 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEE: A Novel Multilingual Event Extraction Dataset
Nov 17, 2022
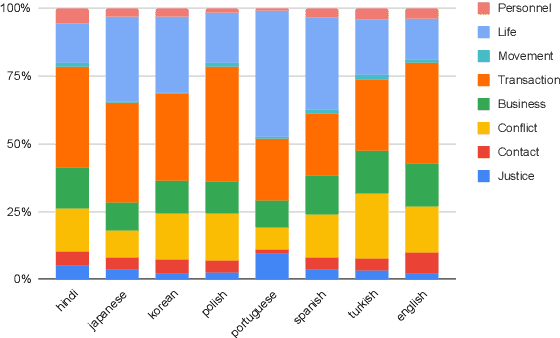


Event Extraction (EE) is one of the fundamental tasks in Information Extraction (IE) that aims to recognize event mentions and their arguments (i.e., participants) from text. Due to its importance, extensive methods and resources have been developed for Event Extraction. However, one limitation of current research for EE involves the under-exploration for non-English languages in which the lack of high-quality multilingual EE datasets for model training and evaluation has been the main hindrance. To address this limitation, we propose a novel Multilingual Event Extraction dataset (MEE) that provides annotation for more than 50K event mentions in 8 typologically different languages. MEE comprehensively annotates data for entity mentions, event triggers and event arguments. We conduct extensive experiments on the proposed dataset to reveal challenges and opportunities for multilingual EE.
Embedding Compression with Hashing for Efficient Representation Learning in Large-Scale Graph
Aug 11, 2022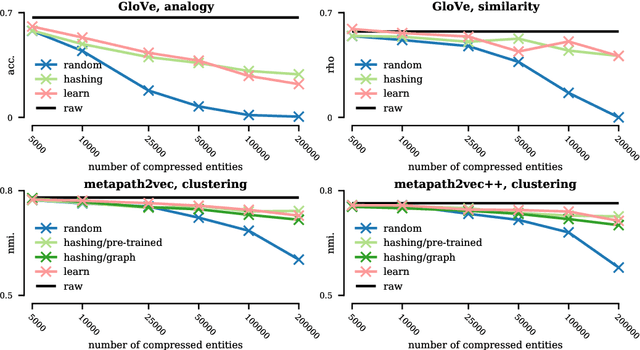
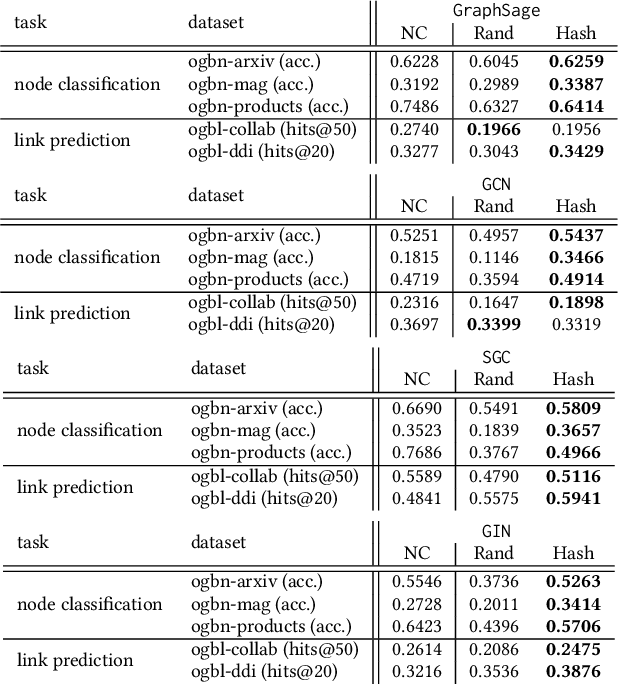
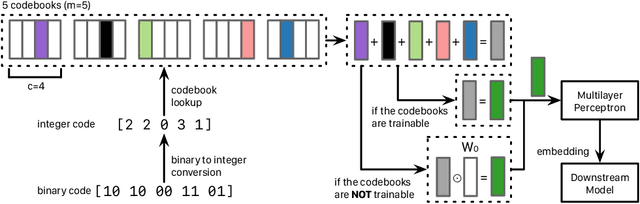

Graph neural networks (GNNs) are deep learning models designed specifically for graph data, and they typically rely on node features as the input to the first layer. When applying such a type of network on the graph without node features, one can extract simple graph-based node features (e.g., number of degrees) or learn the input node representations (i.e., embeddings) when training the network. While the latter approach, which trains node embeddings, more likely leads to better performance, the number of parameters associated with the embeddings grows linearly with the number of nodes. It is therefore impractical to train the input node embeddings together with GNNs within graphics processing unit (GPU) memory in an end-to-end fashion when dealing with industrial-scale graph data. Inspired by the embedding compression methods developed for natural language processing (NLP) tasks, we develop a node embedding compression method where each node is compactly represented with a bit vector instead of a floating-point vector. The parameters utilized in the compression method can be trained together with GNNs. We show that the proposed node embedding compression method achieves superior performance compared to the alternatives.
Online Multi-horizon Transaction Metric Estimation with Multi-modal Learning in Payment Networks
Sep 22, 2021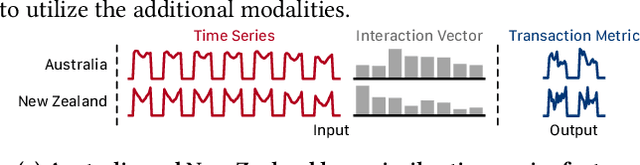

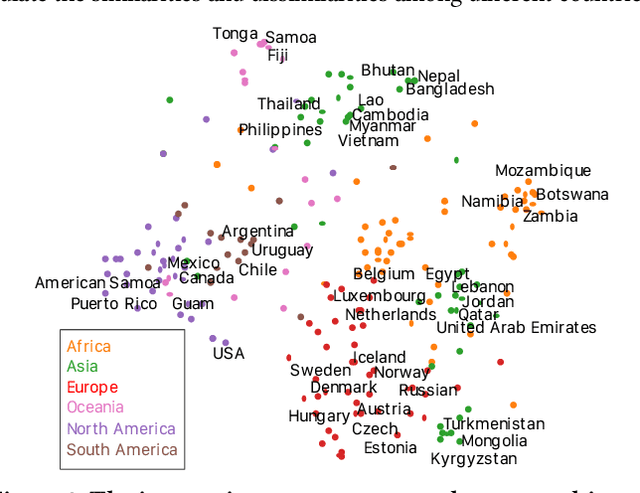
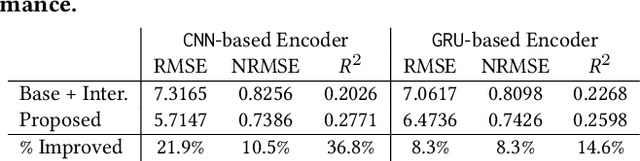
Predicting metrics associated with entities' transnational behavior within payment processing networks is essential for system monitoring. Multivariate time series, aggregated from the past transaction history, can provide valuable insights for such prediction. The general multivariate time series prediction problem has been well studied and applied across several domains, including manufacturing, medical, and entomology. However, new domain-related challenges associated with the data such as concept drift and multi-modality have surfaced in addition to the real-time requirements of handling the payment transaction data at scale. In this work, we study the problem of multivariate time series prediction for estimating transaction metrics associated with entities in the payment transaction database. We propose a model with five unique components to estimate the transaction metrics from multi-modality data. Four of these components capture interaction, temporal, scale, and shape perspectives, and the fifth component fuses these perspectives together. We also propose a hybrid offline/online training scheme to address concept drift in the data and fulfill the real-time requirements. Combining the estimation model with a graphical user interface, the prototype transaction metric estimation system has demonstrated its potential benefit as a tool for improving a payment processing company's system monitoring capability.
How Does Adversarial Fine-Tuning Benefit BERT?
Aug 31, 2021
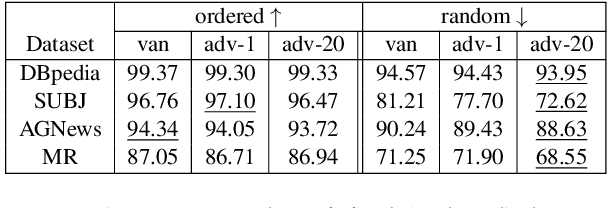
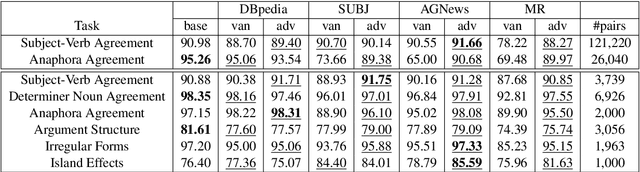

Adversarial training (AT) is one of the most reliable methods for defending against adversarial attacks in machine learning. Variants of this method have been used as regularization mechanisms to achieve SOTA results on NLP benchmarks, and they have been found to be useful for transfer learning and continual learning. We search for the reasons for the effectiveness of AT by contrasting vanilla and adversarially fine-tuned BERT models. We identify partial preservation of BERT's syntactic abilities during fine-tuning as the key to the success of AT. We observe that adversarially fine-tuned models remain more faithful to BERT's language modeling behavior and are more sensitive to the word order. As concrete examples of syntactic abilities, an adversarially fine-tuned model could have an advantage of up to 38% on anaphora agreement and up to 11% on dependency parsing. Our analysis demonstrates that vanilla fine-tuning oversimplifies the sentence representation by focusing heavily on one or a few label-indicative words. AT, however, moderates the effect of these influential words and encourages representational diversity. This allows for a more hierarchical representation of a sentence and leads to the mitigation of BERT's loss of syntactic abilities.
How Can Self-Attention Networks Recognize Dyck-n Languages?
Oct 09, 2020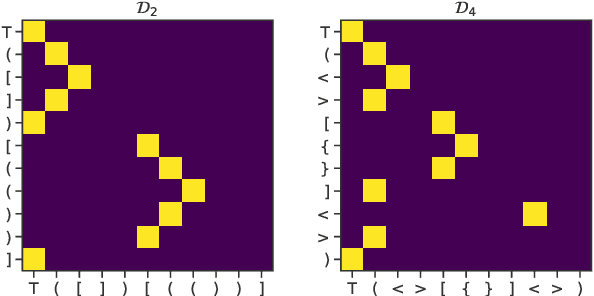
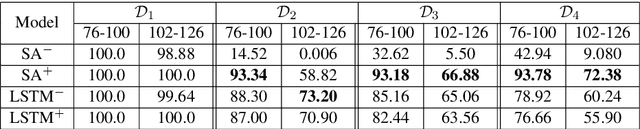
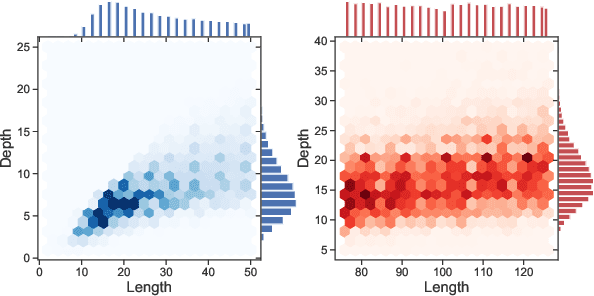
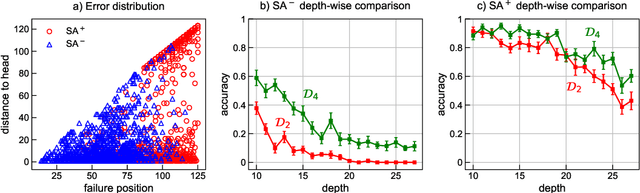
We focus on the recognition of Dyck-n ($\mathcal{D}_n$) languages with self-attention (SA) networks, which has been deemed to be a difficult task for these networks. We compare the performance of two variants of SA, one with a starting symbol (SA$^+$) and one without (SA$^-$). Our results show that SA$^+$ is able to generalize to longer sequences and deeper dependencies. For $\mathcal{D}_2$, we find that SA$^-$ completely breaks down on long sequences whereas the accuracy of SA$^+$ is 58.82$\%$. We find attention maps learned by $\text{SA}{^+}$ to be amenable to interpretation and compatible with a stack-based language recognizer. Surprisingly, the performance of SA networks is at par with LSTMs, which provides evidence on the ability of SA to learn hierarchies without recursion.
On Adversarial Examples for Character-Level Neural Machine Translation
Jun 23, 2018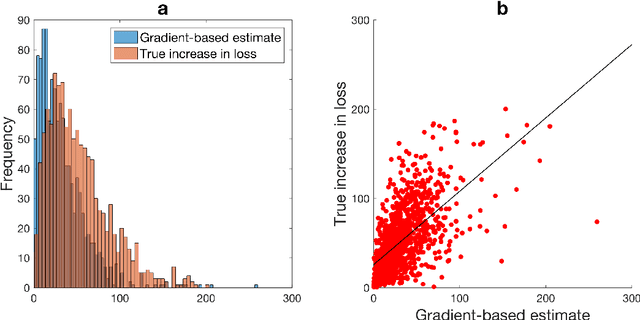
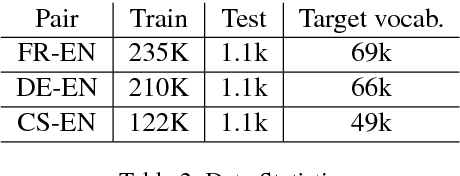
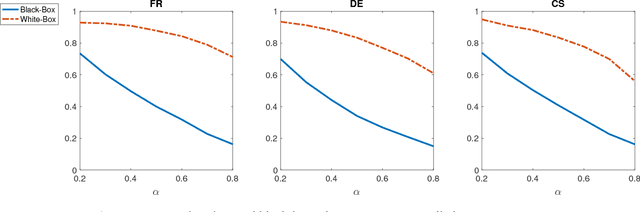
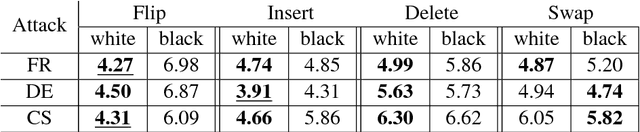
Evaluating on adversarial examples has become a standard procedure to measure robustness of deep learning models. Due to the difficulty of creating white-box adversarial examples for discrete text input, most analyses of the robustness of NLP models have been done through black-box adversarial examples. We investigate adversarial examples for character-level neural machine translation (NMT), and contrast black-box adversaries with a novel white-box adversary, which employs differentiable string-edit operations to rank adversarial changes. We propose two novel types of attacks which aim to remove or change a word in a translation, rather than simply break the NMT. We demonstrate that white-box adversarial examples are significantly stronger than their black-box counterparts in different attack scenarios, which show more serious vulnerabilities than previously known. In addition, after performing adversarial training, which takes only 3 times longer than regular training, we can improve the model's robustness significantly.
HotFlip: White-Box Adversarial Examples for Text Classification
May 24, 2018
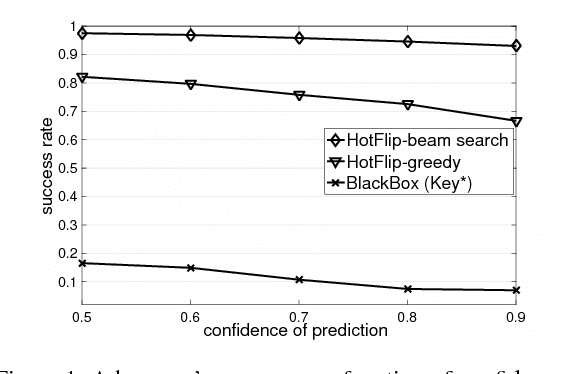
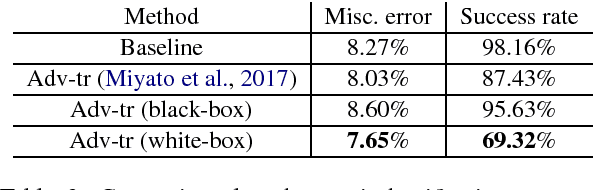

We propose an efficient method to generate white-box adversarial examples to trick a character-level neural classifier. We find that only a few manipulations are needed to greatly decrease the accuracy. Our method relies on an atomic flip operation, which swaps one token for another, based on the gradients of the one-hot input vectors. Due to efficiency of our method, we can perform adversarial training which makes the model more robust to attacks at test time. With the use of a few semantics-preserving constraints, we demonstrate that HotFlip can be adapted to attack a word-level classifier as well.