 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVariational Offline Multi-agent Skill Discovery
May 26, 2024Skills are effective temporal abstractions established for sequential decision making tasks, which enable efficient hierarchical learning for long-horizon tasks and facilitate multi-task learning through their transferability. Despite extensive research, research gaps remain in multi-agent scenarios, particularly for automatically extracting subgroup coordination patterns in a multi-agent task. In this case, we propose two novel auto-encoder schemes: VO-MASD-3D and VO-MASD-Hier, to simultaneously capture subgroup- and temporal-level abstractions and form multi-agent skills, which firstly solves the aforementioned challenge. An essential algorithm component of these schemes is a dynamic grouping function that can automatically detect latent subgroups based on agent interactions in a task. Notably, our method can be applied to offline multi-task data, and the discovered subgroup skills can be transferred across relevant tasks without retraining. Empirical evaluations on StarCraft tasks indicate that our approach significantly outperforms existing methods regarding applying skills in multi-agent reinforcement learning (MARL). Moreover, skills discovered using our method can effectively reduce the learning difficulty in MARL scenarios with delayed and sparse reward signals.
Deep Generative Models for Offline Policy Learning: Tutorial, Survey, and Perspectives on Future Directions
Feb 26, 2024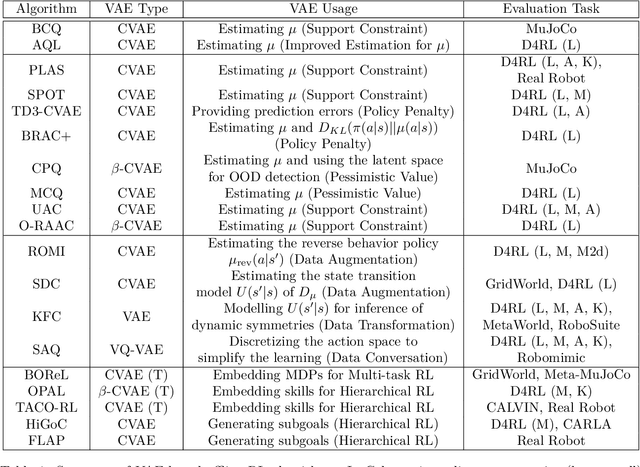
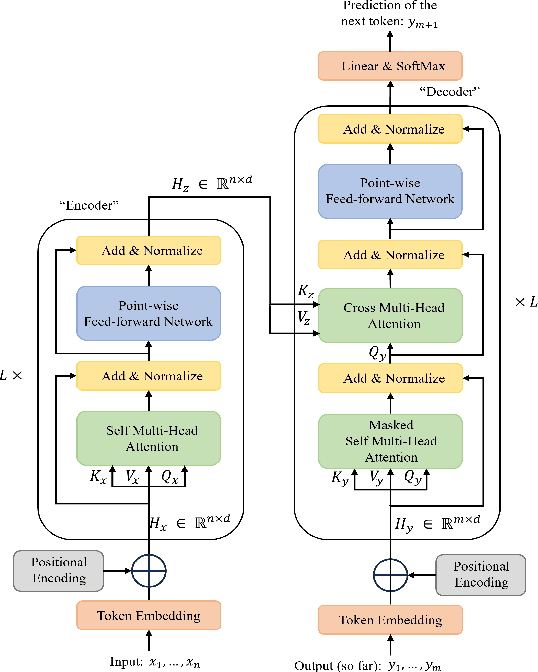
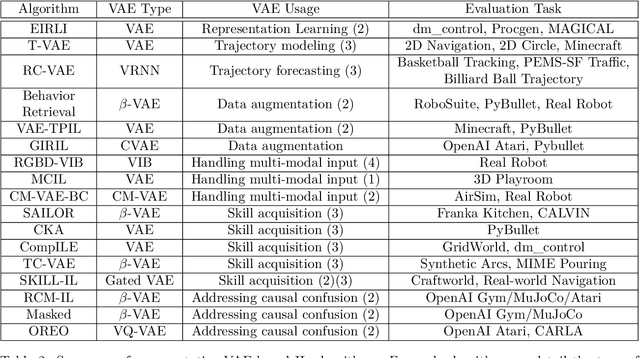
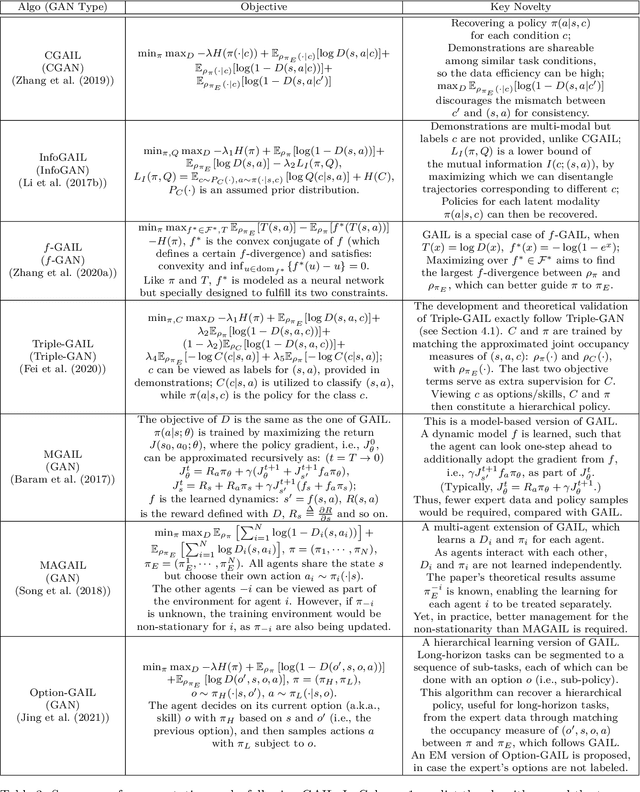
Deep generative models (DGMs) have demonstrated great success across various domains, particularly in generating texts, images, and videos using models trained from offline data. Similarly, data-driven decision-making and robotic control also necessitate learning a generator function from the offline data to serve as the strategy or policy. In this case, applying deep generative models in offline policy learning exhibits great potential, and numerous studies have explored in this direction. However, this field still lacks a comprehensive review and so developments of different branches are relatively independent. Thus, we provide the first systematic review on the applications of deep generative models for offline policy learning. In particular, we cover five mainstream deep generative models, including Variational Auto-Encoders, Generative Adversarial Networks, Normalizing Flows, Transformers, and Diffusion Models, and their applications in both offline reinforcement learning (offline RL) and imitation learning (IL). Offline RL and IL are two main branches of offline policy learning and are widely-adopted techniques for sequential decision-making. Specifically, for each type of DGM-based offline policy learning, we distill its fundamental scheme, categorize related works based on the usage of the DGM, and sort out the development process of algorithms in that field. Subsequent to the main content, we provide in-depth discussions on deep generative models and offline policy learning as a summary, based on which we present our perspectives on future research directions. This work offers a hands-on reference for the research progress in deep generative models for offline policy learning, and aims to inspire improved DGM-based offline RL or IL algorithms. For convenience, we maintain a paper list on https://github.com/LucasCJYSDL/DGMs-for-Offline-Policy-Learning.
Quantum Acceleration of Infinite Horizon Average-Reward Reinforcement Learning
Oct 18, 2023This paper investigates the potential of quantum acceleration in addressing infinite horizon Markov Decision Processes (MDPs) to enhance average reward outcomes. We introduce an innovative quantum framework for the agent's engagement with an unknown MDP, extending the conventional interaction paradigm. Our approach involves the design of an optimism-driven tabular Reinforcement Learning algorithm that harnesses quantum signals acquired by the agent through efficient quantum mean estimation techniques. Through thorough theoretical analysis, we demonstrate that the quantum advantage in mean estimation leads to exponential advancements in regret guarantees for infinite horizon Reinforcement Learning. Specifically, the proposed Quantum algorithm achieves a regret bound of $\tilde{\mathcal{O}}(1)$, a significant improvement over the $\tilde{\mathcal{O}}(\sqrt{T})$ bound exhibited by classical counterparts.
Quantum Computing Provides Exponential Regret Improvement in Episodic Reinforcement Learning
Feb 16, 2023

In this paper, we investigate the problem of \textit{episodic reinforcement learning} with quantum oracles for state evolution. To this end, we propose an \textit{Upper Confidence Bound} (UCB) based quantum algorithmic framework to facilitate learning of a finite-horizon MDP. Our quantum algorithm achieves an exponential improvement in regret as compared to the classical counterparts, achieving a regret of $\Tilde{\mathcal{O}}(1)$ as compared to $\Tilde{\mathcal{O}}(\sqrt{K})$ \footnote{$\Tilde{\mathcal{O}}(\cdot)$ hides logarithmic terms.}, $K$ being the number of training episodes. In order to achieve this advantage, we exploit efficient quantum mean estimation technique that provides quadratic improvement in the number of i.i.d. samples needed to estimate the mean of sub-Gaussian random variables as compared to classical mean estimation. This improvement is a key to the significant regret improvement in quantum reinforcement learning. We provide proof-of-concept experiments on various RL environments that in turn demonstrate performance gains of the proposed algorithmic framework.
Online Federated Learning via Non-Stationary Detection and Adaptation amidst Concept Drift
Nov 22, 2022Federated Learning (FL) is an emerging domain in the broader context of artificial intelligence research. Methodologies pertaining to FL assume distributed model training, consisting of a collection of clients and a server, with the main goal of achieving optimal global model with restrictions on data sharing due to privacy concerns. It is worth highlighting that the diverse existing literature in FL mostly assume stationary data generation processes; such an assumption is unrealistic in real-world conditions where concept drift occurs due to, for instance, seasonal or period observations, faults in sensor measurements. In this paper, we introduce a multiscale algorithmic framework which combines theoretical guarantees of \textit{FedAvg} and \textit{FedOMD} algorithms in near stationary settings with a non-stationary detection and adaptation technique to ameliorate FL generalization performance in the presence of model/concept drifts. We present a multi-scale algorithmic framework leading to $\Tilde{\mathcal{O}} ( \min \{ \sqrt{LT} , \Delta^{\frac{1}{3}}T^{\frac{2}{3}} + \sqrt{T} \})$ \textit{dynamic regret} for $T$ rounds with an underlying general convex loss function, where $L$ is the number of times non-stationary drifts occured and $\Delta$ is the cumulative magnitude of drift experienced within $T$ rounds.
Multi-Edge Server-Assisted Dynamic Federated Learning with an Optimized Floating Aggregation Point
Mar 26, 2022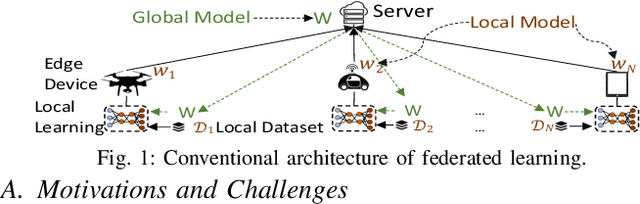
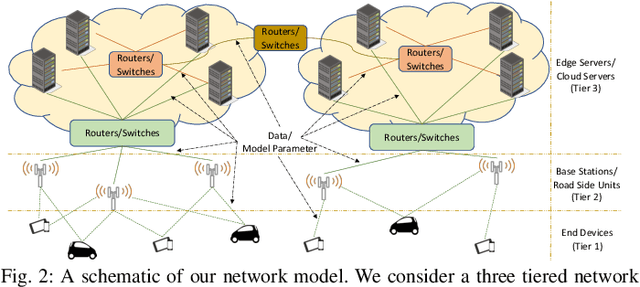
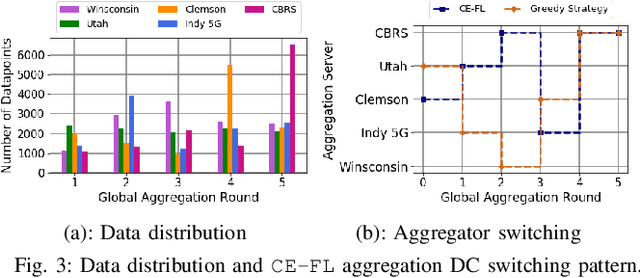
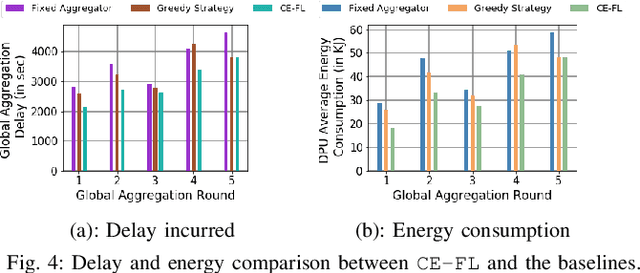
We propose cooperative edge-assisted dynamic federated learning (CE-FL). CE-FL introduces a distributed machine learning (ML) architecture, where data collection is carried out at the end devices, while the model training is conducted cooperatively at the end devices and the edge servers, enabled via data offloading from the end devices to the edge servers through base stations. CE-FL also introduces floating aggregation point, where the local models generated at the devices and the servers are aggregated at an edge server, which varies from one model training round to another to cope with the network evolution in terms of data distribution and users' mobility. CE-FL considers the heterogeneity of network elements in terms of communication/computation models and the proximity to one another. CE-FL further presumes a dynamic environment with online variation of data at the network devices which causes a drift at the ML model performance. We model the processes taken during CE-FL, and conduct analytical convergence analysis of its ML model training. We then formulate network-aware CE-FL which aims to adaptively optimize all the network elements via tuning their contribution to the learning process, which turns out to be a non-convex mixed integer problem. Motivated by the large scale of the system, we propose a distributed optimization solver to break down the computation of the solution across the network elements. We finally demonstrate the effectiveness of our framework with the data collected from a real-world testbed.
Convergence Rates of Average-Reward Multi-agent Reinforcement Learning via Randomized Linear Programming
Oct 22, 2021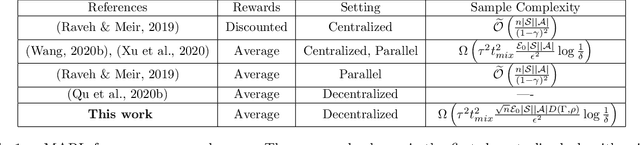
In tabular multi-agent reinforcement learning with average-cost criterion, a team of agents sequentially interacts with the environment and observes local incentives. We focus on the case that the global reward is a sum of local rewards, the joint policy factorizes into agents' marginals, and full state observability. To date, few global optimality guarantees exist even for this simple setting, as most results yield convergence to stationarity for parameterized policies in large/possibly continuous spaces. To solidify the foundations of MARL, we build upon linear programming (LP) reformulations, for which stochastic primal-dual methods yields a model-free approach to achieve \emph{optimal sample complexity} in the centralized case. We develop multi-agent extensions, whereby agents solve their local saddle point problems and then perform local weighted averaging. We establish that the sample complexity to obtain near-globally optimal solutions matches tight dependencies on the cardinality of the state and action spaces, and exhibits classical scalings with respect to the network in accordance with multi-agent optimization. Experiments corroborate these results in practice.
Communication Efficient Parallel Reinforcement Learning
Feb 22, 2021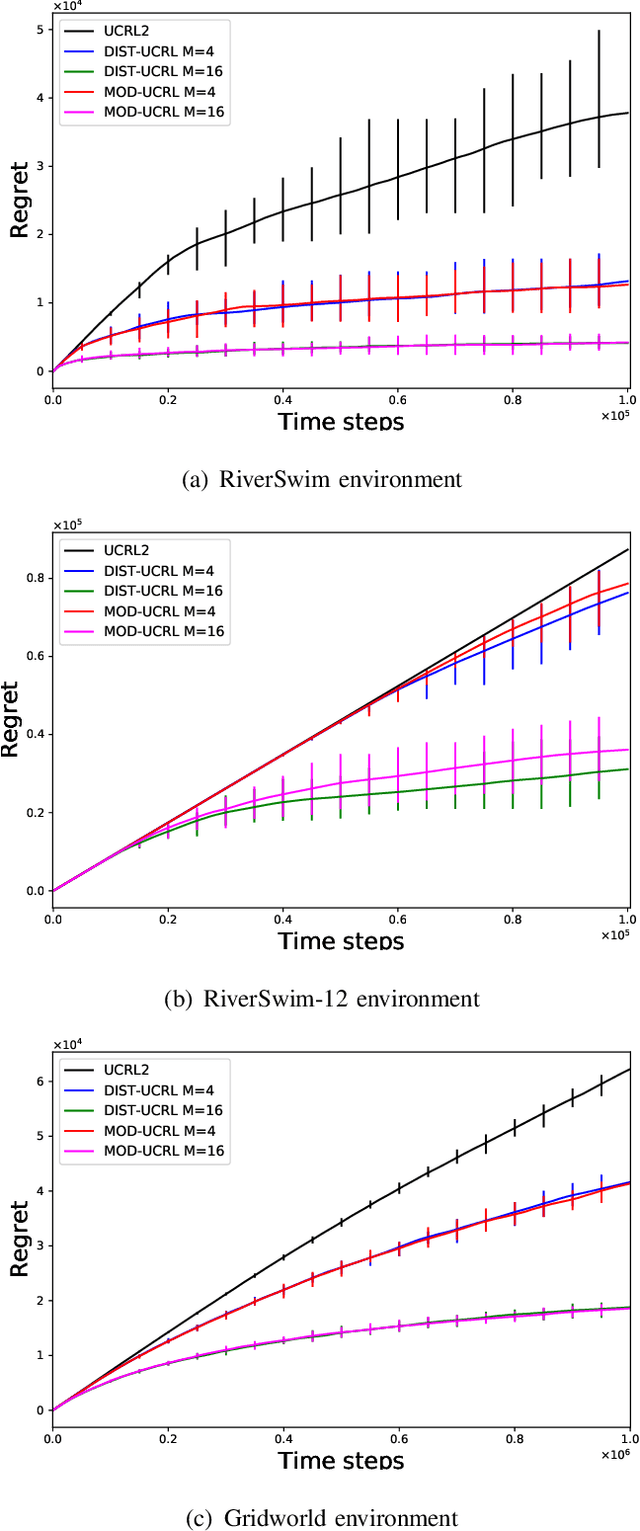
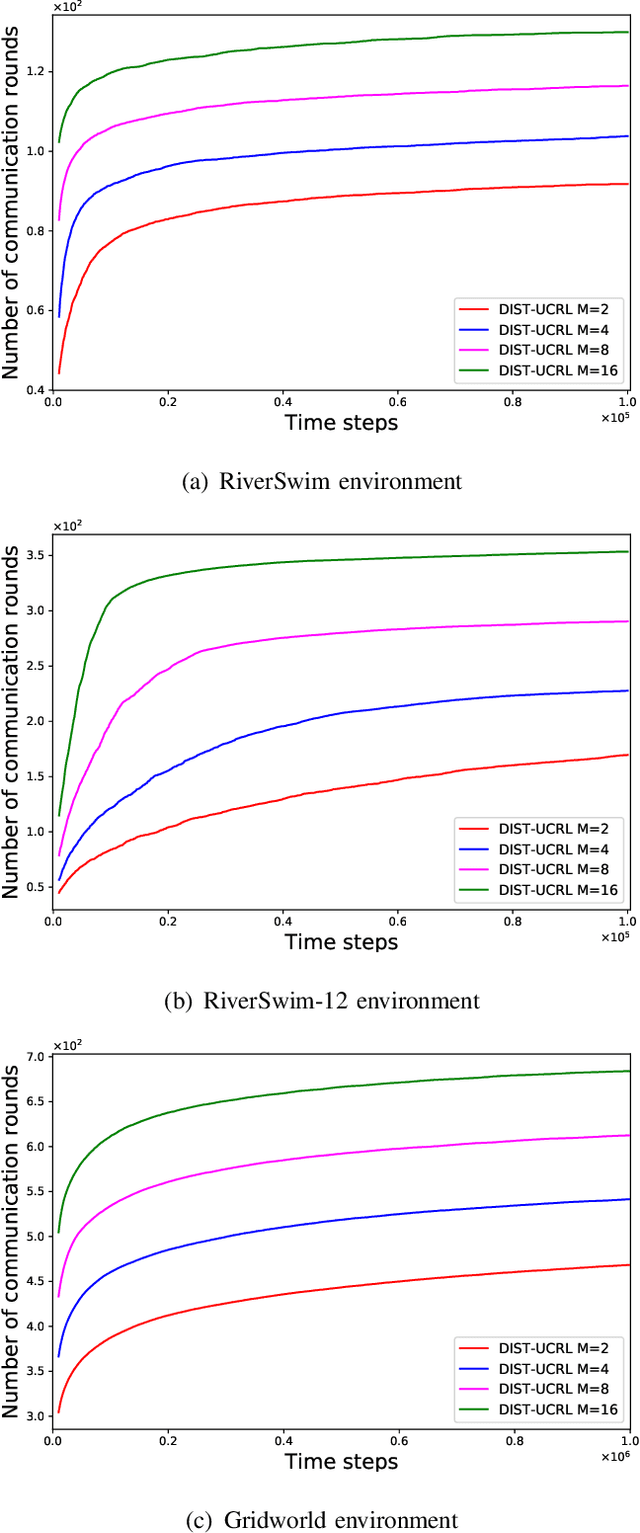
We consider the problem where $M$ agents interact with $M$ identical and independent environments with $S$ states and $A$ actions using reinforcement learning for $T$ rounds. The agents share their data with a central server to minimize their regret. We aim to find an algorithm that allows the agents to minimize the regret with infrequent communication rounds. We provide \NAM\ which runs at each agent and prove that the total cumulative regret of $M$ agents is upper bounded as $\Tilde{O}(DS\sqrt{MAT})$ for a Markov Decision Process with diameter $D$, number of states $S$, and number of actions $A$. The agents synchronize after their visitations to any state-action pair exceeds a certain threshold. Using this, we obtain a bound of $O\left(MSA\log(MT)\right)$ on the total number of communications rounds. Finally, we evaluate the algorithm against multiple environments and demonstrate that the proposed algorithm performs at par with an always communication version of the UCRL2 algorithm, while with significantly lower communication.