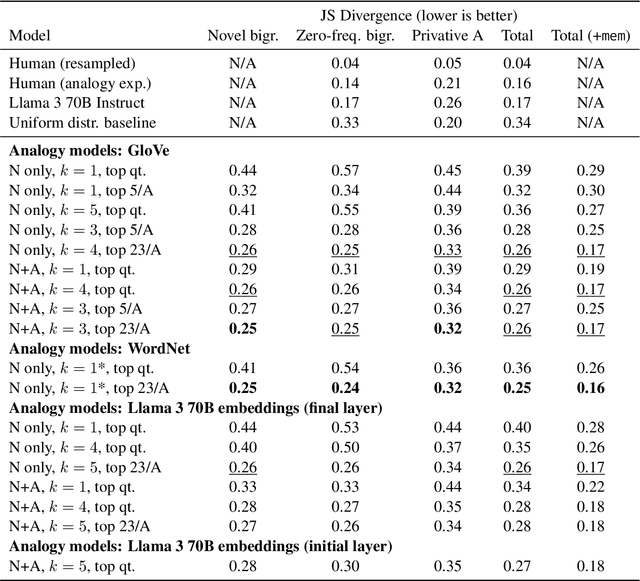
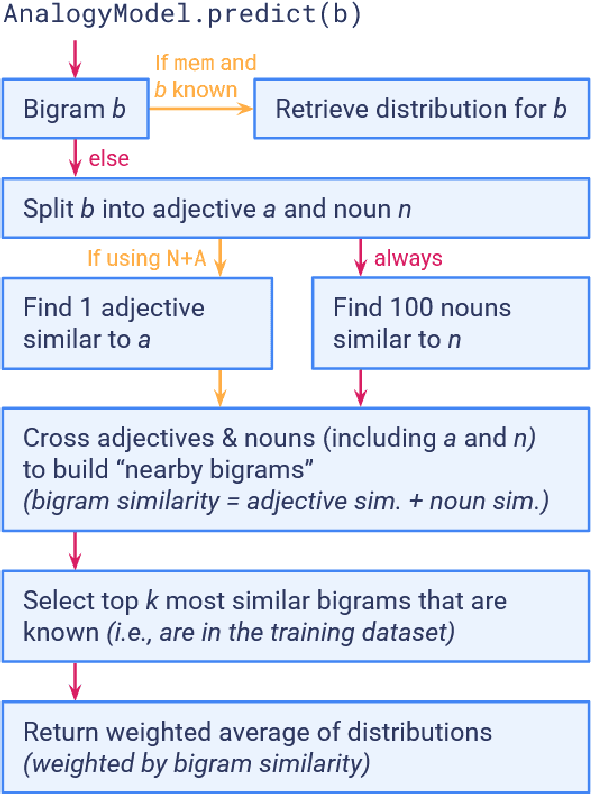
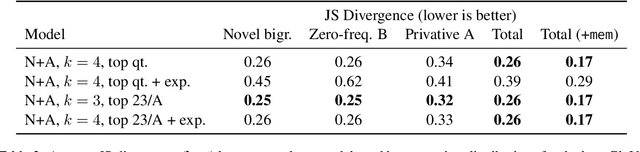
Recent work (Ross et al., 2025, 2024) has argued that the ability of humans and LLMs respectively to generalize to novel adjective-noun combinations shows that they each have access to a compositional mechanism to determine the phrase's meaning and derive inferences. We study whether these inferences can instead be derived by analogy to known inferences, without need for composition. We investigate this by (1) building a model of analogical reasoning using similarity over lexical items, and (2) asking human participants to reason by analogy. While we find that this strategy works well for a large proportion of the dataset of Ross et al. (2025), there are novel combinations for which both humans and LLMs derive convergent inferences but which are not well handled by analogy. We thus conclude that the mechanism humans and LLMs use to generalize in these cases cannot be fully reduced to analogy, and likely involves composition.
Is artificial intelligence still intelligence? LLMs generalize to novel adjective-noun pairs, but don't mimic the full human distribution
Oct 23, 2024



Inferences from adjective-noun combinations like "Is artificial intelligence still intelligence?" provide a good test bed for LLMs' understanding of meaning and compositional generalization capability, since there are many combinations which are novel to both humans and LLMs but nevertheless elicit convergent human judgments. We study a range of LLMs and find that the largest models we tested are able to draw human-like inferences when the inference is determined by context and can generalize to unseen adjective-noun combinations. We also propose three methods to evaluate LLMs on these inferences out of context, where there is a distribution of human-like answers rather than a single correct answer. We find that LLMs show a human-like distribution on at most 75\% of our dataset, which is promising but still leaves room for improvement.
Recent Advances in Natural Language Processing via Large Pre-Trained Language Models: A Survey
Nov 01, 2021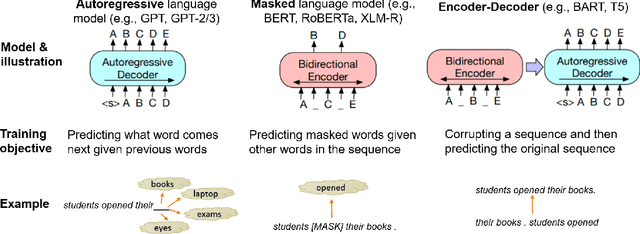
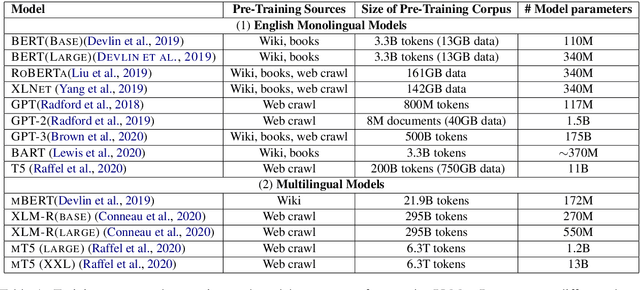
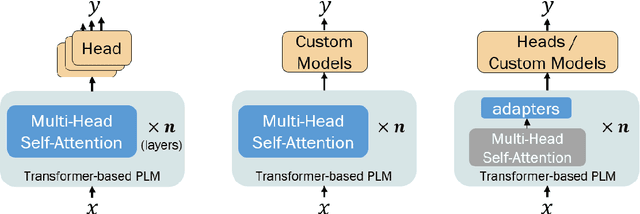

Large, pre-trained transformer-based language models such as BERT have drastically changed the Natural Language Processing (NLP) field. We present a survey of recent work that uses these large language models to solve NLP tasks via pre-training then fine-tuning, prompting, or text generation approaches. We also present approaches that use pre-trained language models to generate data for training augmentation or other purposes. We conclude with discussions on limitations and suggested directions for future research.
Exploring Contextualized Neural Language Models for Temporal Dependency Parsing
Apr 30, 2020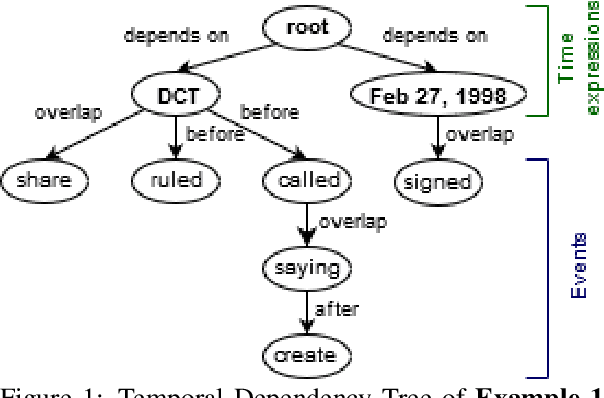

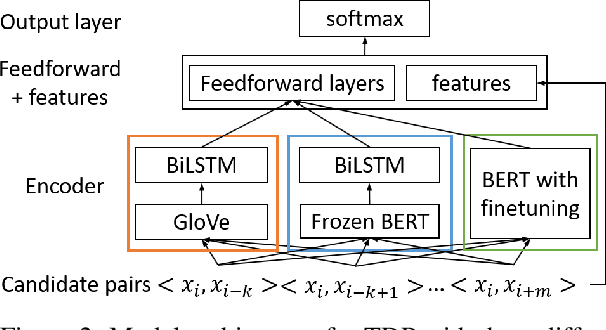

Extracting temporal relations between events and time expressions has many applications such as constructing event timelines and time-related question answering. It is a challenging problem that requires syntactic and semantic information at sentence or discourse levels, which may be captured by deep language models such as BERT (Devlin et al., 2019). In this paper, we developed several variants of BERT-based temporal dependency parser, and show that BERT significantly improves temporal dependency parsing (Zhang and Xue,2018a). Source code and trained models will be made available at github.com.