 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChatGPT Beyond English: Towards a Comprehensive Evaluation of Large Language Models in Multilingual Learning
Apr 12, 2023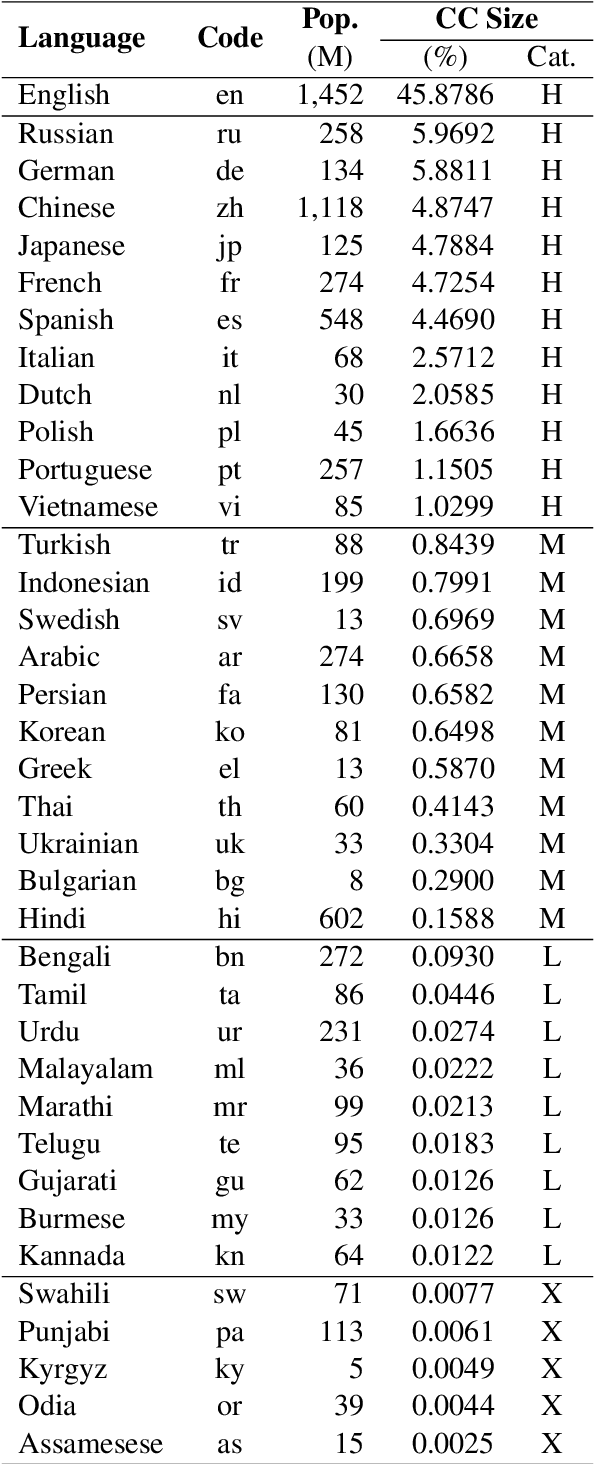
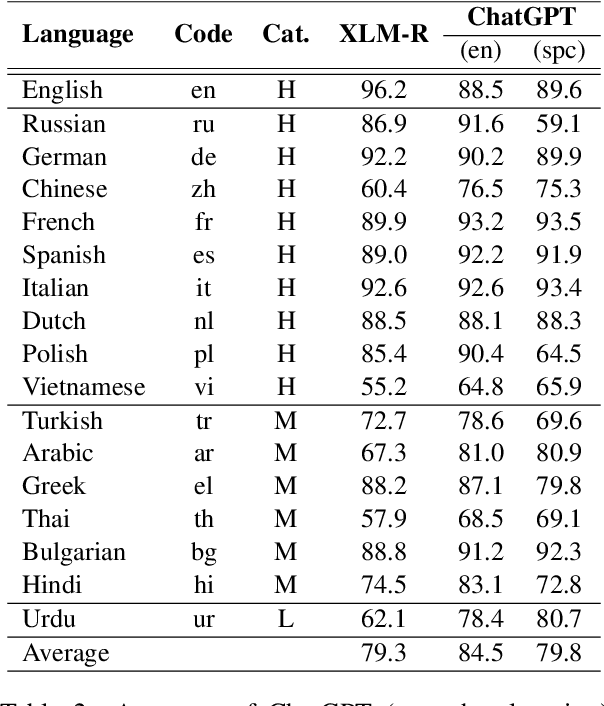
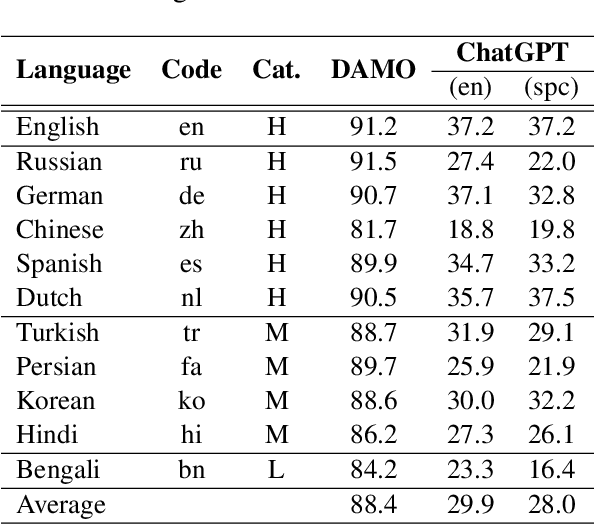
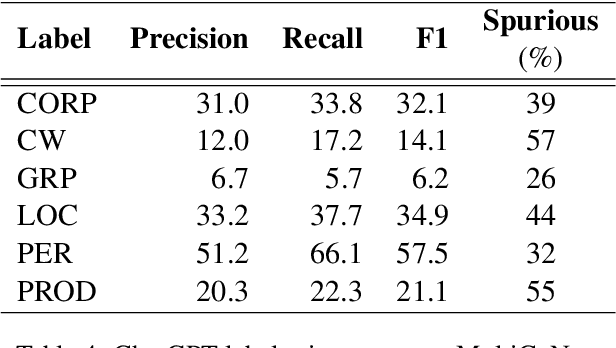
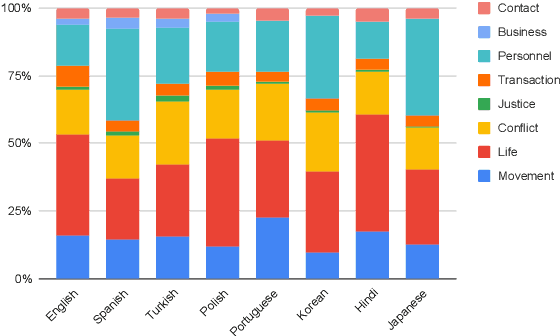
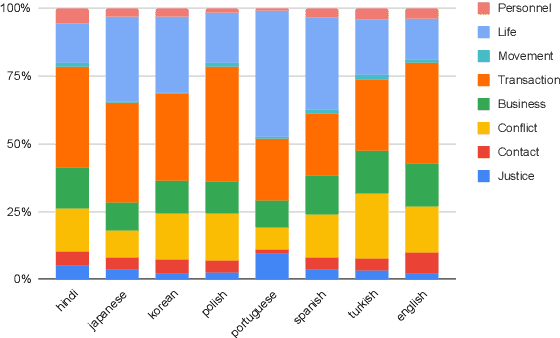
Over the last few years, large language models (LLMs) have emerged as the most important breakthroughs in natural language processing (NLP) that fundamentally transform research and developments in the field. ChatGPT represents one of the most exciting LLM systems developed recently to showcase impressive skills for language generation and highly attract public attention. Among various exciting applications discovered for ChatGPT in English, the model can process and generate texts for multiple languages due to its multilingual training data. Given the broad adoption of ChatGPT for English in different problems and areas, a natural question is whether ChatGPT can also be applied effectively for other languages or it is necessary to develop more language-specific technologies. The answer to this question requires a thorough evaluation of ChatGPT over multiple tasks with diverse languages and large datasets (i.e., beyond reported anecdotes), which is still missing or limited in current research. Our work aims to fill this gap for the evaluation of ChatGPT and similar LLMs to provide more comprehensive information for multilingual NLP applications. While this work will be an ongoing effort to include additional experiments in the future, our current paper evaluates ChatGPT on 7 different tasks, covering 37 diverse languages with high, medium, low, and extremely low resources. We also focus on the zero-shot learning setting for ChatGPT to improve reproducibility and better simulate the interactions of general users. Compared to the performance of previous models, our extensive experimental results demonstrate a worse performance of ChatGPT for different NLP tasks and languages, calling for further research to develop better models and understanding for multilingual learning.
MINION: a Large-Scale and Diverse Dataset for Multilingual Event Detection
Nov 17, 2022


Event Detection (ED) is the task of identifying and classifying trigger words of event mentions in text. Despite considerable research efforts in recent years for English text, the task of ED in other languages has been significantly less explored. Switching to non-English languages, important research questions for ED include how well existing ED models perform on different languages, how challenging ED is in other languages, and how well ED knowledge and annotation can be transferred across languages. To answer those questions, it is crucial to obtain multilingual ED datasets that provide consistent event annotation for multiple languages. There exist some multilingual ED datasets; however, they tend to cover a handful of languages and mainly focus on popular ones. Many languages are not covered in existing multilingual ED datasets. In addition, the current datasets are often small and not accessible to the public. To overcome those shortcomings, we introduce a new large-scale multilingual dataset for ED (called MINION) that consistently annotates events for 8 different languages; 5 of them have not been supported by existing multilingual datasets. We also perform extensive experiments and analysis to demonstrate the challenges and transferability of ED across languages in MINION that in all call for more research effort in this area.
MEE: A Novel Multilingual Event Extraction Dataset
Nov 17, 2022


Event Extraction (EE) is one of the fundamental tasks in Information Extraction (IE) that aims to recognize event mentions and their arguments (i.e., participants) from text. Due to its importance, extensive methods and resources have been developed for Event Extraction. However, one limitation of current research for EE involves the under-exploration for non-English languages in which the lack of high-quality multilingual EE datasets for model training and evaluation has been the main hindrance. To address this limitation, we propose a novel Multilingual Event Extraction dataset (MEE) that provides annotation for more than 50K event mentions in 8 typologically different languages. MEE comprehensively annotates data for entity mentions, event triggers and event arguments. We conduct extensive experiments on the proposed dataset to reveal challenges and opportunities for multilingual EE.
Tutorial Recommendation for Livestream Videos using Discourse-Level Consistency and Ontology-Based Filtering
Sep 11, 2022


Streaming videos is one of the methods for creators to share their creative works with their audience. In these videos, the streamer share how they achieve their final objective by using various tools in one or several programs for creative projects. To this end, the steps required to achieve the final goal can be discussed. As such, these videos could provide substantial educational content that can be used to learn how to employ the tools used by the streamer. However, one of the drawbacks is that the streamer might not provide enough details for every step. Therefore, for the learners, it might be difficult to catch up with all the steps. In order to alleviate this issue, one solution is to link the streaming videos with the relevant tutorial available for the tools used in the streaming video. More specifically, a system can analyze the content of the live streaming video and recommend the most relevant tutorials. Since the existing document recommendation models cannot handle this situation, in this work, we present a novel dataset and model for the task of tutorial recommendation for live-streamed videos. We conduct extensive analyses on the proposed dataset and models, revealing the challenging nature of this task.
Improving Keyphrase Extraction with Data Augmentation and Information Filtering
Sep 11, 2022


Keyphrase extraction is one of the essential tasks for document understanding in NLP. While the majority of the prior works are dedicated to the formal setting, e.g., books, news or web-blogs, informal texts such as video transcripts are less explored. To address this limitation, in this work we present a novel corpus and method for keyphrase extraction from the transcripts of the videos streamed on the Behance platform. More specifically, in this work, a novel data augmentation is proposed to enrich the model with the background knowledge about the keyphrase extraction task from other domains. Extensive experiments on the proposed dataset dataset show the effectiveness of the introduced method.
Symlink: A New Dataset for Scientific Symbol-Description Linking
Apr 26, 2022



Mathematical symbols and descriptions appear in various forms across document section boundaries without explicit markup. In this paper, we present a new large-scale dataset that emphasizes extracting symbols and descriptions in scientific documents. Symlink annotates scientific papers of 5 different domains (i.e., computer science, biology, physics, mathematics, and economics). Our experiments on Symlink demonstrate the challenges of the symbol-description linking task for existing models and call for further research effort in this area. We will publicly release Symlink to facilitate future research.
Punctuation Restoration
Feb 19, 2022
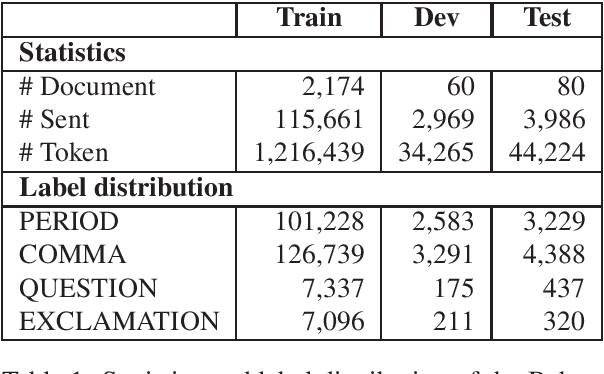


Given the increasing number of livestreaming videos, automatic speech recognition and post-processing for livestreaming video transcripts are crucial for efficient data management as well as knowledge mining. A key step in this process is punctuation restoration which restores fundamental text structures such as phrase and sentence boundaries from the video transcripts. This work presents a new human-annotated corpus, called BehancePR, for punctuation restoration in livestreaming video transcripts. Our experiments on BehancePR demonstrate the challenges of punctuation restoration for this domain. Furthermore, we show that popular natural language processing toolkits are incapable of detecting sentence boundary on non-punctuated transcripts of livestreaming videos, calling for more research effort to develop robust models for this area.
MACRONYM: A Large-Scale Dataset for Multilingual and Multi-Domain Acronym Extraction
Feb 19, 2022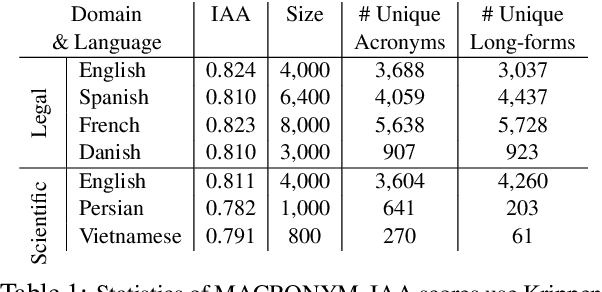
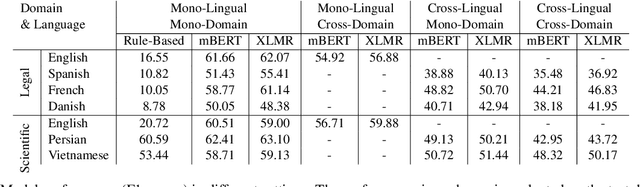
Acronym extraction is the task of identifying acronyms and their expanded forms in texts that is necessary for various NLP applications. Despite major progress for this task in recent years, one limitation of existing AE research is that they are limited to the English language and certain domains (i.e., scientific and biomedical). As such, challenges of AE in other languages and domains is mainly unexplored. Lacking annotated datasets in multiple languages and domains has been a major issue to hinder research in this area. To address this limitation, we propose a new dataset for multilingual multi-domain AE. Specifically, 27,200 sentences in 6 typologically different languages and 2 domains, i.e., Legal and Scientific, is manually annotated for AE. Our extensive experiments on the proposed dataset show that AE in different languages and different learning settings has unique challenges, emphasizing the necessity of further research on multilingual and multi-domain AE.
Recent Advances in Natural Language Processing via Large Pre-Trained Language Models: A Survey
Nov 01, 2021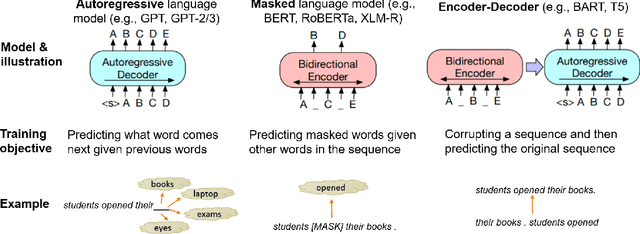
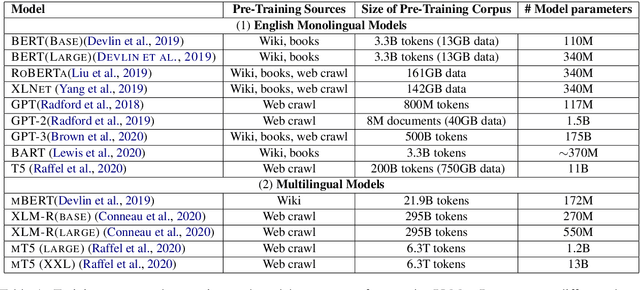
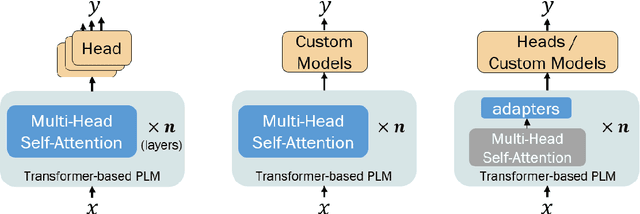

Large, pre-trained transformer-based language models such as BERT have drastically changed the Natural Language Processing (NLP) field. We present a survey of recent work that uses these large language models to solve NLP tasks via pre-training then fine-tuning, prompting, or text generation approaches. We also present approaches that use pre-trained language models to generate data for training augmentation or other purposes. We conclude with discussions on limitations and suggested directions for future research.
MadDog: A Web-based System for Acronym Identification and Disambiguation
Jan 25, 2021


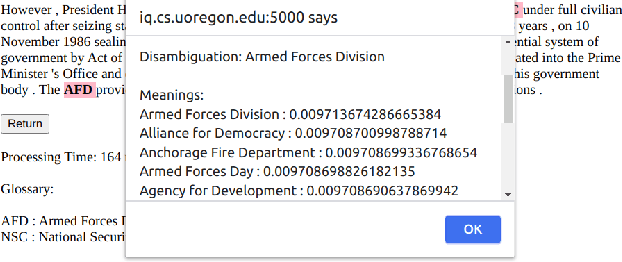
Acronyms and abbreviations are the short-form of longer phrases and they are ubiquitously employed in various types of writing. Despite their usefulness to save space in writing and reader's time in reading, they also provide challenges for understanding the text especially if the acronym is not defined in the text or if it is used far from its definition in long texts. To alleviate this issue, there are considerable efforts both from the research community and software developers to build systems for identifying acronyms and finding their correct meanings in the text. However, none of the existing works provide a unified solution capable of processing acronyms in various domains and to be publicly available. Thus, we provide the first web-based acronym identification and disambiguation system which can process acronyms from various domains including scientific, biomedical, and general domains. The web-based system is publicly available at http://iq.cs.uoregon.edu:5000 and a demo video is available at https://youtu.be/IkSh7LqI42M. The system source code is also available at https://github.com/amirveyseh/MadDog.