 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeltaMCP: Incremental Regeneration via Spec-Aware Transformation for MCP servers
May 27, 2026The rapid development of LLMs coupled with the introduction of Model Context Protocol (MCP) has revolutionized how intelligent agents interact with APIs through deterministic and structured methods \cite{ModelContextProtocolIntro2025}. While some existing systems like AutoMCP attempt to automate a previously completely manual process of generating MCP servers, they fail to address the recurring challenge of maintaining synchronization between evolving enterprise-level APIs and their corresponding MCP toolset implementation \cite{mastouri2025makingrestapisagentready}. This paper introduces DeltaMCP, a specification-aware, incremental regeneration tool for enterprise-grade MCP servers. DeltaMCP enables developers to only update the affected tooling of MCP servers, given a new release of it's corresponding service's OpenAPI specification. Using Azure REST API specifications as the evaluation dataset, DeltaMCP is benchmarked against baseline full generation methods on generation quality and system performance. The results demonstrate the reduction in developer overhead through DeltaMCP whilst improving maintainability and version consistency. This research offers a scalable approach for enterprises seeking to maintain high-fidelity, up-to-date MCP server infrastructures for LLM-based systems.
Understanding Annotation Error Propagation and Learning an Adaptive Policy for Expert Intervention in Barrett's Video Segmentation
Feb 25, 2026Accurate annotation of endoscopic videos is essential yet time-consuming, particularly for challenging datasets such as dysplasia in Barrett's esophagus, where the affected regions are irregular and lack clear boundaries. Semi-automatic tools like Segment Anything Model 2 (SAM2) can ease this process by propagating annotations across frames, but small errors often accumulate and reduce accuracy, requiring expert review and correction. To address this, we systematically study how annotation errors propagate across different prompt types, namely masks, boxes, and points, and propose Learning-to-Re-Prompt (L2RP), a cost-aware framework that learns when and where to seek expert input. By tuning a human-cost parameter, our method balances annotation effort and segmentation accuracy. Experiments on a private Barrett's dysplasia dataset and the public SUN-SEG benchmark demonstrate improved temporal consistency and superior performance over baseline strategies.
OUGS: Active View Selection via Object-aware Uncertainty Estimation in 3DGS
Nov 12, 2025Recent advances in 3D Gaussian Splatting (3DGS) have achieved state-of-the-art results for novel view synthesis. However, efficiently capturing high-fidelity reconstructions of specific objects within complex scenes remains a significant challenge. A key limitation of existing active reconstruction methods is their reliance on scene-level uncertainty metrics, which are often biased by irrelevant background clutter and lead to inefficient view selection for object-centric tasks. We present OUGS, a novel framework that addresses this challenge with a more principled, physically-grounded uncertainty formulation for 3DGS. Our core innovation is to derive uncertainty directly from the explicit physical parameters of the 3D Gaussian primitives (e.g., position, scale, rotation). By propagating the covariance of these parameters through the rendering Jacobian, we establish a highly interpretable uncertainty model. This foundation allows us to then seamlessly integrate semantic segmentation masks to produce a targeted, object-aware uncertainty score that effectively disentangles the object from its environment. This allows for a more effective active view selection strategy that prioritizes views critical to improving object fidelity. Experimental evaluations on public datasets demonstrate that our approach significantly improves the efficiency of the 3DGS reconstruction process and achieves higher quality for targeted objects compared to existing state-of-the-art methods, while also serving as a robust uncertainty estimator for the global scene.
CLOC: Contrastive Learning for Ordinal Classification with Multi-Margin N-pair Loss
Apr 22, 2025In ordinal classification, misclassifying neighboring ranks is common, yet the consequences of these errors are not the same. For example, misclassifying benign tumor categories is less consequential, compared to an error at the pre-cancerous to cancerous threshold, which could profoundly influence treatment choices. Despite this, existing ordinal classification methods do not account for the varying importance of these margins, treating all neighboring classes as equally significant. To address this limitation, we propose CLOC, a new margin-based contrastive learning method for ordinal classification that learns an ordered representation based on the optimization of multiple margins with a novel multi-margin n-pair loss (MMNP). CLOC enables flexible decision boundaries across key adjacent categories, facilitating smooth transitions between classes and reducing the risk of overfitting to biases present in the training data. We provide empirical discussion regarding the properties of MMNP and show experimental results on five real-world image datasets (Adience, Historical Colour Image Dating, Knee Osteoarthritis, Indian Diabetic Retinopathy Image, and Breast Carcinoma Subtyping) and one synthetic dataset simulating clinical decision bias. Our results demonstrate that CLOC outperforms existing ordinal classification methods and show the interpretability and controllability of CLOC in learning meaningful, ordered representations that align with clinical and practical needs.
A Comprehensive Survey on Deep Multimodal Learning with Missing Modality
Sep 12, 2024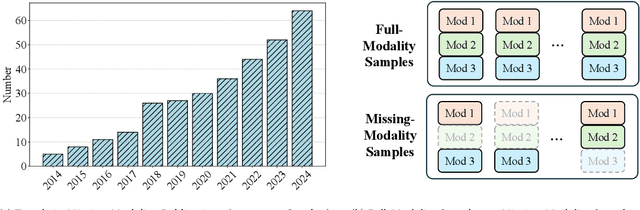
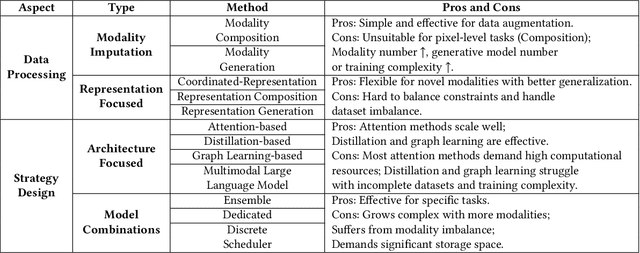
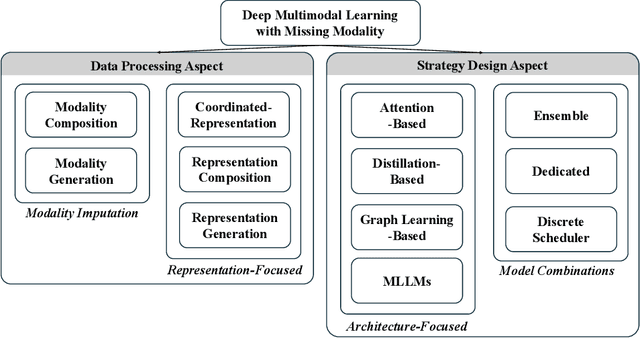

During multimodal model training and reasoning, data samples may miss certain modalities and lead to compromised model performance due to sensor limitations, cost constraints, privacy concerns, data loss, and temporal and spatial factors. This survey provides an overview of recent progress in Multimodal Learning with Missing Modality (MLMM), focusing on deep learning techniques. It is the first comprehensive survey that covers the historical background and the distinction between MLMM and standard multimodal learning setups, followed by a detailed analysis of current MLMM methods, applications, and datasets, concluding with a discussion about challenges and potential future directions in the field.
WebVLN: Vision-and-Language Navigation on Websites
Dec 25, 2023Vision-and-Language Navigation (VLN) task aims to enable AI agents to accurately understand and follow natural language instructions to navigate through real-world environments, ultimately reaching specific target locations. We recognise a promising opportunity to extend VLN to a comparable navigation task that holds substantial significance in our daily lives, albeit within the virtual realm: navigating websites on the Internet. This paper proposes a new task named Vision-and-Language Navigation on Websites (WebVLN), where we use question-based instructions to train an agent, emulating how users naturally browse websites. Unlike the existing VLN task that only pays attention to vision and instruction (language), the WebVLN agent further considers underlying web-specific content like HTML, which could not be seen on the rendered web pages yet contains rich visual and textual information. Toward this goal, we contribute a dataset, WebVLN-v1, and introduce a novel approach called Website-aware VLN Network (WebVLN-Net), which is built upon the foundation of state-of-the-art VLN techniques. Experimental results show that WebVLN-Net outperforms current VLN and web-related navigation methods. We believe that the introduction of the new WebVLN task and its dataset will establish a new dimension within the VLN domain and contribute to the broader vision-and-language research community. The code is available at: https://github.com/WebVLN/WebVLN.
Segment Beyond View: Handling Partially Missing Modality for Audio-Visual Semantic Segmentation
Dec 14, 2023



Augmented Reality (AR) devices, emerging as prominent mobile interaction platforms, face challenges in user safety, particularly concerning oncoming vehicles. While some solutions leverage onboard camera arrays, these cameras often have limited field-of-view (FoV) with front or downward perspectives. Addressing this, we propose a new out-of-view semantic segmentation task and Segment Beyond View (SBV), a novel audio-visual semantic segmentation method. SBV supplements the visual modality, which miss the information beyond FoV, with the auditory information using a teacher-student distillation model (Omni2Ego). The model consists of a vision teacher utilising panoramic information, an auditory teacher with 8-channel audio, and an audio-visual student that takes views with limited FoV and binaural audio as input and produce semantic segmentation for objects outside FoV. SBV outperforms existing models in comparative evaluations and shows a consistent performance across varying FoV ranges and in monaural audio settings.
Identification of EEG Dynamics During Freezing of Gait and Voluntary Stopping in Patients with Parkinson's Disease
Feb 06, 2021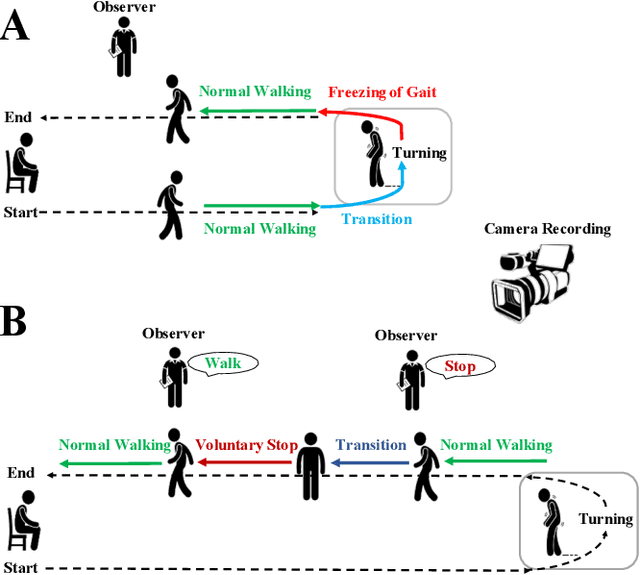
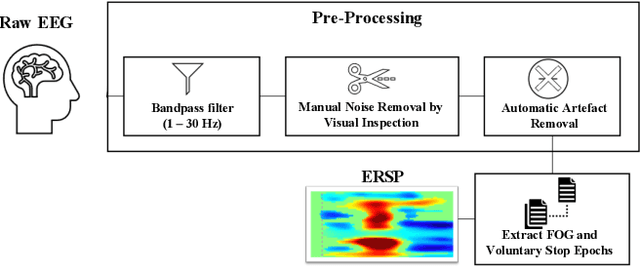
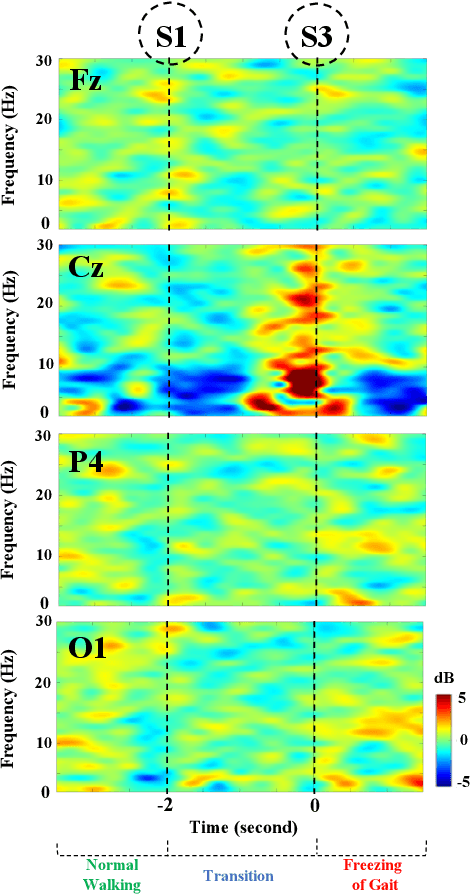
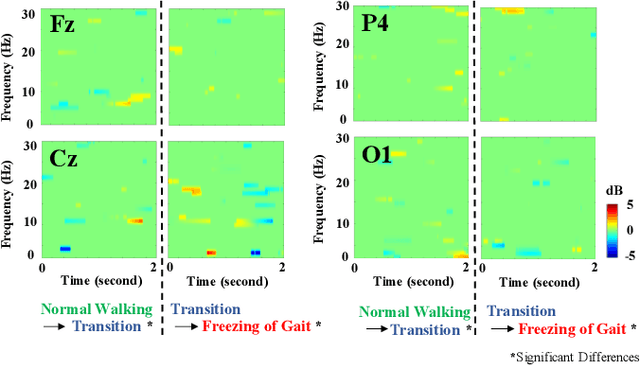
Mobility is severely impacted in patients with Parkinson's disease (PD), especially when they experience involuntary stopping from the freezing of gait (FOG). Understanding the neurophysiological difference between "voluntary stopping" and "involuntary stopping" caused by FOG is vital for the detection and potential intervention of FOG in the daily lives of patients. This study characterised the electroencephalographic (EEG) signature associated with FOG in contrast to voluntary stopping. The protocol consisted of a timed up-and-go (TUG) task and an additional TUG task with a voluntary stopping component, where participants reacted to verbal "stop" and "walk" instructions by voluntarily stopping or walking. Event-related spectral perturbation (ERSP) analysis was used to study the dynamics of the EEG spectra induced by different walking phases, which included normal walking, voluntary stopping and episodes of involuntary stopping (FOG), as well as the transition windows between normal walking and voluntary stopping or FOG. These results demonstrate for the first time that the EEG signal during the transition from walking to voluntary stopping is distinguishable from that of the transition to involuntary stopping caused by FOG. The EEG signature of voluntary stopping exhibits a significantly decreased power spectrum compared to that of FOG episodes, with distinctly different patterns in the delta and low-beta power in the central area. These findings suggest the possibility of a practical EEG-based treatment strategy that can accurately predict FOG episodes, excluding the potential confound of voluntary stopping.