 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow Can Self-Attention Networks Recognize Dyck-n Languages?
Oct 09, 2020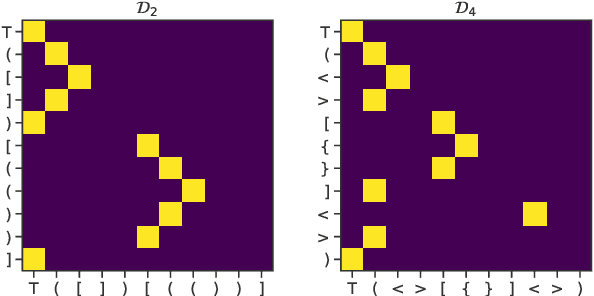
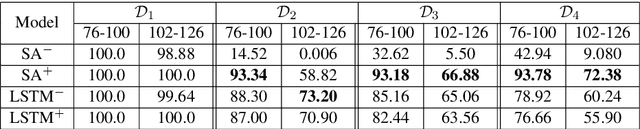
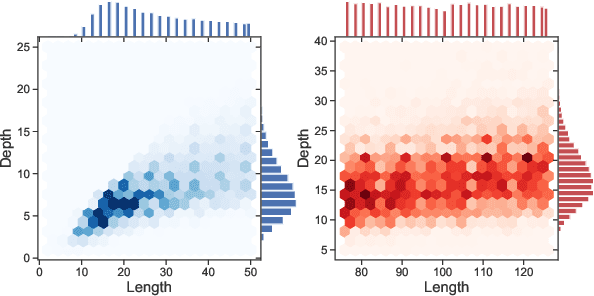
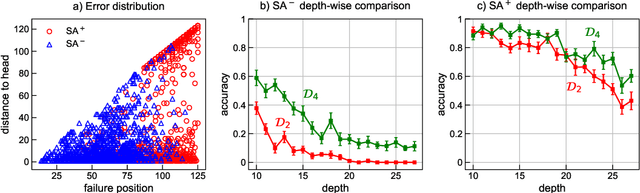
We focus on the recognition of Dyck-n ($\mathcal{D}_n$) languages with self-attention (SA) networks, which has been deemed to be a difficult task for these networks. We compare the performance of two variants of SA, one with a starting symbol (SA$^+$) and one without (SA$^-$). Our results show that SA$^+$ is able to generalize to longer sequences and deeper dependencies. For $\mathcal{D}_2$, we find that SA$^-$ completely breaks down on long sequences whereas the accuracy of SA$^+$ is 58.82$\%$. We find attention maps learned by $\text{SA}{^+}$ to be amenable to interpretation and compatible with a stack-based language recognizer. Surprisingly, the performance of SA networks is at par with LSTMs, which provides evidence on the ability of SA to learn hierarchies without recursion.
Towards a Flexible Embedding Learning Framework
Sep 23, 2020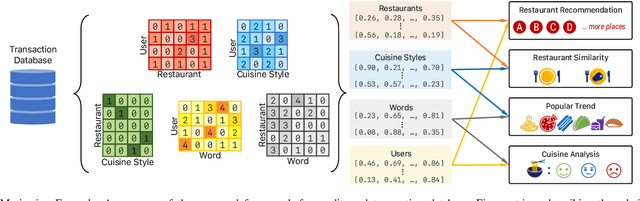
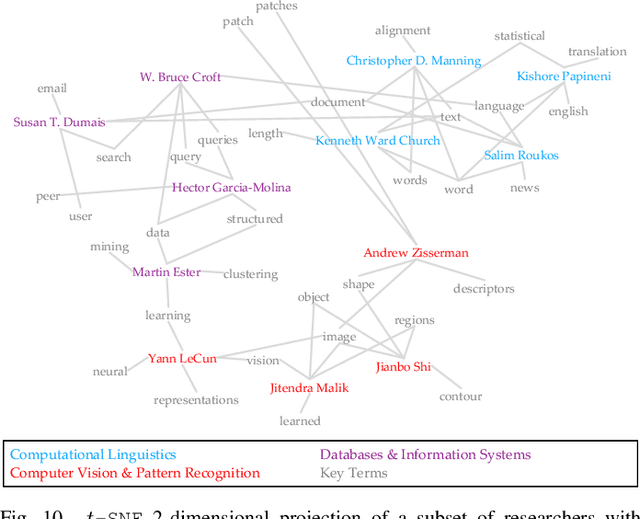
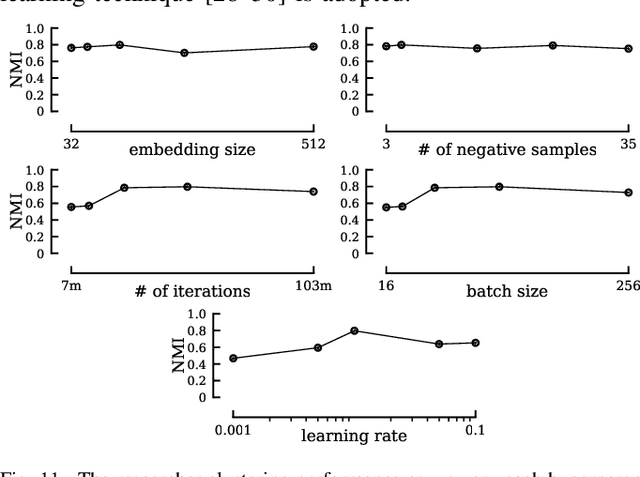
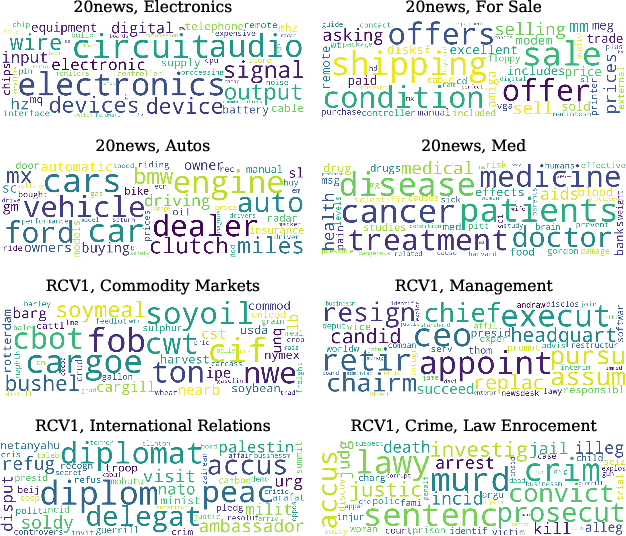
Representation learning is a fundamental building block for analyzing entities in a database. While the existing embedding learning methods are effective in various data mining problems, their applicability is often limited because these methods have pre-determined assumptions on the type of semantics captured by the learned embeddings, and the assumptions may not well align with specific downstream tasks. In this work, we propose an embedding learning framework that 1) uses an input format that is agnostic to input data type, 2) is flexible in terms of the relationships that can be embedded into the learned representations, and 3) provides an intuitive pathway to incorporate domain knowledge into the embedding learning process. Our proposed framework utilizes a set of entity-relation-matrices as the input, which quantifies the affinities among different entities in the database. Moreover, a sampling mechanism is carefully designed to establish a direct connection between the input and the information captured by the output embeddings. To complete the representation learning toolbox, we also outline a simple yet effective post-processing technique to properly visualize the learned embeddings. Our empirical results demonstrate that the proposed framework, in conjunction with a set of relevant entity-relation-matrices, outperforms the existing state-of-the-art approaches in various data mining tasks.