 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning from Child-Directed Speech in Two-Language Scenarios: A French-English Case Study
Mar 13, 2026Research on developmentally plausible language models has largely focused on English, leaving open questions about multilingual settings. We present a systematic study of compact language models by extending BabyBERTa to English-French scenarios under strictly size-matched data conditions, covering monolingual, bilingual, and cross-lingual settings. Our design contrasts two types of training corpora: (i) child-directed speech (about 2.5M tokens), following BabyBERTa and related work, and (ii) multi-domain corpora (about 10M tokens), extending the BabyLM framework to French. To enable fair evaluation, we also introduce new resources, including French versions of QAMR and QASRL, as well as English and French multi-domain corpora. We evaluate the models on both syntactic and semantic tasks and compare them with models trained on Wikipedia-only data. The results reveal context-dependent effects: training on Wikipedia consistently benefits semantic tasks, whereas child-directed speech improves grammatical judgments in monolingual settings. Bilingual pretraining yields notable gains for textual entailment, with particularly strong improvements for French. Importantly, similar patterns emerge across BabyBERTa, RoBERTa, and LTG-BERT, suggesting consistent trends across architectures.
Recent Advances in Natural Language Processing via Large Pre-Trained Language Models: A Survey
Nov 01, 2021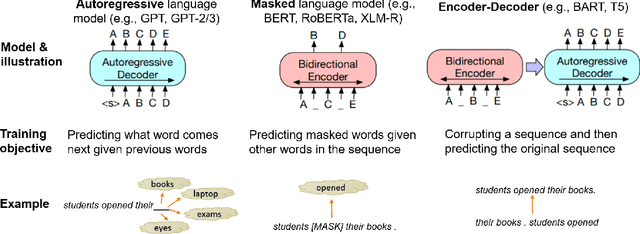
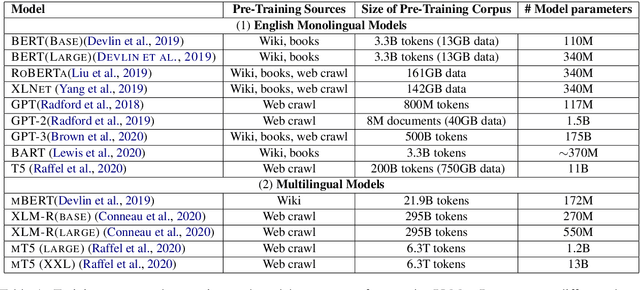
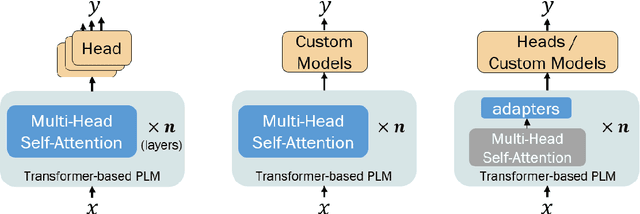

Large, pre-trained transformer-based language models such as BERT have drastically changed the Natural Language Processing (NLP) field. We present a survey of recent work that uses these large language models to solve NLP tasks via pre-training then fine-tuning, prompting, or text generation approaches. We also present approaches that use pre-trained language models to generate data for training augmentation or other purposes. We conclude with discussions on limitations and suggested directions for future research.
The Language of Legal and Illegal Activity on the Darknet
Jun 04, 2019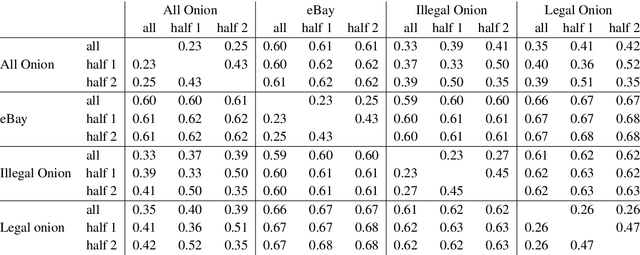
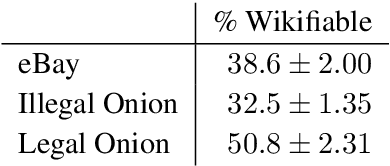
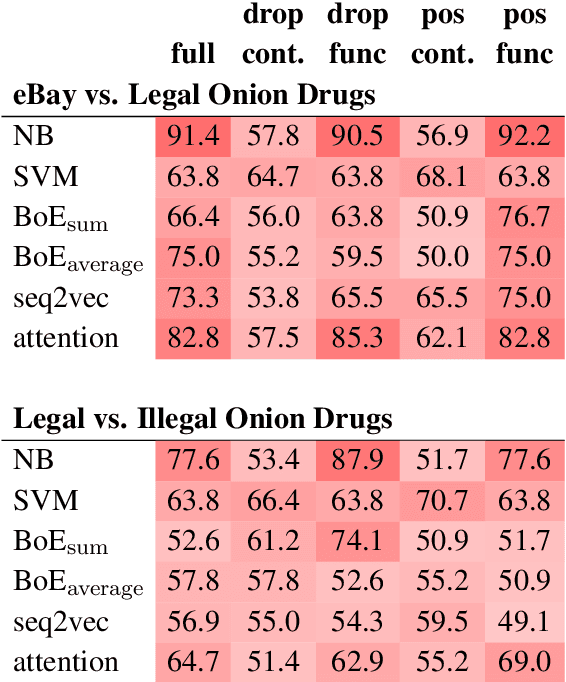
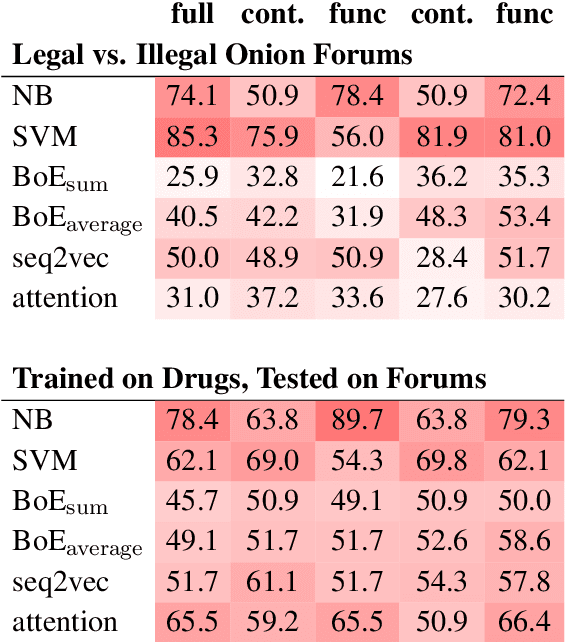
The non-indexed parts of the Internet (the Darknet) have become a haven for both legal and illegal anonymous activity. Given the magnitude of these networks, scalably monitoring their activity necessarily relies on automated tools, and notably on NLP tools. However, little is known about what characteristics texts communicated through the Darknet have, and how well off-the-shelf NLP tools do on this domain. This paper tackles this gap and performs an in-depth investigation of the characteristics of legal and illegal text in the Darknet, comparing it to a clear net website with similar content as a control condition. Taking drug-related websites as a test case, we find that texts for selling legal and illegal drugs have several linguistic characteristics that distinguish them from one another, as well as from the control condition, among them the distribution of POS tags, and the coverage of their named entities in Wikipedia.
SemEval 2019 Task 1: Cross-lingual Semantic Parsing with UCCA
Mar 06, 2019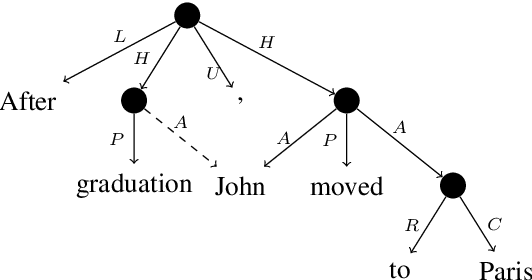

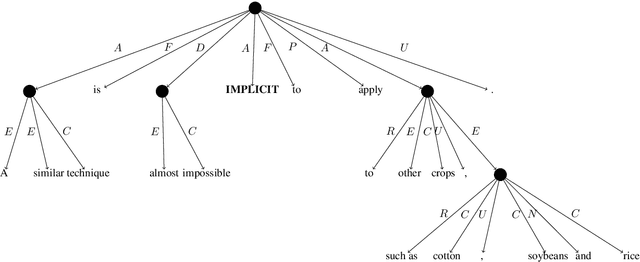

We present the SemEval 2019 shared task on UCCA parsing in English, German and French, and discuss the participating systems and results. UCCA is a cross-linguistically applicable framework for semantic representation, which builds on extensive typological work and supports rapid annotation. UCCA poses a challenge for existing parsing techniques, as it exhibits reentrancy (resulting in DAG structures), discontinuous structures and non-terminal nodes corresponding to complex semantic units. The shared task has yielded improvements over the state-of-the-art baseline in all languages and settings. Full results can be found in the task's website \url{https://competitions.codalab.org/competitions/19160}.
BLEU is Not Suitable for the Evaluation of Text Simplification
Oct 14, 2018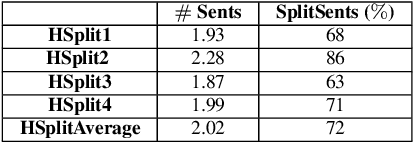
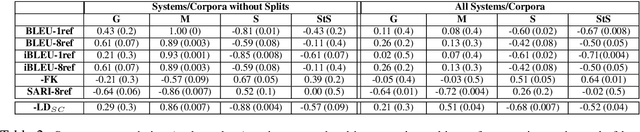
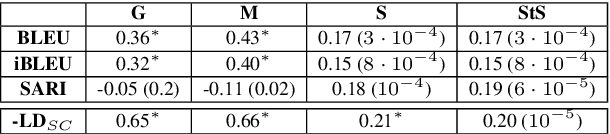
BLEU is widely considered to be an informative metric for text-to-text generation, including Text Simplification (TS). TS includes both lexical and structural aspects. In this paper we show that BLEU is not suitable for the evaluation of sentence splitting, the major structural simplification operation. We manually compiled a sentence splitting gold standard corpus containing multiple structural paraphrases, and performed a correlation analysis with human judgments. We find low or no correlation between BLEU and the grammaticality and meaning preservation parameters where sentence splitting is involved. Moreover, BLEU often negatively correlates with simplicity, essentially penalizing simpler sentences.
Simple and Effective Text Simplification Using Semantic and Neural Methods
Oct 11, 2018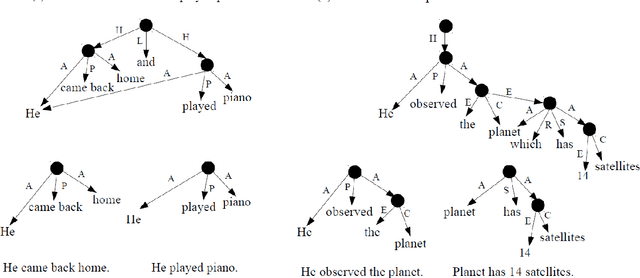

Sentence splitting is a major simplification operator. Here we present a simple and efficient splitting algorithm based on an automatic semantic parser. After splitting, the text is amenable for further fine-tuned simplification operations. In particular, we show that neural Machine Translation can be effectively used in this situation. Previous application of Machine Translation for simplification suffers from a considerable disadvantage in that they are over-conservative, often failing to modify the source in any way. Splitting based on semantic parsing, as proposed here, alleviates this issue. Extensive automatic and human evaluation shows that the proposed method compares favorably to the state-of-the-art in combined lexical and structural simplification.
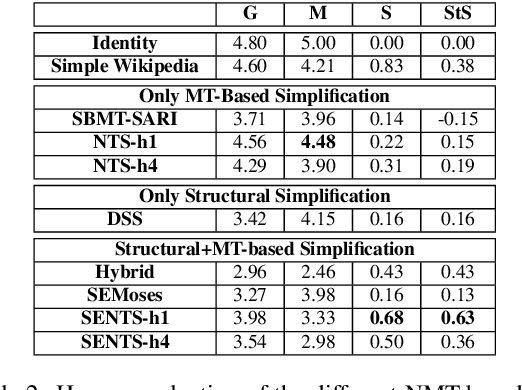
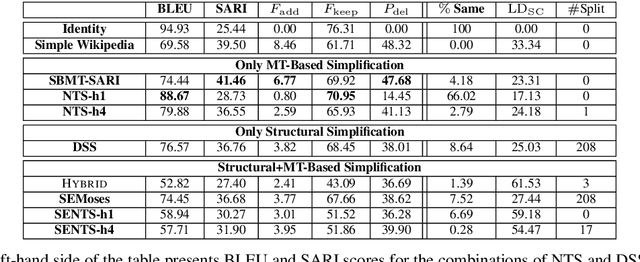
Semantic Structural Evaluation for Text Simplification
Oct 11, 2018
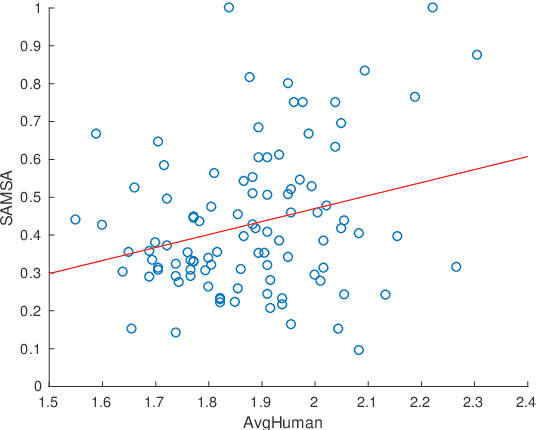
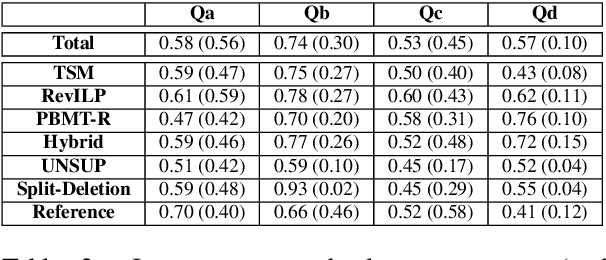

Current measures for evaluating text simplification systems focus on evaluating lexical text aspects, neglecting its structural aspects. In this paper we propose the first measure to address structural aspects of text simplification, called SAMSA. It leverages recent advances in semantic parsing to assess simplification quality by decomposing the input based on its semantic structure and comparing it to the output. SAMSA provides a reference-less automatic evaluation procedure, avoiding the problems that reference-based methods face due to the vast space of valid simplifications for a given sentence. Our human evaluation experiments show both SAMSA's substantial correlation with human judgments, as well as the deficiency of existing reference-based measures in evaluating structural simplification.
SemEval 2019 Shared Task: Cross-lingual Semantic Parsing with UCCA - Call for Participation
Aug 19, 2018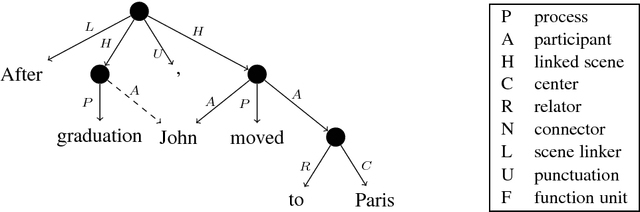
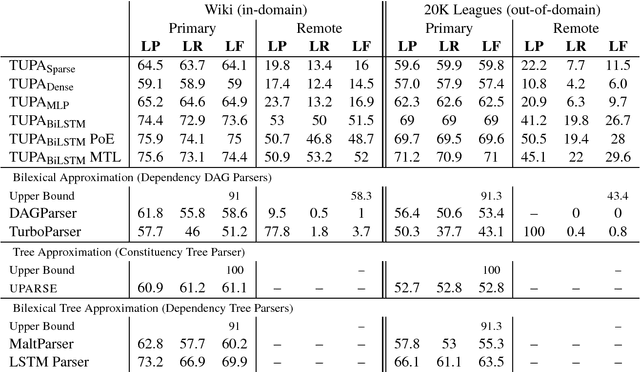
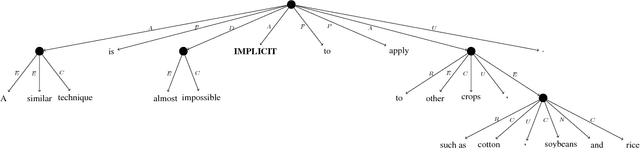
We announce a shared task on UCCA parsing in English, German and French, and call for participants to submit their systems. UCCA is a cross-linguistically applicable framework for semantic representation, which builds on extensive typological work and supports rapid annotation. UCCA poses a challenge for existing parsing techniques, as it exhibits reentrancy (resulting in DAG structures), discontinuous structures and non-terminal nodes corresponding to complex semantic units. Given the success of recent semantic parsing shared tasks (on SDP and AMR), we expect the task to have a significant contribution to the advancement of UCCA parsing in particular, and semantic parsing in general. Furthermore, existing applications for semantic evaluation that are based on UCCA will greatly benefit from better automatic methods for UCCA parsing. The competition website is https://competitions.codalab.org/competitions/19160