 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePUPAE: Intuitive and Actionable Explanations for Time Series Anomalies
Jan 16, 2024



In recent years there has been significant progress in time series anomaly detection. However, after detecting an (perhaps tentative) anomaly, can we explain it? Such explanations would be useful to triage anomalies. For example, in an oil refinery, should we respond to an anomaly by dispatching a hydraulic engineer, or an intern to replace the battery on a sensor? There have been some parallel efforts to explain anomalies, however many proposed techniques produce explanations that are indirect, and often seem more complex than the anomaly they seek to explain. Our review of the literature/checklists/user-manuals used by frontline practitioners in various domains reveals an interesting near-universal commonality. Most practitioners discuss, explain and report anomalies in the following format: The anomaly would be like normal data A, if not for the corruption B. The reader will appreciate that is a type of counterfactual explanation. In this work we introduce a domain agnostic counterfactual explanation technique to produce explanations for time series anomalies. As we will show, our method can produce both visual and text-based explanations that are objectively correct, intuitive and in many circumstances, directly actionable.
* 9 Page Manuscript, 1 Page Supplementary (Supplement not published in conference proceedings.)
When is Early Classification of Time Series Meaningful?
Feb 23, 2021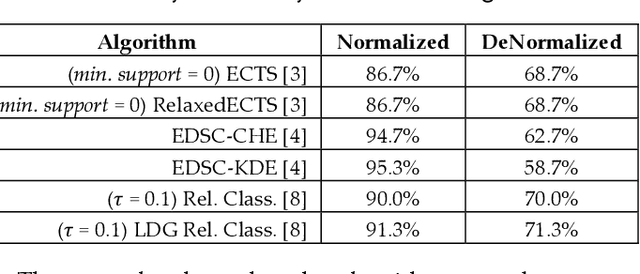
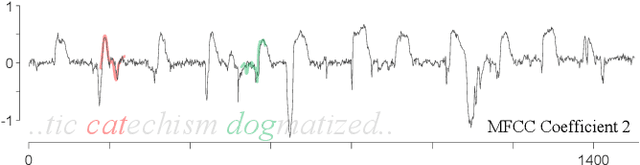
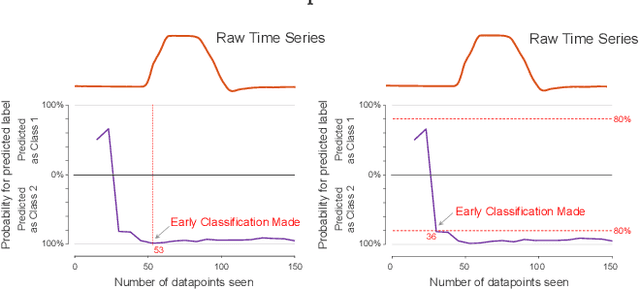
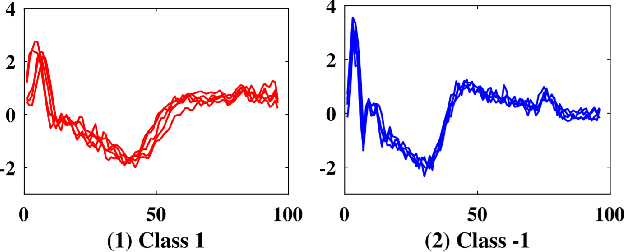
Since its introduction two decades ago, there has been increasing interest in the problem of early classification of time series. This problem generalizes classic time series classification to ask if we can classify a time series subsequence with sufficient accuracy and confidence after seeing only some prefix of a target pattern. The idea is that the earlier classification would allow us to take immediate action, in a domain in which some practical interventions are possible. For example, that intervention might be sounding an alarm or applying the brakes in an automobile. In this work, we make a surprising claim. In spite of the fact that there are dozens of papers on early classification of time series, it is not clear that any of them could ever work in a real-world setting. The problem is not with the algorithms per se but with the vague and underspecified problem description. Essentially all algorithms make implicit and unwarranted assumptions about the problem that will ensure that they will be plagued by false positives and false negatives even if their results suggested that they could obtain near-perfect results. We will explain our findings with novel insights and experiments and offer recommendations to the community.
Current Time Series Anomaly Detection Benchmarks are Flawed and are Creating the Illusion of Progress
Oct 08, 2020
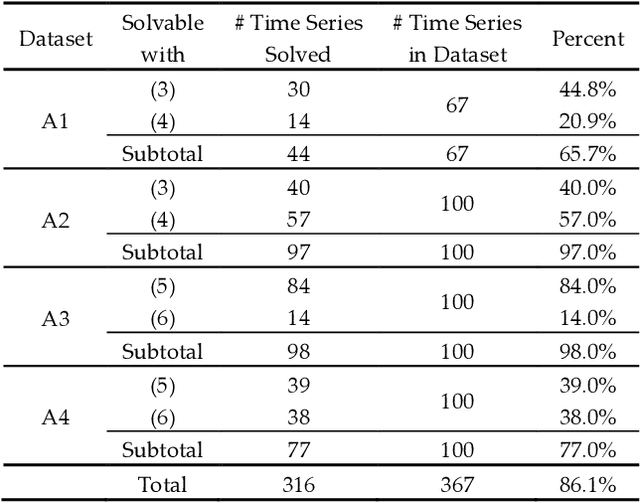
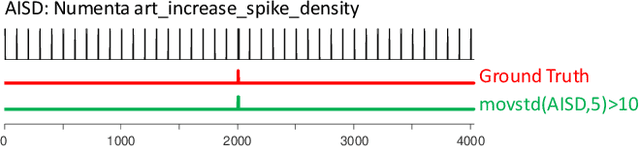
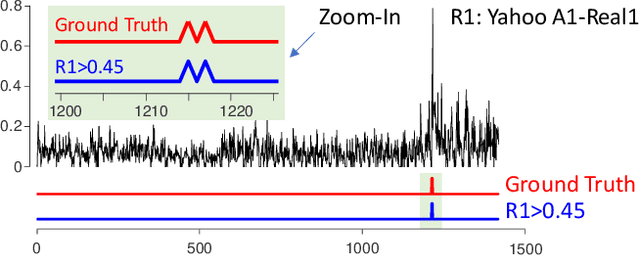
Time series anomaly detection has been a perennially important topic in data science, with papers dating back to the 1950s. However, in recent years there has been an explosion of interest in this topic, much of it driven by the success of deep learning in other domains and for other time series tasks. Most of these papers test on one or more of a handful of popular benchmark datasets, created by Yahoo, Numenta, NASA, etc. In this work we make a surprising claim. The majority of the individual exemplars in these datasets suffer from one or more of four flaws. Because of these four flaws, we believe that many published comparisons of anomaly detection algorithms may be unreliable, and more importantly, much of the apparent progress in recent years may be illusionary. In addition to demonstrating these claims, with this paper we introduce the UCR Time Series Anomaly Datasets. We believe that this resource will perform a similar role as the UCR Time Series Classification Archive, by providing the community with a benchmark that allows meaningful comparisons between approaches and a meaningful gauge of overall progress.
FastDTW is approximate and Generally Slower than the Algorithm it Approximates
Mar 25, 2020

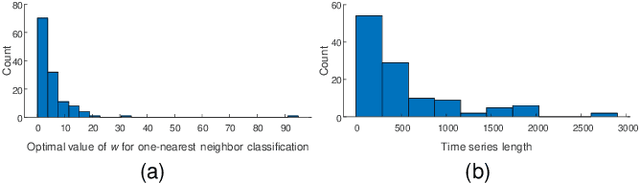

Many time series data mining problems can be solved with repeated use of distance measure. Examples of such tasks include similarity search, clustering, classification, anomaly detection and segmentation. For over two decades it has been known that the Dynamic Time Warping (DTW) distance measure is the best measure to use for most tasks, in most domains. Because the classic DTW algorithm has quadratic time complexity, many ideas have been introduced to reduce its amortized time, or to quickly approximate it. One of the most cited approximate approaches is FastDTW. The FastDTW algorithm has well over a thousand citations and has been explicitly used in several hundred research efforts. In this work, we make a surprising claim. In any realistic data mining application, the approximate FastDTW is much slower than the exact DTW. This fact clearly has implications for the community that uses this algorithm: allowing it to address much larger datasets, get exact results, and do so in less time. Our observation also has a more sobering lesson for the community. This work may serve as a reminder to the community to exercise more caution in uncritically accepting published results.
Time Series Classification: Lessons Learned in the (Literal) Field while Studying Chicken Behavior
Dec 20, 2019

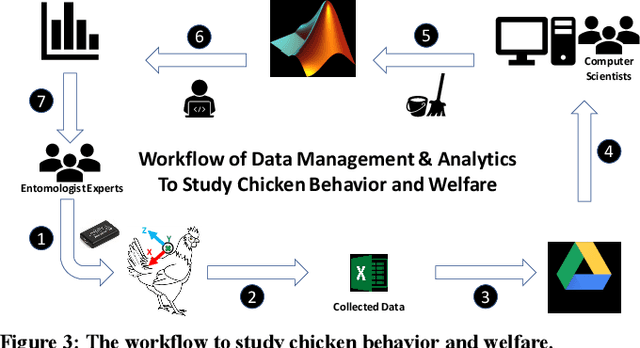
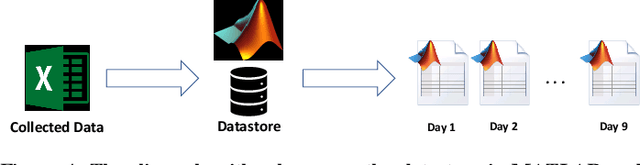
Poultry farms are a major contributor to the human food chain. However, around the world, there have been growing concerns about the quality of life for the livestock in poultry farms; and increasingly vocal demands for improved standards of animal welfare. Recent advances in sensing technologies and machine learning allow the possibility of monitoring birds, and employing the lessons learned to improve the welfare for all birds. This task superficially appears to be easy, yet, studying behavioral patterns involves collecting enormous amounts of data, justifying the term Big Data. Before the big data can be used for analytical purposes to tease out meaningful, well-conserved behavioral patterns, the collected data needs to be pre-processed. The pre-processing refers to processes for cleansing and preparing data so that it is in the format ready to be analyzed by downstream algorithms, such as classification and clustering algorithms. However, as we shall demonstrate, efficient pre-processing of chicken big data is both non-trivial and crucial towards success of further analytics.
Time Series Classification to Improve Poultry Welfare
Nov 07, 2018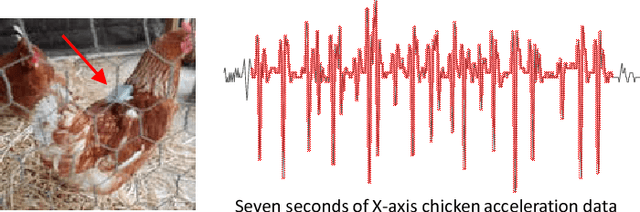
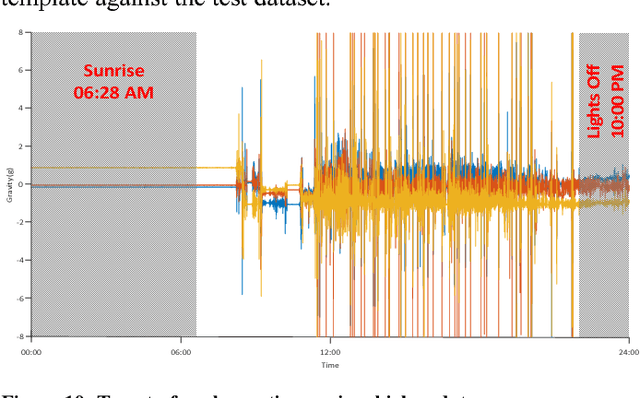

Poultry farms are an important contributor to the human food chain. Worldwide, humankind keeps an enormous number of domesticated birds (e.g. chickens) for their eggs and their meat, providing rich sources of low-fat protein. However, around the world, there have been growing concerns about the quality of life for the livestock in poultry farms; and increasingly vocal demands for improved standards of animal welfare. Recent advances in sensing technologies and machine learning allow the possibility of automatically assessing the health of some individual birds, and employing the lessons learned to improve the welfare for all birds. This task superficially appears to be easy, given the dramatic progress in recent years in classifying human behaviors, and given that human behaviors are presumably more complex. However, as we shall demonstrate, classifying chicken behaviors poses several unique challenges, chief among which is creating a generalizable dictionary of behaviors from sparse and noisy data. In this work we introduce a novel time series dictionary learning algorithm that can robustly learn from weakly labeled data sources.