 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransactionGPT
Nov 12, 2025We present TransactionGPT (TGPT), a foundation model for consumer transaction data within one of world's largest payment networks. TGPT is designed to understand and generate transaction trajectories while simultaneously supporting a variety of downstream prediction and classification tasks. We introduce a novel 3D-Transformer architecture specifically tailored for capturing the complex dynamics in payment transaction data. This architecture incorporates design innovations that enhance modality fusion and computational efficiency, while seamlessly enabling joint optimization with downstream objectives. Trained on billion-scale real-world transactions, TGPT significantly improves downstream classification performance against a competitive production model and exhibits advantages over baselines in generating future transactions. We conduct extensive empirical evaluations utilizing a diverse collection of company transaction datasets spanning multiple downstream tasks, thereby enabling a thorough assessment of TGPT's effectiveness and efficiency in comparison to established methodologies. Furthermore, we examine the incorporation of LLM-derived embeddings within TGPT and benchmark its performance against fine-tuned LLMs, demonstrating that TGPT achieves superior predictive accuracy as well as faster training and inference. We anticipate that the architectural innovations and practical guidelines from this work will advance foundation models for transaction-like data and catalyze future research in this emerging field.
Illuminating LLM Coding Agents: Visual Analytics for Deeper Understanding and Enhancement
Aug 18, 2025Coding agents powered by large language models (LLMs) have gained traction for automating code generation through iterative problem-solving with minimal human involvement. Despite the emergence of various frameworks, e.g., LangChain, AutoML, and AIDE, ML scientists still struggle to effectively review and adjust the agents' coding process. The current approach of manually inspecting individual outputs is inefficient, making it difficult to track code evolution, compare coding iterations, and identify improvement opportunities. To address this challenge, we introduce a visual analytics system designed to enhance the examination of coding agent behaviors. Focusing on the AIDE framework, our system supports comparative analysis across three levels: (1) Code-Level Analysis, which reveals how the agent debugs and refines its code over iterations; (2) Process-Level Analysis, which contrasts different solution-seeking processes explored by the agent; and (3) LLM-Level Analysis, which highlights variations in coding behavior across different LLMs. By integrating these perspectives, our system enables ML scientists to gain a structured understanding of agent behaviors, facilitating more effective debugging and prompt engineering. Through case studies using coding agents to tackle popular Kaggle competitions, we demonstrate how our system provides valuable insights into the iterative coding process.
Empowering Time Series Forecasting with LLM-Agents
Aug 06, 2025Large Language Model (LLM) powered agents have emerged as effective planners for Automated Machine Learning (AutoML) systems. While most existing AutoML approaches focus on automating feature engineering and model architecture search, recent studies in time series forecasting suggest that lightweight models can often achieve state-of-the-art performance. This observation led us to explore improving data quality, rather than model architecture, as a potentially fruitful direction for AutoML on time series data. We propose DCATS, a Data-Centric Agent for Time Series. DCATS leverages metadata accompanying time series to clean data while optimizing forecasting performance. We evaluated DCATS using four time series forecasting models on a large-scale traffic volume forecasting dataset. Results demonstrate that DCATS achieves an average 6% error reduction across all tested models and time horizons, highlighting the potential of data-centric approaches in AutoML for time series forecasting.
Towards Efficient Large Scale Spatial-Temporal Time Series Forecasting via Improved Inverted Transformers
Mar 13, 2025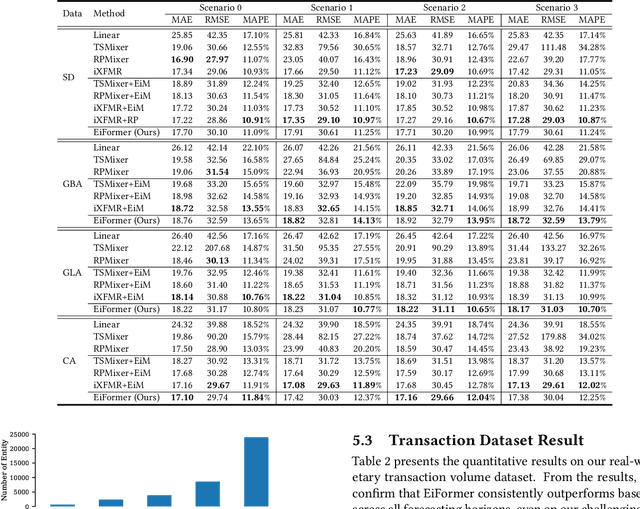
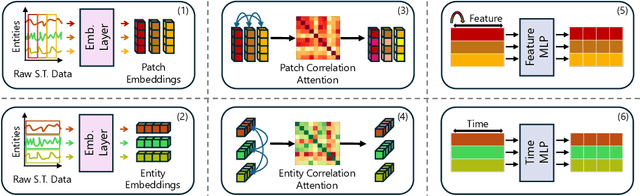
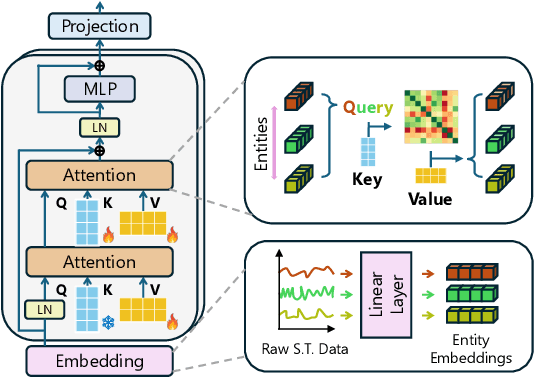
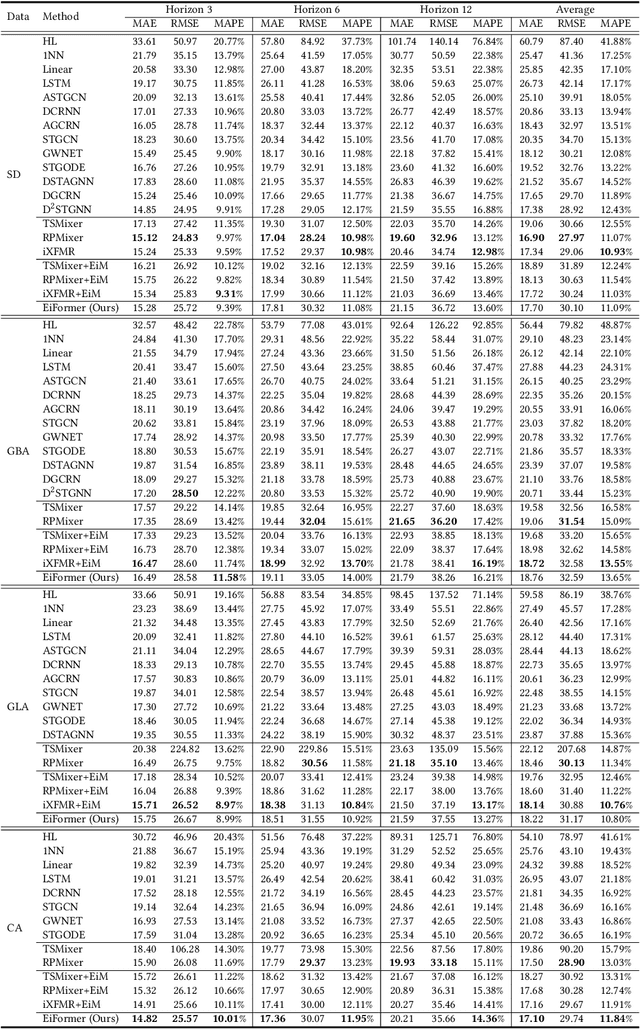
Time series forecasting at scale presents significant challenges for modern prediction systems, particularly when dealing with large sets of synchronized series, such as in a global payment network. In such systems, three key challenges must be overcome for accurate and scalable predictions: 1) emergence of new entities, 2) disappearance of existing entities, and 3) the large number of entities present in the data. The recently proposed Inverted Transformer (iTransformer) architecture has shown promising results by effectively handling variable entities. However, its practical application in large-scale settings is limited by quadratic time and space complexity ($O(N^2)$) with respect to the number of entities $N$. In this paper, we introduce EiFormer, an improved inverted transformer architecture that maintains the adaptive capabilities of iTransformer while reducing computational complexity to linear scale ($O(N)$). Our key innovation lies in restructuring the attention mechanism to eliminate redundant computations without sacrificing model expressiveness. Additionally, we incorporate a random projection mechanism that not only enhances efficiency but also improves prediction accuracy through better feature representation. Extensive experiments on the public LargeST benchmark dataset and a proprietary large-scale time series dataset demonstrate that EiFormer significantly outperforms existing methods in both computational efficiency and forecasting accuracy. Our approach enables practical deployment of transformer-based forecasting in industrial applications where handling time series at scale is essential.
A Compact Model for Large-Scale Time Series Forecasting
Feb 28, 2025



Spatio-temporal data, which commonly arise in real-world applications such as traffic monitoring, financial transactions, and ride-share demands, represent a special category of multivariate time series. They exhibit two distinct characteristics: high dimensionality and commensurability across spatial locations. These attributes call for computationally efficient modeling approaches and facilitate the use of univariate forecasting models in a channel-independent fashion. SparseTSF, a recently introduced competitive univariate forecasting model, harnesses periodicity to achieve compactness by concentrating on cross-period dynamics, thereby extending the Pareto frontier with respect to model size and predictive performance. Nonetheless, it underperforms on spatio-temporal data due to an inadequate capture of intra-period temporal dependencies. To address this shortcoming, we propose UltraSTF, which integrates a cross-period forecasting module with an ultra-compact shape bank component. Our model effectively detects recurring patterns in time series through the attention mechanism of the shape bank component, thereby strengthening its ability to learn intra-period dynamics. UltraSTF achieves state-of-the-art performance on the LargeST benchmark while employing fewer than 0.2% of the parameters required by the second-best approaches, thus further extending the Pareto frontier of existing methods.
Visual Attention Exploration in Vision-Based Mamba Models
Feb 28, 2025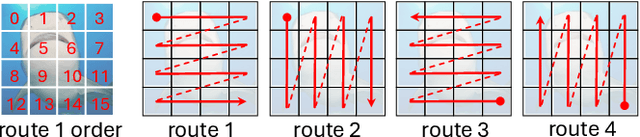
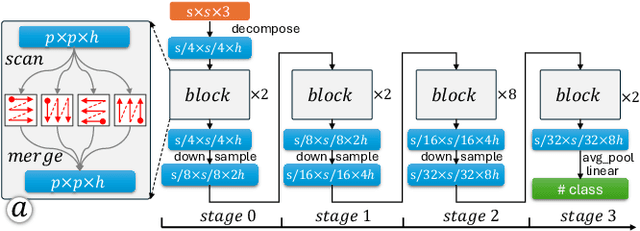
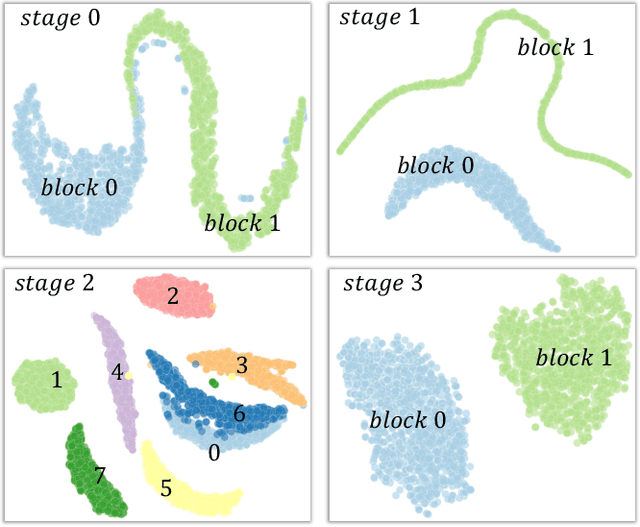
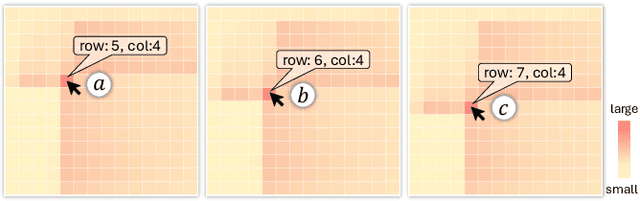
State space models (SSMs) have emerged as an efficient alternative to transformer-based models, offering linear complexity that scales better than transformers. One of the latest advances in SSMs, Mamba, introduces a selective scan mechanism that assigns trainable weights to input tokens, effectively mimicking the attention mechanism. Mamba has also been successfully extended to the vision domain by decomposing 2D images into smaller patches and arranging them as 1D sequences. However, it remains unclear how these patches interact with (or attend to) each other in relation to their original 2D spatial location. Additionally, the order used to arrange the patches into a sequence also significantly impacts their attention distribution. To better understand the attention between patches and explore the attention patterns, we introduce a visual analytics tool specifically designed for vision-based Mamba models. This tool enables a deeper understanding of how attention is distributed across patches in different Mamba blocks and how it evolves throughout a Mamba model. Using the tool, we also investigate the impact of different patch-ordering strategies on the learned attention, offering further insights into the model's behavior.
MAIN-RAG: Multi-Agent Filtering Retrieval-Augmented Generation
Dec 31, 2024



Large Language Models (LLMs) are becoming essential tools for various natural language processing tasks but often suffer from generating outdated or incorrect information. Retrieval-Augmented Generation (RAG) addresses this issue by incorporating external, real-time information retrieval to ground LLM responses. However, the existing RAG systems frequently struggle with the quality of retrieval documents, as irrelevant or noisy documents degrade performance, increase computational overhead, and undermine response reliability. To tackle this problem, we propose Multi-Agent Filtering Retrieval-Augmented Generation (MAIN-RAG), a training-free RAG framework that leverages multiple LLM agents to collaboratively filter and score retrieved documents. Specifically, MAIN-RAG introduces an adaptive filtering mechanism that dynamically adjusts the relevance filtering threshold based on score distributions, effectively minimizing noise while maintaining high recall of relevant documents. The proposed approach leverages inter-agent consensus to ensure robust document selection without requiring additional training data or fine-tuning. Experimental results across four QA benchmarks demonstrate that MAIN-RAG consistently outperforms traditional RAG approaches, achieving a 2-11% improvement in answer accuracy while reducing the number of irrelevant retrieved documents. Quantitative analysis further reveals that our approach achieves superior response consistency and answer accuracy over baseline methods, offering a competitive and practical alternative to training-based solutions.
Matrix Profile for Anomaly Detection on Multidimensional Time Series
Sep 14, 2024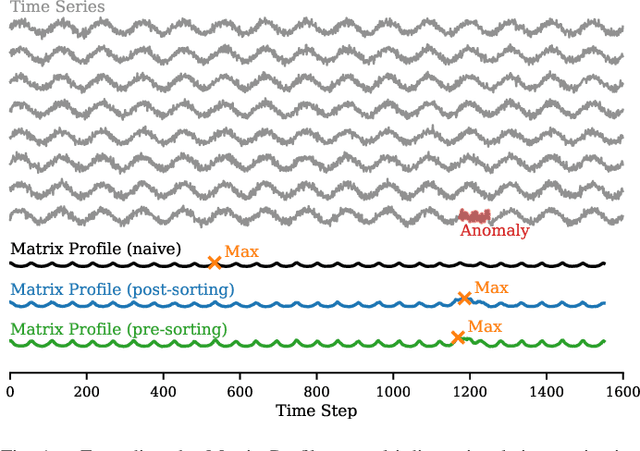
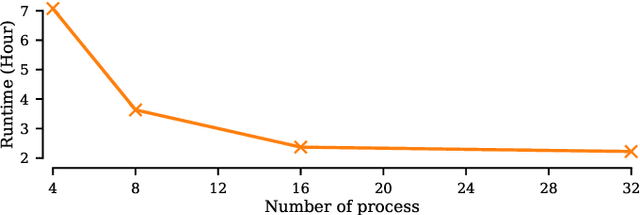
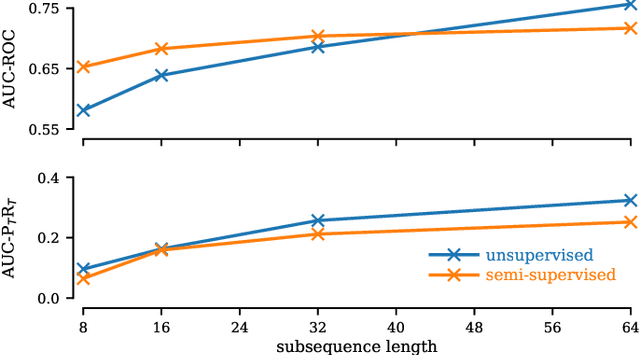
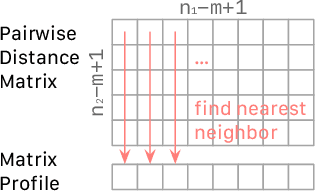
The Matrix Profile (MP), a versatile tool for time series data mining, has been shown effective in time series anomaly detection (TSAD). This paper delves into the problem of anomaly detection in multidimensional time series, a common occurrence in real-world applications. For instance, in a manufacturing factory, multiple sensors installed across the site collect time-varying data for analysis. The Matrix Profile, named for its role in profiling the matrix storing pairwise distance between subsequences of univariate time series, becomes complex in multidimensional scenarios. If the input univariate time series has n subsequences, the pairwise distance matrix is a n x n matrix. In a multidimensional time series with d dimensions, the pairwise distance information must be stored in a n x n x d tensor. In this paper, we first analyze different strategies for condensing this tensor into a profile vector. We then investigate the potential of extending the MP to efficiently find k-nearest neighbors for anomaly detection. Finally, we benchmark the multidimensional MP against 19 baseline methods on 119 multidimensional TSAD datasets. The experiments covers three learning setups: unsupervised, supervised, and semi-supervised. MP is the only method that consistently delivers high performance across all setups.
Preserving Individuality while Following the Crowd: Understanding the Role of User Taste and Crowd Wisdom in Online Product Rating Prediction
Sep 06, 2024



Numerous algorithms have been developed for online product rating prediction, but the specific influence of user and product information in determining the final prediction score remains largely unexplored. Existing research often relies on narrowly defined data settings, which overlooks real-world challenges such as the cold-start problem, cross-category information utilization, and scalability and deployment issues. To delve deeper into these aspects, and particularly to uncover the roles of individual user taste and collective wisdom, we propose a unique and practical approach that emphasizes historical ratings at both the user and product levels, encapsulated using a continuously updated dynamic tree representation. This representation effectively captures the temporal dynamics of users and products, leverages user information across product categories, and provides a natural solution to the cold-start problem. Furthermore, we have developed an efficient data processing strategy that makes this approach highly scalable and easily deployable. Comprehensive experiments in real industry settings demonstrate the effectiveness of our approach. Notably, our findings reveal that individual taste dominates over collective wisdom in online product rating prediction, a perspective that contrasts with the commonly observed wisdom of the crowd phenomenon in other domains. This dominance of individual user taste is consistent across various model types, including the boosting tree model, recurrent neural network (RNN), and transformer-based architectures. This observation holds true across the overall population, within individual product categories, and in cold-start scenarios. Our findings underscore the significance of individual user tastes in the context of online product rating prediction and the robustness of our approach across different model architectures.
A Systematic Evaluation of Generated Time Series and Their Effects in Self-Supervised Pretraining
Aug 15, 2024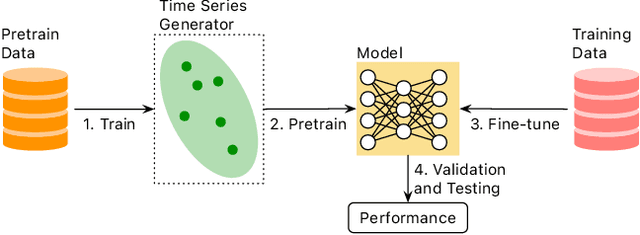



Self-supervised Pretrained Models (PTMs) have demonstrated remarkable performance in computer vision and natural language processing tasks. These successes have prompted researchers to design PTMs for time series data. In our experiments, most self-supervised time series PTMs were surpassed by simple supervised models. We hypothesize this undesired phenomenon may be caused by data scarcity. In response, we test six time series generation methods, use the generated data in pretraining in lieu of the real data, and examine the effects on classification performance. Our results indicate that replacing a real-data pretraining set with a greater volume of only generated samples produces noticeable improvement.