 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCommunication Efficient Parallel Reinforcement Learning
Paper and Code
Feb 22, 2021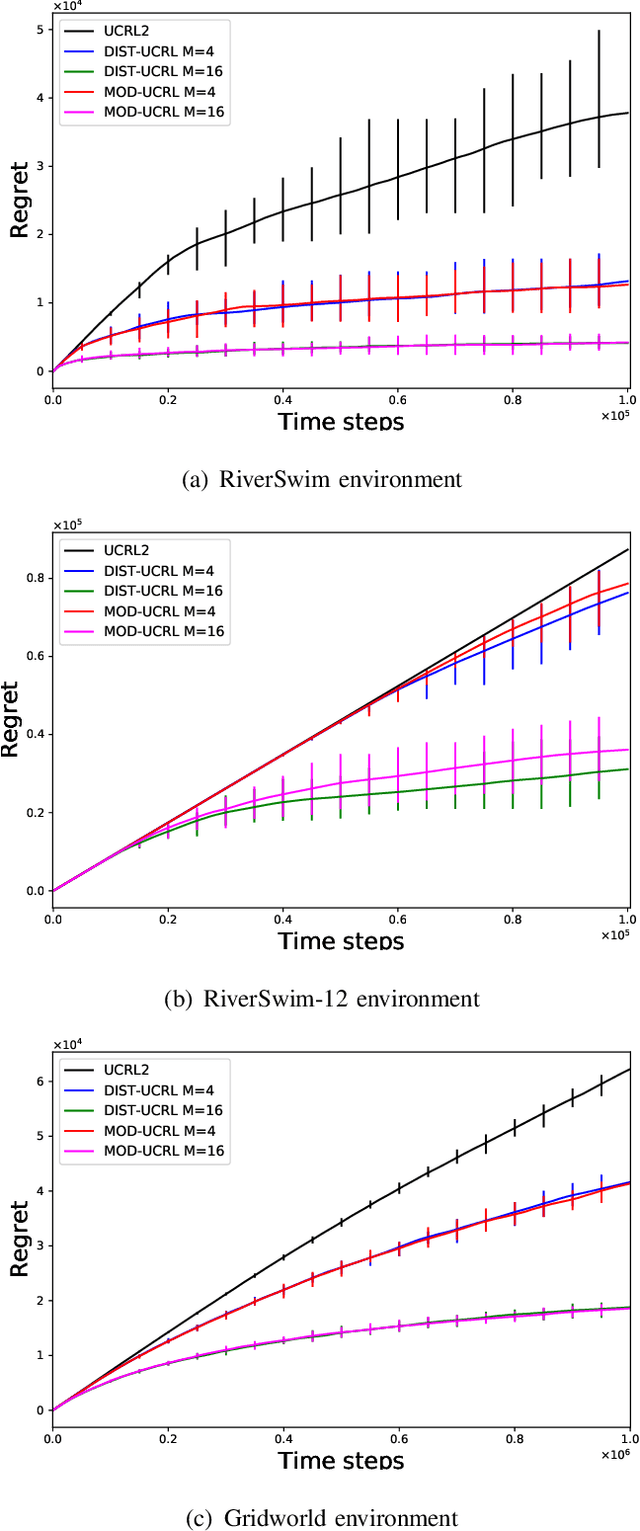
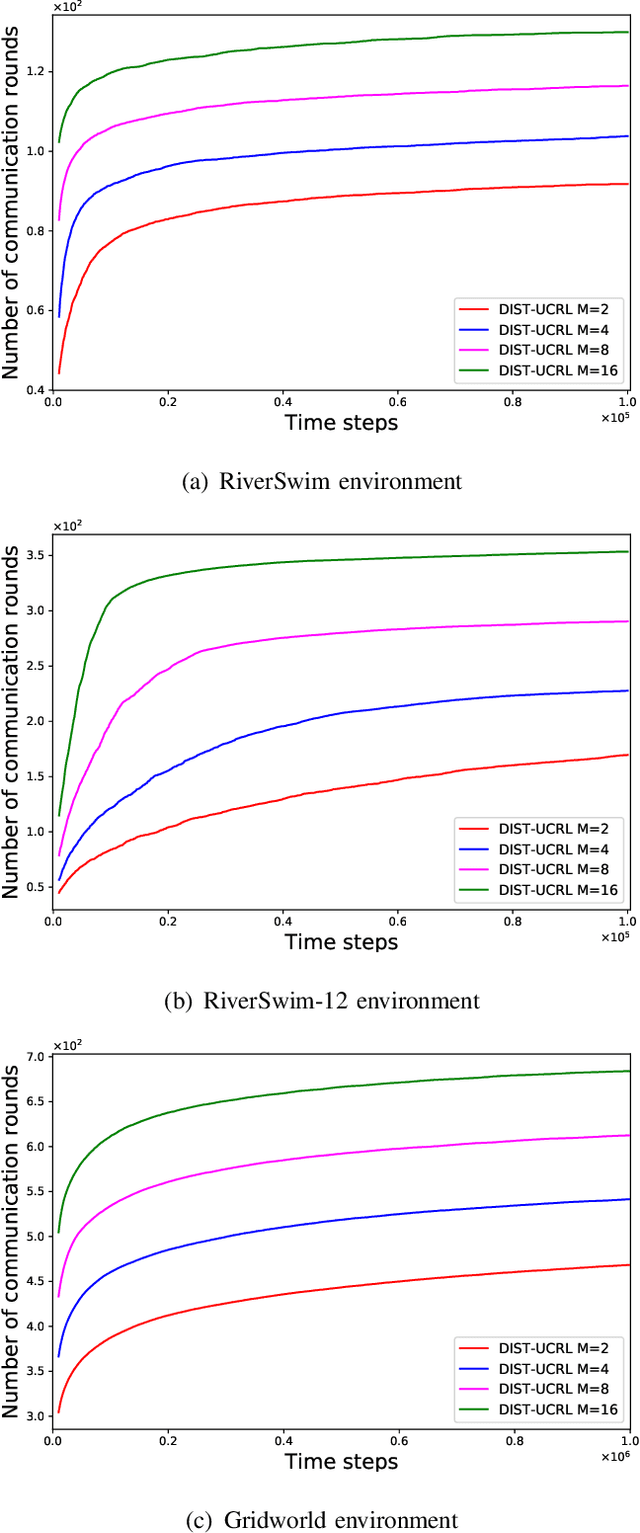
We consider the problem where $M$ agents interact with $M$ identical and independent environments with $S$ states and $A$ actions using reinforcement learning for $T$ rounds. The agents share their data with a central server to minimize their regret. We aim to find an algorithm that allows the agents to minimize the regret with infrequent communication rounds. We provide \NAM\ which runs at each agent and prove that the total cumulative regret of $M$ agents is upper bounded as $\Tilde{O}(DS\sqrt{MAT})$ for a Markov Decision Process with diameter $D$, number of states $S$, and number of actions $A$. The agents synchronize after their visitations to any state-action pair exceeds a certain threshold. Using this, we obtain a bound of $O\left(MSA\log(MT)\right)$ on the total number of communications rounds. Finally, we evaluate the algorithm against multiple environments and demonstrate that the proposed algorithm performs at par with an always communication version of the UCRL2 algorithm, while with significantly lower communication.