 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHopTrack: A Real-time Multi-Object Tracking System for Embedded Devices
Nov 01, 2024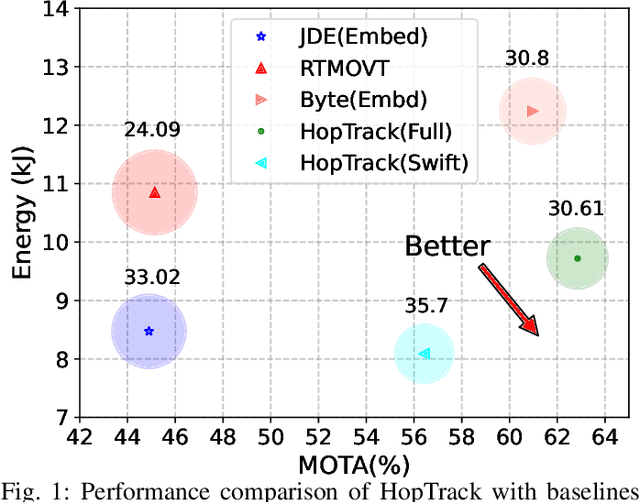
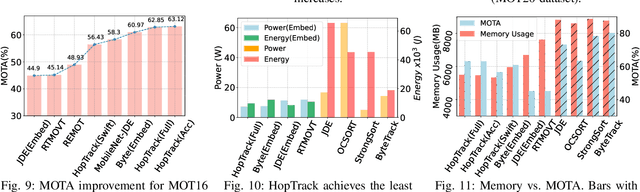
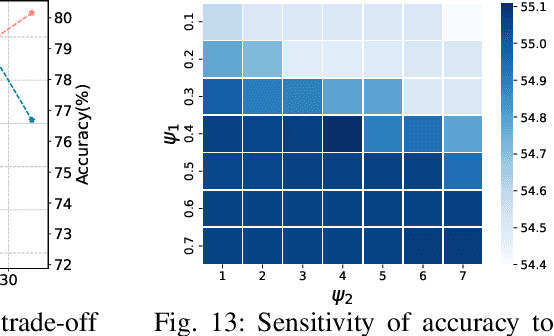
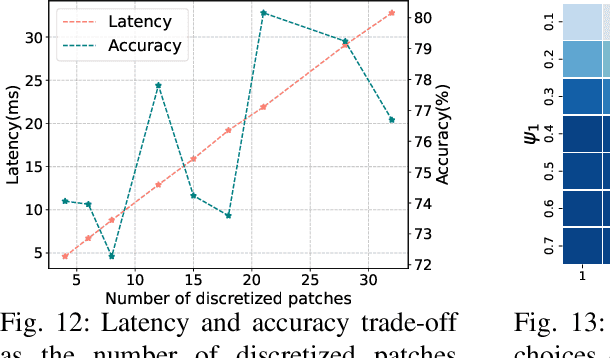
Multi-Object Tracking (MOT) poses significant challenges in computer vision. Despite its wide application in robotics, autonomous driving, and smart manufacturing, there is limited literature addressing the specific challenges of running MOT on embedded devices. State-of-the-art MOT trackers designed for high-end GPUs often experience low processing rates (<11fps) when deployed on embedded devices. Existing MOT frameworks for embedded devices proposed strategies such as fusing the detector model with the feature embedding model to reduce inference latency or combining different trackers to improve tracking accuracy, but tend to compromise one for the other. This paper introduces HopTrack, a real-time multi-object tracking system tailored for embedded devices. Our system employs a novel discretized static and dynamic matching approach along with an innovative content-aware dynamic sampling technique to enhance tracking accuracy while meeting the real-time requirement. Compared with the best high-end GPU modified baseline Byte (Embed) and the best existing baseline on embedded devices MobileNet-JDE, HopTrack achieves a processing speed of up to 39.29 fps on NVIDIA AGX Xavier with a multi-object tracking accuracy (MOTA) of up to 63.12% on the MOT16 benchmark, outperforming both counterparts by 2.15% and 4.82%, respectively. Additionally, the accuracy improvement is coupled with the reduction in energy consumption (20.8%), power (5%), and memory usage (8%), which are crucial resources on embedded devices. HopTrack is also detector agnostic allowing the flexibility of plug-and-play.
E-MPC: Edge-assisted Model Predictive Control
Oct 01, 2024



Model predictive control (MPC) has become the de facto standard action space for local planning and learning-based control in many continuous robotic control tasks, including autonomous driving. MPC solves a long-horizon cost optimization as a series of short-horizon optimizations based on a global planner-supplied reference path. The primary challenge in MPC, however, is that the computational budget for re-planning has a hard limit, which frequently inhibits exact optimization. Modern edge networks provide low-latency communication and heterogeneous properties that can be especially beneficial in this situation. We propose a novel framework for edge-assisted MPC (E-MPC) for path planning that exploits the heterogeneity of edge networks in three important ways: 1) varying computational capacity, 2) localized sensor information, and 3) localized observation histories. Theoretical analysis and extensive simulations are undertaken to demonstrate quantitatively the benefits of E-MPC in various scenarios, including maps, channel dynamics, and availability and density of edge nodes. The results confirm that E-MPC has the potential to reduce costs by a greater percentage than standard MPC does.
Dynamic D2D-Assisted Federated Learning over O-RAN: Performance Analysis, MAC Scheduler, and Asymmetric User Selection
Apr 09, 2024



Existing studies on federated learning (FL) are mostly focused on system orchestration for static snapshots of the network and making static control decisions (e.g., spectrum allocation). However, real-world wireless networks are susceptible to temporal variations of wireless channel capacity and users' datasets. In this paper, we incorporate multi-granular system dynamics (MSDs) into FL, including (M1) dynamic wireless channel capacity, captured by a set of discrete-time events, called $\mathscr{D}$-Events, and (M2) dynamic datasets of users. The latter is characterized by (M2-a) modeling the dynamics of user's dataset size via an ordinary differential equation and (M2-b) introducing dynamic model drift}, formulated via a partial differential inequality} drawing concrete analytical connections between the dynamics of users' datasets and FL accuracy. We then conduct FL orchestration under MSDs by introducing dynamic cooperative FL with dedicated MAC schedulers (DCLM), exploiting the unique features of open radio access network (O-RAN). DCLM proposes (i) a hierarchical device-to-device (D2D)-assisted model training, (ii) dynamic control decisions through dedicated O-RAN MAC schedulers, and (iii) asymmetric user selection. We provide extensive theoretical analysis to study the convergence of DCLM. We then optimize the degrees of freedom (e.g., user selection and spectrum allocation) in DCLM through a highly non-convex optimization problem. We develop a systematic approach to obtain the solution for this problem, opening the door to solving a broad variety of network-aware FL optimization problems. We show the efficiency of DCLM via numerical simulations and provide a series of future directions.
Interference Cancellation GAN Framework for Dynamic Channels
Aug 17, 2022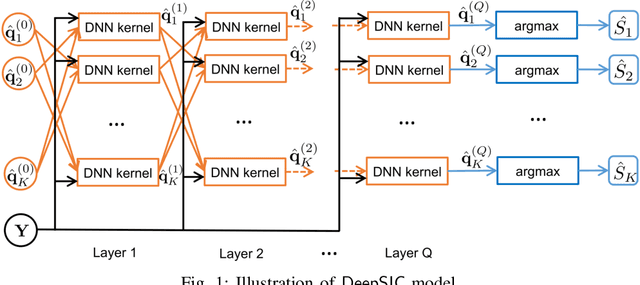
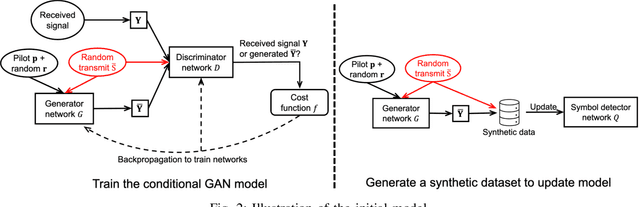
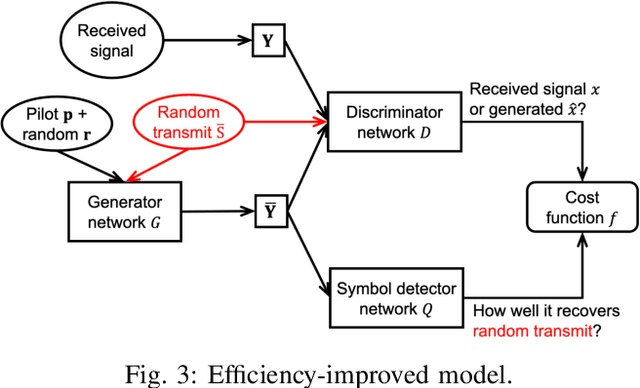
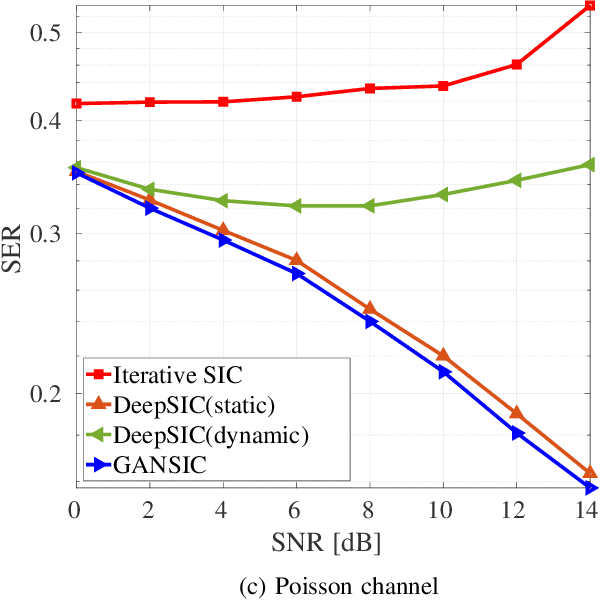
Symbol detection is a fundamental and challenging problem in modern communication systems, e.g., multiuser multiple-input multiple-output (MIMO) setting. Iterative Soft Interference Cancellation (SIC) is a state-of-the-art method for this task and recently motivated data-driven neural network models, e.g. DeepSIC, that can deal with unknown non-linear channels. However, these neural network models require thorough timeconsuming training of the networks before applying, and is thus not readily suitable for highly dynamic channels in practice. We introduce an online training framework that can swiftly adapt to any changes in the channel. Our proposed framework unifies the recent deep unfolding approaches with the emerging generative adversarial networks (GANs) to capture any changes in the channel and quickly adjust the networks to maintain the top performance of the model. We demonstrate that our framework significantly outperforms recent neural network models on highly dynamic channels and even surpasses those on the static channel in our experiments.
Multi-Edge Server-Assisted Dynamic Federated Learning with an Optimized Floating Aggregation Point
Mar 26, 2022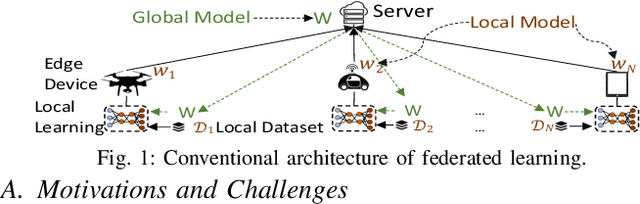
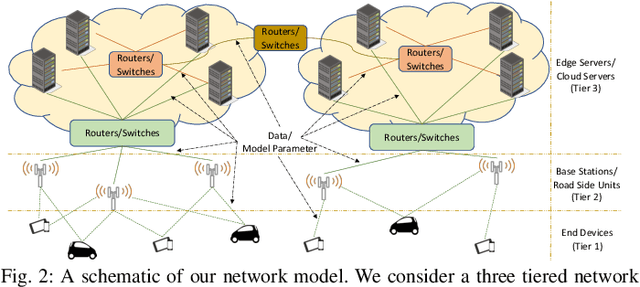
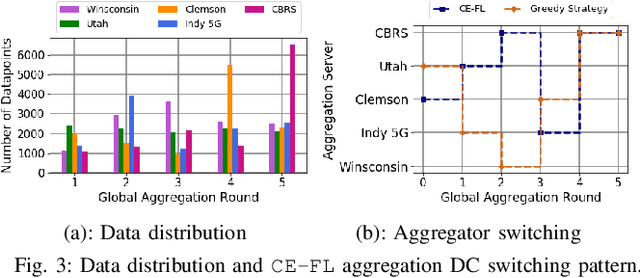
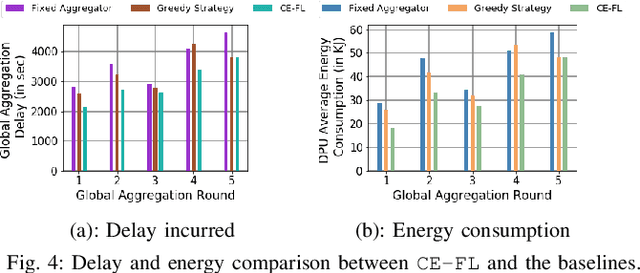
We propose cooperative edge-assisted dynamic federated learning (CE-FL). CE-FL introduces a distributed machine learning (ML) architecture, where data collection is carried out at the end devices, while the model training is conducted cooperatively at the end devices and the edge servers, enabled via data offloading from the end devices to the edge servers through base stations. CE-FL also introduces floating aggregation point, where the local models generated at the devices and the servers are aggregated at an edge server, which varies from one model training round to another to cope with the network evolution in terms of data distribution and users' mobility. CE-FL considers the heterogeneity of network elements in terms of communication/computation models and the proximity to one another. CE-FL further presumes a dynamic environment with online variation of data at the network devices which causes a drift at the ML model performance. We model the processes taken during CE-FL, and conduct analytical convergence analysis of its ML model training. We then formulate network-aware CE-FL which aims to adaptively optimize all the network elements via tuning their contribution to the learning process, which turns out to be a non-convex mixed integer problem. Motivated by the large scale of the system, we propose a distributed optimization solver to break down the computation of the solution across the network elements. We finally demonstrate the effectiveness of our framework with the data collected from a real-world testbed.
Adversarial Neural Networks for Error Correcting Codes
Dec 21, 2021
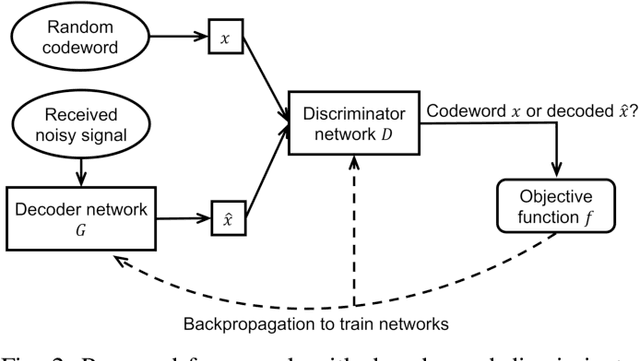
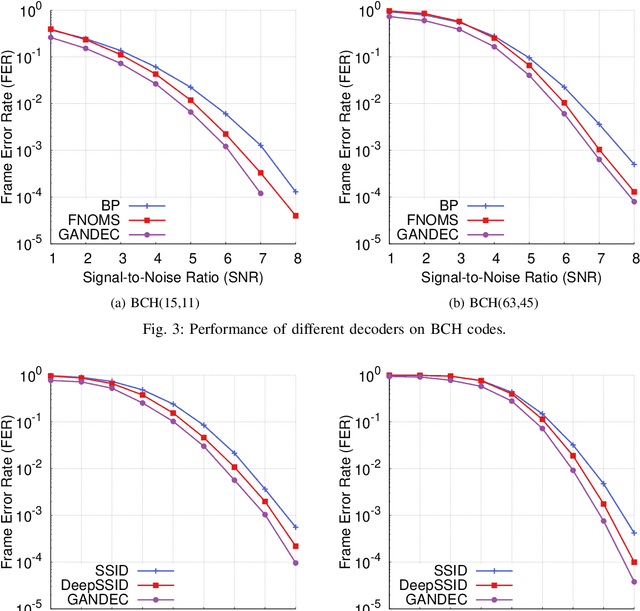
Error correcting codes are a fundamental component in modern day communication systems, demanding extremely high throughput, ultra-reliability and low latency. Recent approaches using machine learning (ML) models as the decoders offer both improved performance and great adaptability to unknown environments, where traditional decoders struggle. We introduce a general framework to further boost the performance and applicability of ML models. We propose to combine ML decoders with a competing discriminator network that tries to distinguish between codewords and noisy words, and, hence, guides the decoding models to recover transmitted codewords. Our framework is game-theoretic, motivated by generative adversarial networks (GANs), with the decoder and discriminator competing in a zero-sum game. The decoder learns to simultaneously decode and generate codewords while the discriminator learns to tell the differences between decoded outputs and codewords. Thus, the decoder is able to decode noisy received signals into codewords, increasing the probability of successful decoding. We show a strong connection of our framework with the optimal maximum likelihood decoder by proving that this decoder defines a Nash equilibrium point of our game. Hence, training to equilibrium has a good possibility of achieving the optimal maximum likelihood performance. Moreover, our framework does not require training labels, which are typically unavailable during communications, and, thus, seemingly can be trained online and adapt to channel dynamics. To demonstrate the performance of our framework, we combine it with the very recent neural decoders and show improved performance compared to the original models and traditional decoding algorithms on various codes.
On-the-fly Resource-Aware Model Aggregation for Federated Learning in Heterogeneous Edge
Dec 21, 2021

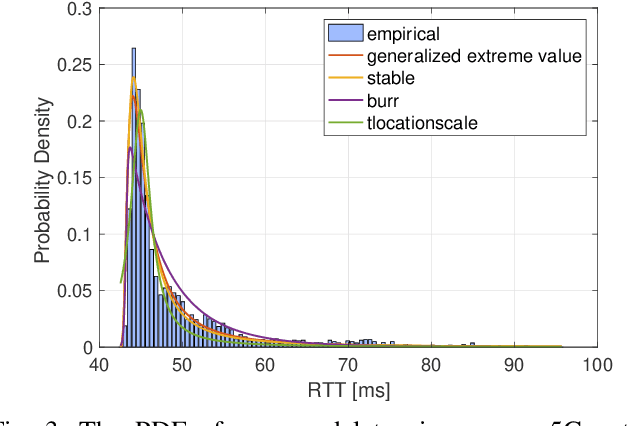
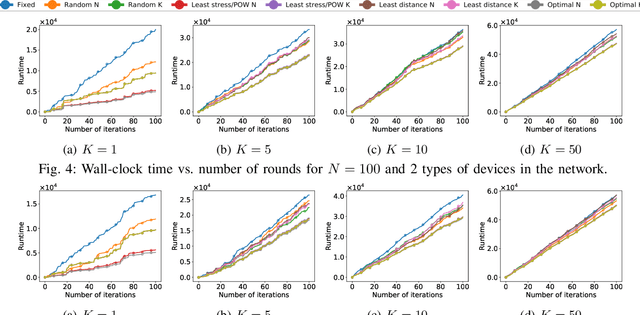
Edge computing has revolutionized the world of mobile and wireless networks world thanks to its flexible, secure, and performing characteristics. Lately, we have witnessed the increasing use of it to make more performing the deployment of machine learning (ML) techniques such as federated learning (FL). FL was debuted to improve communication efficiency compared to conventional distributed machine learning (ML). The original FL assumes a central aggregation server to aggregate locally optimized parameters and might bring reliability and latency issues. In this paper, we conduct an in-depth study of strategies to replace this central server by a flying master that is dynamically selected based on the current participants and/or available resources at every FL round of optimization. Specifically, we compare different metrics to select this flying master and assess consensus algorithms to perform the selection. Our results demonstrate a significant reduction of runtime using our flying master FL framework compared to the original FL from measurements results conducted in our EdgeAI testbed and over real 5G networks using an operational edge testbed.