 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMSTAR: Multi-Scale Backbone Architecture Search for Timeseries Classification
Feb 21, 2024



Most of the previous approaches to Time Series Classification (TSC) highlight the significance of receptive fields and frequencies while overlooking the time resolution. Hence, unavoidably suffered from scalability issues as they integrated an extensive range of receptive fields into classification models. Other methods, while having a better adaptation for large datasets, require manual design and yet not being able to reach the optimal architecture due to the uniqueness of each dataset. We overcome these challenges by proposing a novel multi-scale search space and a framework for Neural architecture search (NAS), which addresses both the problem of frequency and time resolution, discovering the suitable scale for a specific dataset. We further show that our model can serve as a backbone to employ a powerful Transformer module with both untrained and pre-trained weights. Our search space reaches the state-of-the-art performance on four datasets on four different domains while introducing more than ten highly fine-tuned models for each data.
Interference Cancellation GAN Framework for Dynamic Channels
Aug 17, 2022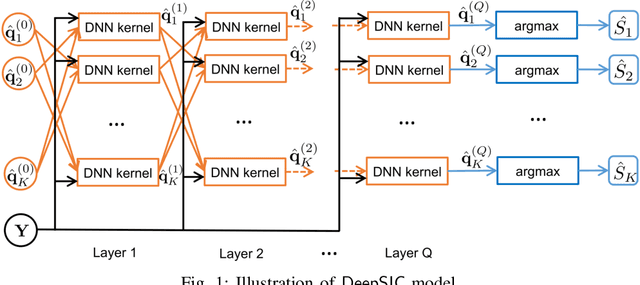
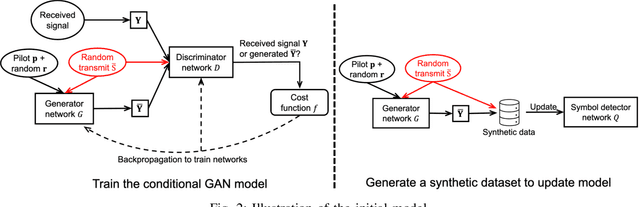
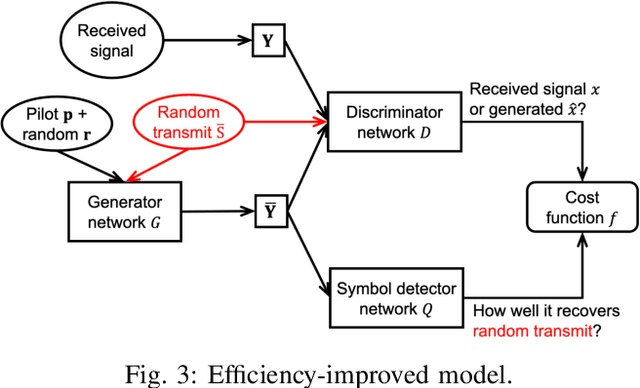
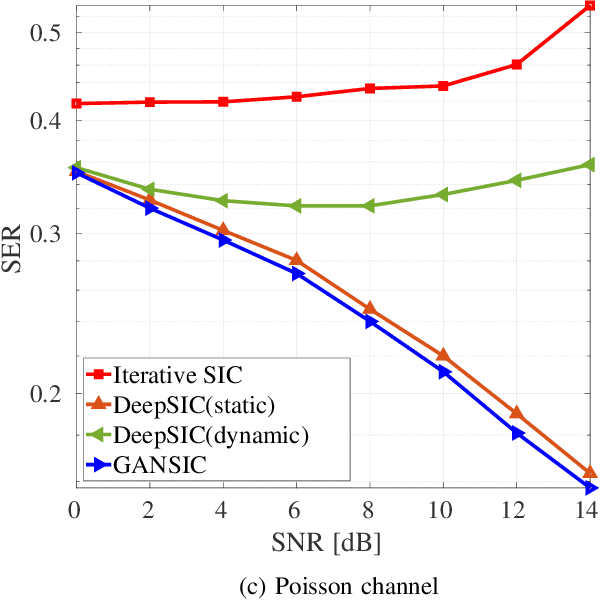
Symbol detection is a fundamental and challenging problem in modern communication systems, e.g., multiuser multiple-input multiple-output (MIMO) setting. Iterative Soft Interference Cancellation (SIC) is a state-of-the-art method for this task and recently motivated data-driven neural network models, e.g. DeepSIC, that can deal with unknown non-linear channels. However, these neural network models require thorough timeconsuming training of the networks before applying, and is thus not readily suitable for highly dynamic channels in practice. We introduce an online training framework that can swiftly adapt to any changes in the channel. Our proposed framework unifies the recent deep unfolding approaches with the emerging generative adversarial networks (GANs) to capture any changes in the channel and quickly adjust the networks to maintain the top performance of the model. We demonstrate that our framework significantly outperforms recent neural network models on highly dynamic channels and even surpasses those on the static channel in our experiments.
Contextual Model Aggregation for Fast and Robust Federated Learning in Edge Computing
Mar 23, 2022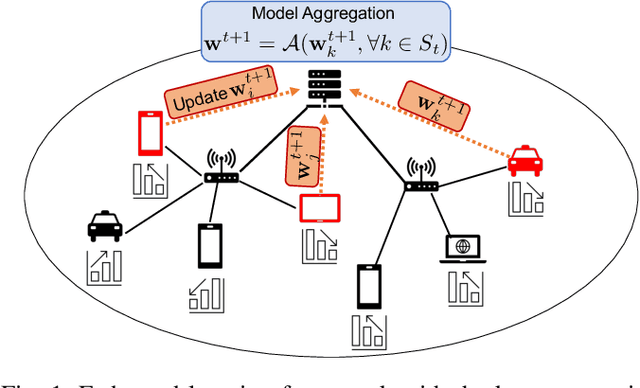
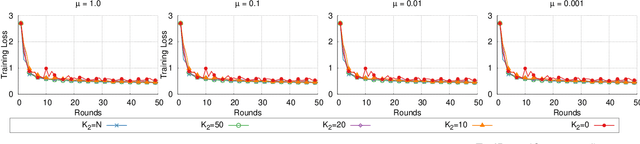
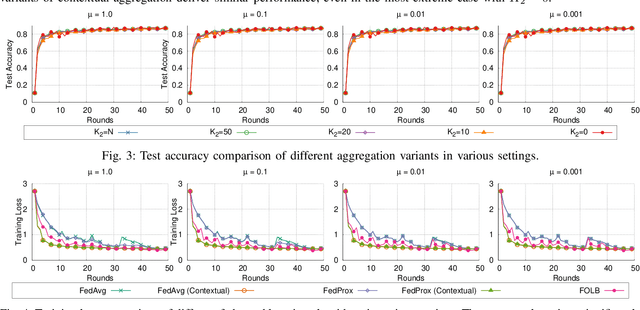
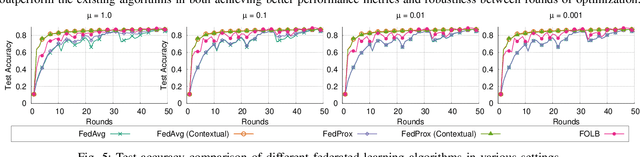
Federated learning is a prime candidate for distributed machine learning at the network edge due to the low communication complexity and privacy protection among other attractive properties. However, existing algorithms face issues with slow convergence and/or robustness of performance due to the considerable heterogeneity of data distribution, computation and communication capability at the edge. In this work, we tackle both of these issues by focusing on the key component of model aggregation in federated learning systems and studying optimal algorithms to perform this task. Particularly, we propose a contextual aggregation scheme that achieves the optimal context-dependent bound on loss reduction in each round of optimization. The aforementioned context-dependent bound is derived from the particular participating devices in that round and an assumption on smoothness of the overall loss function. We show that this aggregation leads to a definite reduction of loss function at every round. Furthermore, we can integrate our aggregation with many existing algorithms to obtain the contextual versions. Our experimental results demonstrate significant improvements in convergence speed and robustness of the contextual versions compared to the original algorithms. We also consider different variants of the contextual aggregation and show robust performance even in the most extreme settings.
Adversarial Neural Networks for Error Correcting Codes
Dec 21, 2021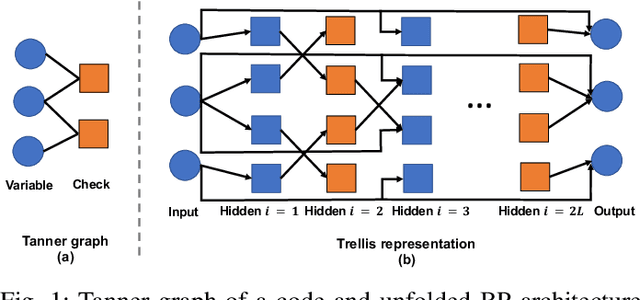
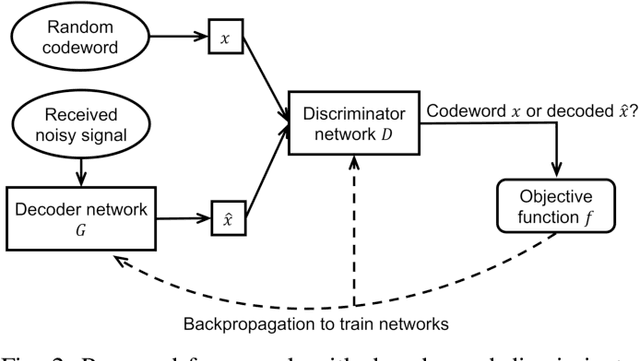
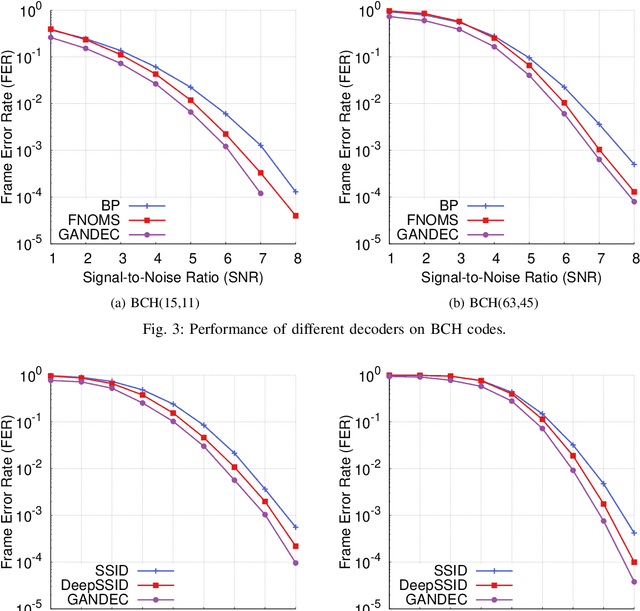
Error correcting codes are a fundamental component in modern day communication systems, demanding extremely high throughput, ultra-reliability and low latency. Recent approaches using machine learning (ML) models as the decoders offer both improved performance and great adaptability to unknown environments, where traditional decoders struggle. We introduce a general framework to further boost the performance and applicability of ML models. We propose to combine ML decoders with a competing discriminator network that tries to distinguish between codewords and noisy words, and, hence, guides the decoding models to recover transmitted codewords. Our framework is game-theoretic, motivated by generative adversarial networks (GANs), with the decoder and discriminator competing in a zero-sum game. The decoder learns to simultaneously decode and generate codewords while the discriminator learns to tell the differences between decoded outputs and codewords. Thus, the decoder is able to decode noisy received signals into codewords, increasing the probability of successful decoding. We show a strong connection of our framework with the optimal maximum likelihood decoder by proving that this decoder defines a Nash equilibrium point of our game. Hence, training to equilibrium has a good possibility of achieving the optimal maximum likelihood performance. Moreover, our framework does not require training labels, which are typically unavailable during communications, and, thus, seemingly can be trained online and adapt to channel dynamics. To demonstrate the performance of our framework, we combine it with the very recent neural decoders and show improved performance compared to the original models and traditional decoding algorithms on various codes.
On-the-fly Resource-Aware Model Aggregation for Federated Learning in Heterogeneous Edge
Dec 21, 2021

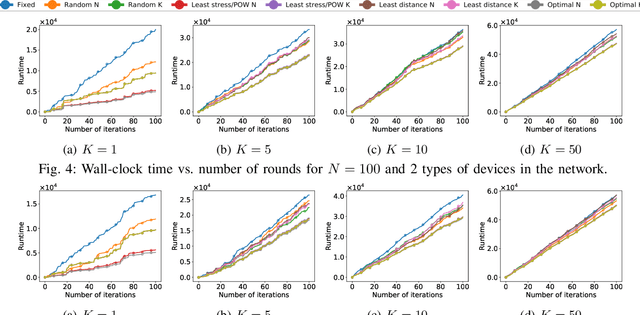
Edge computing has revolutionized the world of mobile and wireless networks world thanks to its flexible, secure, and performing characteristics. Lately, we have witnessed the increasing use of it to make more performing the deployment of machine learning (ML) techniques such as federated learning (FL). FL was debuted to improve communication efficiency compared to conventional distributed machine learning (ML). The original FL assumes a central aggregation server to aggregate locally optimized parameters and might bring reliability and latency issues. In this paper, we conduct an in-depth study of strategies to replace this central server by a flying master that is dynamically selected based on the current participants and/or available resources at every FL round of optimization. Specifically, we compare different metrics to select this flying master and assess consensus algorithms to perform the selection. Our results demonstrate a significant reduction of runtime using our flying master FL framework compared to the original FL from measurements results conducted in our EdgeAI testbed and over real 5G networks using an operational edge testbed.
Identification of EEG Dynamics During Freezing of Gait and Voluntary Stopping in Patients with Parkinson's Disease
Feb 06, 2021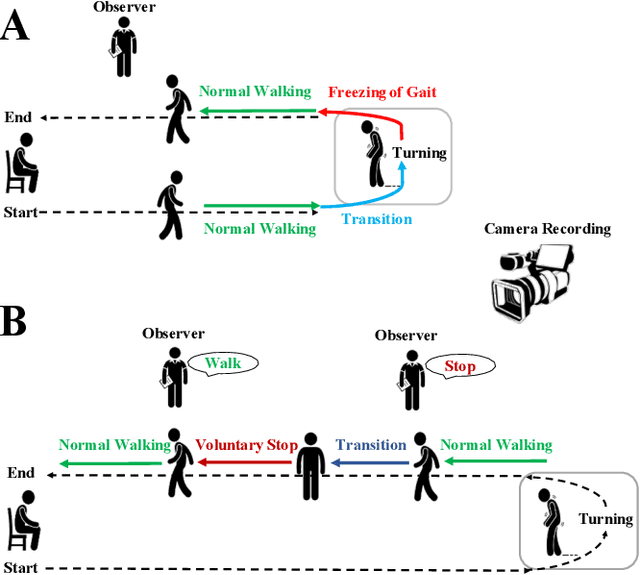
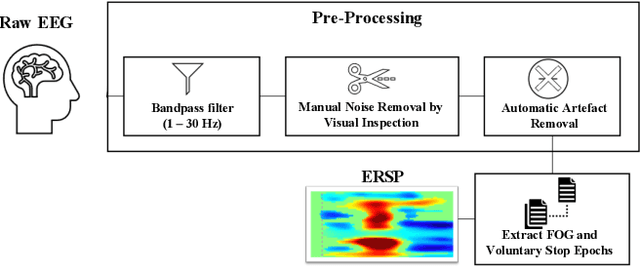
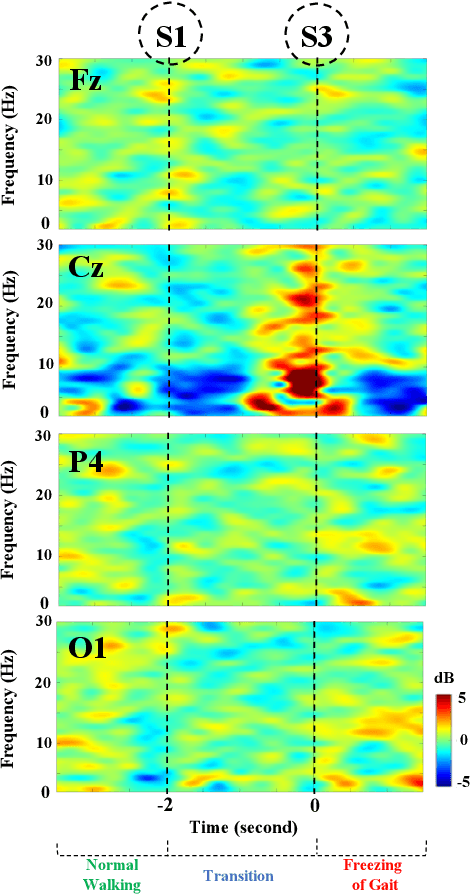
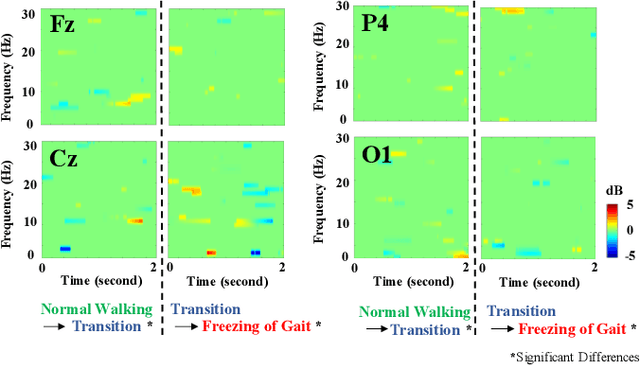
Mobility is severely impacted in patients with Parkinson's disease (PD), especially when they experience involuntary stopping from the freezing of gait (FOG). Understanding the neurophysiological difference between "voluntary stopping" and "involuntary stopping" caused by FOG is vital for the detection and potential intervention of FOG in the daily lives of patients. This study characterised the electroencephalographic (EEG) signature associated with FOG in contrast to voluntary stopping. The protocol consisted of a timed up-and-go (TUG) task and an additional TUG task with a voluntary stopping component, where participants reacted to verbal "stop" and "walk" instructions by voluntarily stopping or walking. Event-related spectral perturbation (ERSP) analysis was used to study the dynamics of the EEG spectra induced by different walking phases, which included normal walking, voluntary stopping and episodes of involuntary stopping (FOG), as well as the transition windows between normal walking and voluntary stopping or FOG. These results demonstrate for the first time that the EEG signal during the transition from walking to voluntary stopping is distinguishable from that of the transition to involuntary stopping caused by FOG. The EEG signature of voluntary stopping exhibits a significantly decreased power spectrum compared to that of FOG episodes, with distinctly different patterns in the delta and low-beta power in the central area. These findings suggest the possibility of a practical EEG-based treatment strategy that can accurately predict FOG episodes, excluding the potential confound of voluntary stopping.
Anomaly Detection in Large Labeled Multi-Graph Databases
Oct 07, 2020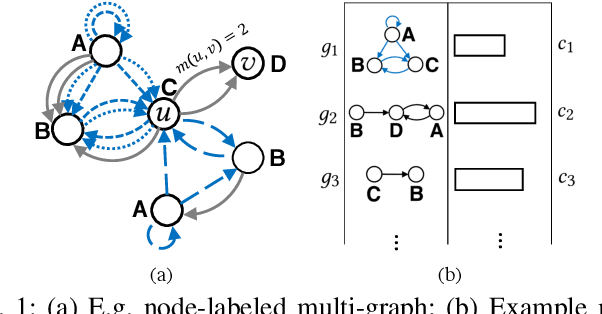

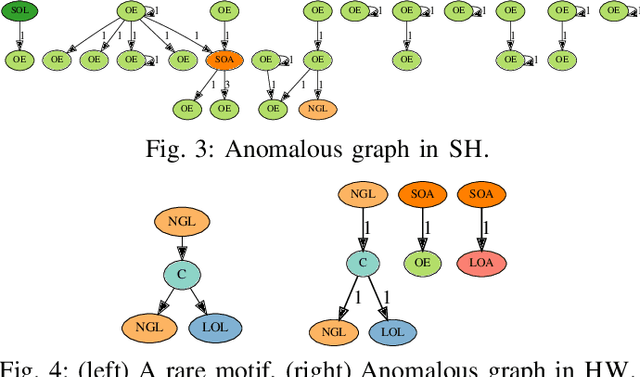

Within a large database G containing graphs with labeled nodes and directed, multi-edges; how can we detect the anomalous graphs? Most existing work are designed for plain (unlabeled) and/or simple (unweighted) graphs. We introduce CODETECT, the first approach that addresses the anomaly detection task for graph databases with such complex nature. To this end, it identifies a small representative set S of structural patterns (i.e., node-labeled network motifs) that losslessly compress database G as concisely as possible. Graphs that do not compress well are flagged as anomalous. CODETECT exhibits two novel building blocks: (i) a motif-based lossless graph encoding scheme, and (ii) fast memory-efficient search algorithms for S. We show the effectiveness of CODETECT on transaction graph databases from three different corporations, where existing baselines adjusted for the task fall behind significantly, across different types of anomalies and performance metrics.
Fast-Convergent Federated Learning
Jul 26, 2020
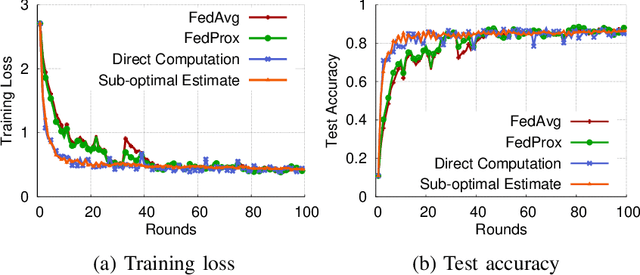
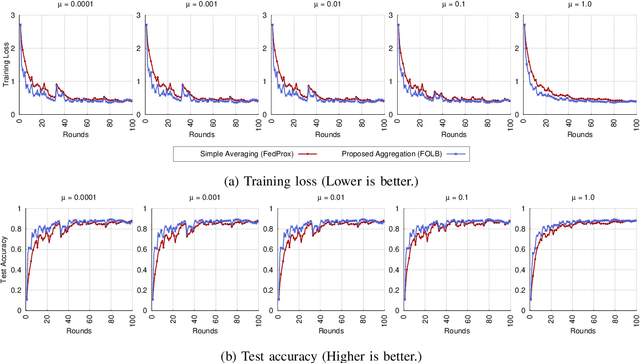
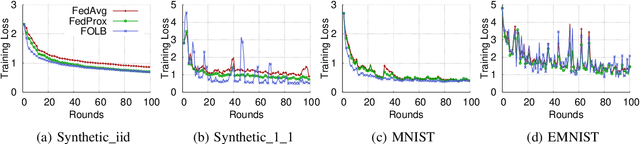
Federated learning has emerged recently as a promising solution for distributing machine learning tasks through modern networks of mobile devices. Recent studies have obtained lower bounds on the expected decrease in model loss that is achieved through each round of federated learning. However, convergence generally requires a large number of communication rounds, which induces delay in model training and is costly in terms of network resources. In this paper, we propose a fast-convergent federated learning algorithm, called FOLB, which obtains significant improvements in convergence speed through intelligent sampling of devices in each round of model training. We first theoretically characterize a lower bound on improvement that can be obtained in each round if devices are selected according to the expected improvement their local models will provide to the current global model. Then, we show that FOLB obtains this bound through uniform sampling by weighting device updates according to their gradient information. FOLB is able to handle both communication and computation heterogeneity of devices by adapting the aggregations according to estimates of device's capabilities of contributing to the updates. We evaluate FOLB in comparison with existing federated learning algorithms and experimentally show its improvement in training loss and test accuracy across various machine learning tasks and datasets.