 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge\textit{4DSurf}: High-Fidelity Dynamic Scene Surface Reconstruction
Mar 30, 2026This paper addresses the problem of dynamic scene surface reconstruction using Gaussian Splatting (GS), aiming to recover temporally consistent geometry. While existing GS-based dynamic surface reconstruction methods can yield superior reconstruction, they are typically limited to either a single object or objects with only small deformations, struggling to maintain temporally consistent surface reconstruction of large deformations over time. We propose ``\textit{4DSurf}'', a novel and unified framework for generic dynamic surface reconstruction that does not require specifying the number or types of objects in the scene, can handle large surface deformations and temporal inconsistency in reconstruction. The key innovation of our framework is the introduction of Gaussian deformations induced Signed Distance Function Flow Regularization that constrains the motion of Gaussians to align with the evolving surface. To handle large deformations, we introduce an Overlapping Segment Partitioning strategy that divides the sequence into overlapping segments with small deformations and incrementally passes geometric information across segments through the shared overlapping timestep. Experiments on two challenging dynamic scene datasets, Hi4D and CMU Panoptic, demonstrate that our method outperforms state-of-the-art surface reconstruction methods by 49\% and 19\% in Chamfer distance, respectively, and achieves superior temporal consistency under sparse-view settings.
Gemma 3 Technical Report
Mar 25, 2025We introduce Gemma 3, a multimodal addition to the Gemma family of lightweight open models, ranging in scale from 1 to 27 billion parameters. This version introduces vision understanding abilities, a wider coverage of languages and longer context - at least 128K tokens. We also change the architecture of the model to reduce the KV-cache memory that tends to explode with long context. This is achieved by increasing the ratio of local to global attention layers, and keeping the span on local attention short. The Gemma 3 models are trained with distillation and achieve superior performance to Gemma 2 for both pre-trained and instruction finetuned versions. In particular, our novel post-training recipe significantly improves the math, chat, instruction-following and multilingual abilities, making Gemma3-4B-IT competitive with Gemma2-27B-IT and Gemma3-27B-IT comparable to Gemini-1.5-Pro across benchmarks. We release all our models to the community.
A Comprehensive Survey on Deep Multimodal Learning with Missing Modality
Sep 12, 2024
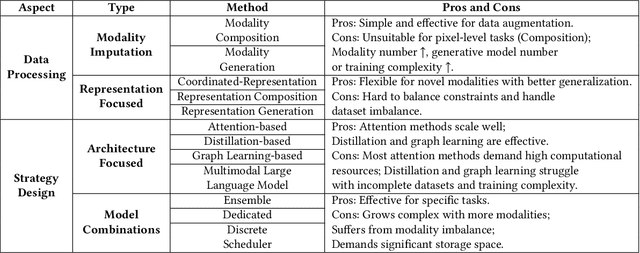
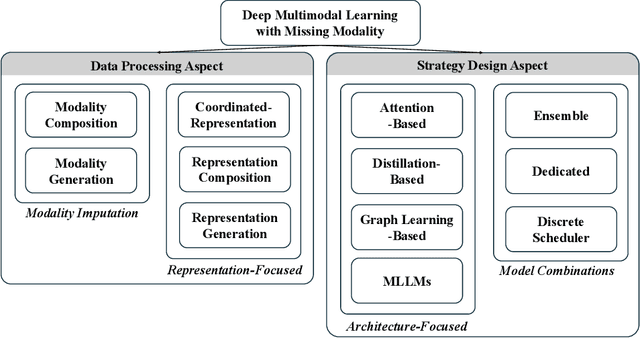

During multimodal model training and reasoning, data samples may miss certain modalities and lead to compromised model performance due to sensor limitations, cost constraints, privacy concerns, data loss, and temporal and spatial factors. This survey provides an overview of recent progress in Multimodal Learning with Missing Modality (MLMM), focusing on deep learning techniques. It is the first comprehensive survey that covers the historical background and the distinction between MLMM and standard multimodal learning setups, followed by a detailed analysis of current MLMM methods, applications, and datasets, concluding with a discussion about challenges and potential future directions in the field.
Segment Beyond View: Handling Partially Missing Modality for Audio-Visual Semantic Segmentation
Dec 14, 2023



Augmented Reality (AR) devices, emerging as prominent mobile interaction platforms, face challenges in user safety, particularly concerning oncoming vehicles. While some solutions leverage onboard camera arrays, these cameras often have limited field-of-view (FoV) with front or downward perspectives. Addressing this, we propose a new out-of-view semantic segmentation task and Segment Beyond View (SBV), a novel audio-visual semantic segmentation method. SBV supplements the visual modality, which miss the information beyond FoV, with the auditory information using a teacher-student distillation model (Omni2Ego). The model consists of a vision teacher utilising panoramic information, an auditory teacher with 8-channel audio, and an audio-visual student that takes views with limited FoV and binaural audio as input and produce semantic segmentation for objects outside FoV. SBV outperforms existing models in comparative evaluations and shows a consistent performance across varying FoV ranges and in monaural audio settings.
Matrix Profile XXVII: A Novel Distance Measure for Comparing Long Time Series
Dec 09, 2022



The most useful data mining primitives are distance measures. With an effective distance measure, it is possible to perform classification, clustering, anomaly detection, segmentation, etc. For single-event time series Euclidean Distance and Dynamic Time Warping distance are known to be extremely effective. However, for time series containing cyclical behaviors, the semantic meaningfulness of such comparisons is less clear. For example, on two separate days the telemetry from an athlete workout routine might be very similar. The second day may change the order in of performing push-ups and squats, adding repetitions of pull-ups, or completely omitting dumbbell curls. Any of these minor changes would defeat existing time series distance measures. Some bag-of-features methods have been proposed to address this problem, but we argue that in many cases, similarity is intimately tied to the shapes of subsequences within these longer time series. In such cases, summative features will lack discrimination ability. In this work we introduce PRCIS, which stands for Pattern Representation Comparison in Series. PRCIS is a distance measure for long time series, which exploits recent progress in our ability to summarize time series with dictionaries. We will demonstrate the utility of our ideas on diverse tasks and datasets.
When is Early Classification of Time Series Meaningful?
Feb 23, 2021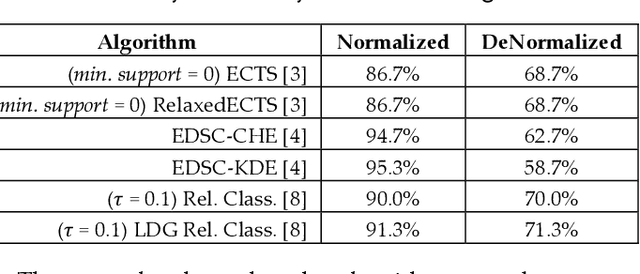
Since its introduction two decades ago, there has been increasing interest in the problem of early classification of time series. This problem generalizes classic time series classification to ask if we can classify a time series subsequence with sufficient accuracy and confidence after seeing only some prefix of a target pattern. The idea is that the earlier classification would allow us to take immediate action, in a domain in which some practical interventions are possible. For example, that intervention might be sounding an alarm or applying the brakes in an automobile. In this work, we make a surprising claim. In spite of the fact that there are dozens of papers on early classification of time series, it is not clear that any of them could ever work in a real-world setting. The problem is not with the algorithms per se but with the vague and underspecified problem description. Essentially all algorithms make implicit and unwarranted assumptions about the problem that will ensure that they will be plagued by false positives and false negatives even if their results suggested that they could obtain near-perfect results. We will explain our findings with novel insights and experiments and offer recommendations to the community.
DCCRGAN: Deep Complex Convolution Recurrent Generator Adversarial Network for Speech Enhancement
Dec 19, 2020
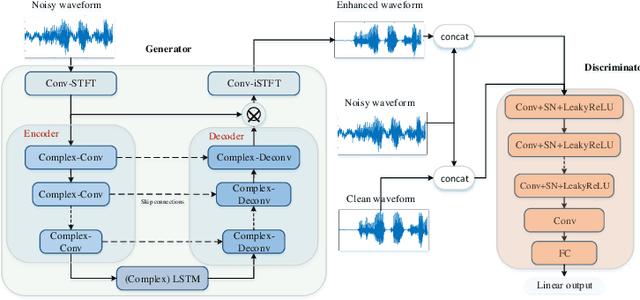
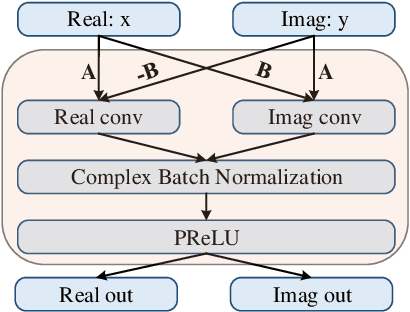
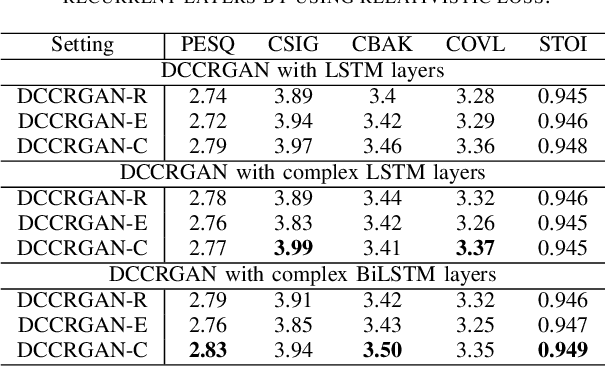
Generative adversarial network (GAN) still exists some problems in dealing with speech enhancement (SE) task. Some GAN-based systems adopt the same structure from Pixel-to-Pixel directly without special optimization. The importance of the generator network has not been fully explored. Other related researches change the generator network but operate in the time-frequency domain, which ignores the phase mismatch problem. In order to solve these problems, a deep complex convolution recurrent GAN (DCCRGAN) structure is proposed in this paper. The complex module builds the correlation between magnitude and phase of the waveform and has been proved to be effective. The proposed structure is trained in an end-to-end way. Different LSTM layers are used in the generator network to sufficiently explore the speech enhancement performance of DCCRGAN. The experimental results confirm that the proposed DCCRGAN outperforms the state-of-the-art GAN-based SE systems.
Current Time Series Anomaly Detection Benchmarks are Flawed and are Creating the Illusion of Progress
Oct 08, 2020
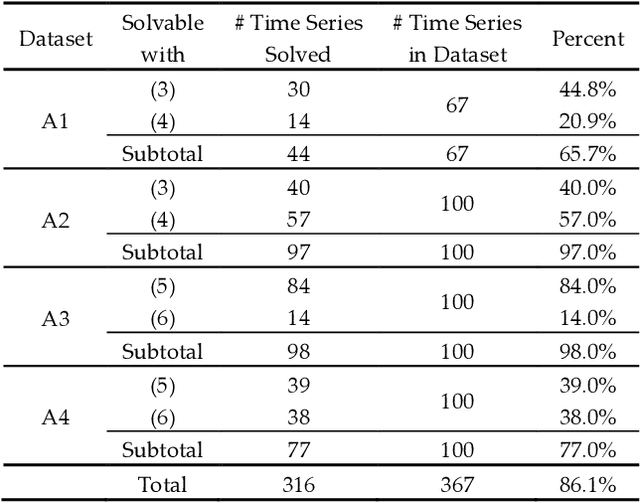
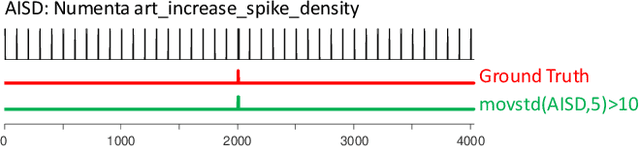
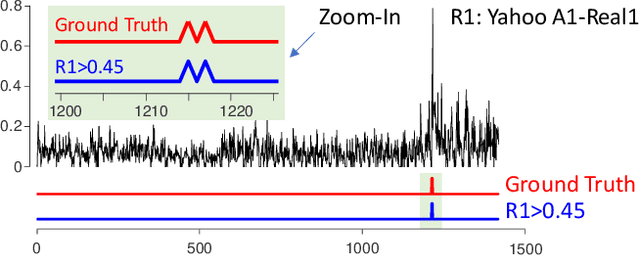
Time series anomaly detection has been a perennially important topic in data science, with papers dating back to the 1950s. However, in recent years there has been an explosion of interest in this topic, much of it driven by the success of deep learning in other domains and for other time series tasks. Most of these papers test on one or more of a handful of popular benchmark datasets, created by Yahoo, Numenta, NASA, etc. In this work we make a surprising claim. The majority of the individual exemplars in these datasets suffer from one or more of four flaws. Because of these four flaws, we believe that many published comparisons of anomaly detection algorithms may be unreliable, and more importantly, much of the apparent progress in recent years may be illusionary. In addition to demonstrating these claims, with this paper we introduce the UCR Time Series Anomaly Datasets. We believe that this resource will perform a similar role as the UCR Time Series Classification Archive, by providing the community with a benchmark that allows meaningful comparisons between approaches and a meaningful gauge of overall progress.
FastDTW is approximate and Generally Slower than the Algorithm it Approximates
Mar 25, 2020

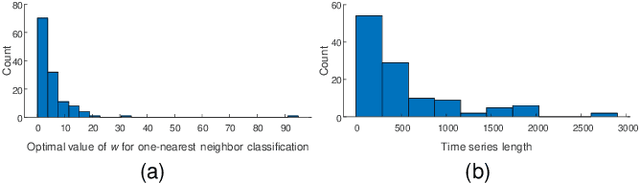

Many time series data mining problems can be solved with repeated use of distance measure. Examples of such tasks include similarity search, clustering, classification, anomaly detection and segmentation. For over two decades it has been known that the Dynamic Time Warping (DTW) distance measure is the best measure to use for most tasks, in most domains. Because the classic DTW algorithm has quadratic time complexity, many ideas have been introduced to reduce its amortized time, or to quickly approximate it. One of the most cited approximate approaches is FastDTW. The FastDTW algorithm has well over a thousand citations and has been explicitly used in several hundred research efforts. In this work, we make a surprising claim. In any realistic data mining application, the approximate FastDTW is much slower than the exact DTW. This fact clearly has implications for the community that uses this algorithm: allowing it to address much larger datasets, get exact results, and do so in less time. Our observation also has a more sobering lesson for the community. This work may serve as a reminder to the community to exercise more caution in uncritically accepting published results.