 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo One Size Fits All: QueryBandits for Hallucination Mitigation
Feb 23, 2026Advanced reasoning capabilities in Large Language Models (LLMs) have led to more frequent hallucinations; yet most mitigation work focuses on open-source models for post-hoc detection and parameter editing. The dearth of studies focusing on hallucinations in closed-source models is especially concerning, as they constitute the vast majority of models in institutional deployments. We introduce QueryBandits, a model-agnostic contextual bandit framework that adaptively learns online to select the optimal query-rewrite strategy by leveraging an empirically validated and calibrated reward function. Across 16 QA scenarios, our top QueryBandit (Thompson Sampling) achieves an 87.5% win rate over a No-Rewrite baseline and outperforms zero-shot static policies (e.g., Paraphrase or Expand) by 42.6% and 60.3%, respectively. Moreover, all contextual bandits outperform vanilla bandits across all datasets, with higher feature variance coinciding with greater variance in arm selection. This substantiates our finding that there is no single rewrite policy optimal for all queries. We also discover that certain static policies incur higher cumulative regret than No-Rewrite, indicating that an inflexible query-rewriting policy can worsen hallucinations. Thus, learning an online policy over semantic features with QueryBandits can shift model behavior purely through forward-pass mechanisms, enabling its use with closed-source models and bypassing the need for retraining or gradient-based adaptation.
A Regularized Actor-Critic Algorithm for Bi-Level Reinforcement Learning
Jan 26, 2026We study a structured bi-level optimization problem where the upper-level objective is a smooth function and the lower-level problem is policy optimization in a Markov decision process (MDP). The upper-level decision variable parameterizes the reward of the lower-level MDP, and the upper-level objective depends on the optimal induced policy. Existing methods for bi-level optimization and RL often require second-order information, impose strong regularization at the lower level, or inefficiently use samples through nested-loop procedures. In this work, we propose a single-loop, first-order actor-critic algorithm that optimizes the bi-level objective via a penalty-based reformulation. We introduce into the lower-level RL objective an attenuating entropy regularization, which enables asymptotically unbiased upper-level hyper-gradient estimation without solving the unregularized RL problem exactly. We establish the finite-time and finite-sample convergence of the proposed algorithm to a stationary point of the original, unregularized bi-level optimization problem through a novel lower-level residual analysis under a special type of Polyak-Lojasiewicz condition. We validate the performance of our method through experiments on a GridWorld goal position problem and on happy tweet generation through reinforcement learning from human feedback (RLHF).
Learning in Stackelberg Mean Field Games: A Non-Asymptotic Analysis
Sep 18, 2025We study policy optimization in Stackelberg mean field games (MFGs), a hierarchical framework for modeling the strategic interaction between a single leader and an infinitely large population of homogeneous followers. The objective can be formulated as a structured bi-level optimization problem, in which the leader needs to learn a policy maximizing its reward, anticipating the response of the followers. Existing methods for solving these (and related) problems often rely on restrictive independence assumptions between the leader's and followers' objectives, use samples inefficiently due to nested-loop algorithm structure, and lack finite-time convergence guarantees. To address these limitations, we propose AC-SMFG, a single-loop actor-critic algorithm that operates on continuously generated Markovian samples. The algorithm alternates between (semi-)gradient updates for the leader, a representative follower, and the mean field, and is simple to implement in practice. We establish the finite-time and finite-sample convergence of the algorithm to a stationary point of the Stackelberg objective. To our knowledge, this is the first Stackelberg MFG algorithm with non-asymptotic convergence guarantees. Our key assumption is a "gradient alignment" condition, which requires that the full policy gradient of the leader can be approximated by a partial component of it, relaxing the existing leader-follower independence assumption. Simulation results in a range of well-established economics environments demonstrate that AC-SMFG outperforms existing multi-agent and MFG learning baselines in policy quality and convergence speed.
Collab: Controlled Decoding using Mixture of Agents for LLM Alignment
Mar 27, 2025Alignment of Large Language models (LLMs) is crucial for safe and trustworthy deployment in applications. Reinforcement learning from human feedback (RLHF) has emerged as an effective technique to align LLMs to human preferences and broader utilities, but it requires updating billions of model parameters, which is computationally expensive. Controlled Decoding, by contrast, provides a mechanism for aligning a model at inference time without retraining. However, single-agent decoding approaches often struggle to adapt to diverse tasks due to the complexity and variability inherent in these tasks. To strengthen the test-time performance w.r.t the target task, we propose a mixture of agent-based decoding strategies leveraging the existing off-the-shelf aligned LLM policies. Treating each prior policy as an agent in the spirit of mixture of agent collaboration, we develop a decoding method that allows for inference-time alignment through a token-level selection strategy among multiple agents. For each token, the most suitable LLM is dynamically chosen from a pool of models based on a long-term utility metric. This policy-switching mechanism ensures optimal model selection at each step, enabling efficient collaboration and alignment among LLMs during decoding. Theoretical analysis of our proposed algorithm establishes optimal performance with respect to the target task represented via a target reward for the given off-the-shelf models. We conduct comprehensive empirical evaluations with open-source aligned models on diverse tasks and preferences, which demonstrates the merits of this approach over single-agent decoding baselines. Notably, Collab surpasses the current SoTA decoding strategy, achieving an improvement of up to 1.56x in average reward and 71.89% in GPT-4 based win-tie rate.
Efficient Inverse Multiagent Learning
Feb 20, 2025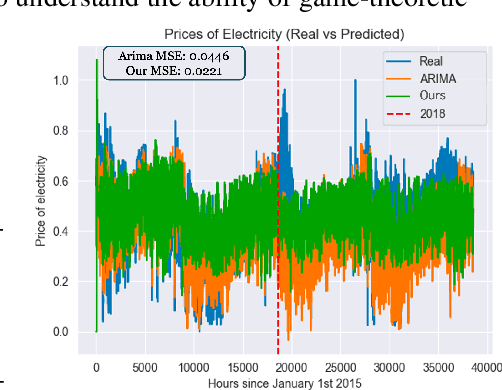

In this paper, we study inverse game theory (resp. inverse multiagent learning) in which the goal is to find parameters of a game's payoff functions for which the expected (resp. sampled) behavior is an equilibrium. We formulate these problems as generative-adversarial (i.e., min-max) optimization problems, for which we develop polynomial-time algorithms to solve, the former of which relies on an exact first-order oracle, and the latter, a stochastic one. We extend our approach to solve inverse multiagent simulacral learning in polynomial time and number of samples. In these problems, we seek a simulacrum, meaning parameters and an associated equilibrium that replicate the given observations in expectation. We find that our approach outperforms the widely-used ARIMA method in predicting prices in Spanish electricity markets based on time-series data.
Nonparametric Sparse Online Learning of the Koopman Operator
Jan 27, 2025The Koopman operator provides a powerful framework for representing the dynamics of general nonlinear dynamical systems. Data-driven techniques to learn the Koopman operator typically assume that the chosen function space is closed under system dynamics. In this paper, we study the Koopman operator via its action on the reproducing kernel Hilbert space (RKHS), and explore the mis-specified scenario where the dynamics may escape the chosen function space. We relate the Koopman operator to the conditional mean embeddings (CME) operator and then present an operator stochastic approximation algorithm to learn the Koopman operator iteratively with control over the complexity of the representation. We provide both asymptotic and finite-time last-iterate guarantees of the online sparse learning algorithm with trajectory-based sampling with an analysis that is substantially more involved than that for finite-dimensional stochastic approximation. Numerical examples confirm the effectiveness of the proposed algorithm.
Regularized Proportional Fairness Mechanism for Resource Allocation Without Money
Jan 02, 2025



Mechanism design in resource allocation studies dividing limited resources among self-interested agents whose satisfaction with the allocation depends on privately held utilities. We consider the problem in a payment-free setting, with the aim of maximizing social welfare while enforcing incentive compatibility (IC), i.e., agents cannot inflate allocations by misreporting their utilities. The well-known proportional fairness (PF) mechanism achieves the maximum possible social welfare but incurs an undesirably high exploitability (the maximum unilateral inflation in utility from misreport and a measure of deviation from IC). In fact, it is known that no mechanism can achieve the maximum social welfare and exact incentive compatibility (IC) simultaneously without the use of monetary incentives (Cole et al., 2013). Motivated by this fact, we propose learning an approximate mechanism that desirably trades off the competing objectives. Our main contribution is to design an innovative neural network architecture tailored to the resource allocation problem, which we name Regularized Proportional Fairness Network (RPF-Net). RPF-Net regularizes the output of the PF mechanism by a learned function approximator of the most exploitable allocation, with the aim of reducing the incentive for any agent to misreport. We derive generalization bounds that guarantee the mechanism performance when trained under finite and out-of-distribution samples and experimentally demonstrate the merits of the proposed mechanism compared to the state-of-the-art.
Approximate Equivariance in Reinforcement Learning
Nov 06, 2024Equivariant neural networks have shown great success in reinforcement learning, improving sample efficiency and generalization when there is symmetry in the task. However, in many problems, only approximate symmetry is present, which makes imposing exact symmetry inappropriate. Recently, approximately equivariant networks have been proposed for supervised classification and modeling physical systems. In this work, we develop approximately equivariant algorithms in reinforcement learning (RL). We define approximately equivariant MDPs and theoretically characterize the effect of approximate equivariance on the optimal Q function. We propose novel RL architectures using relaxed group convolutions and experiment on several continuous control domains and stock trading with real financial data. Our results demonstrate that approximate equivariance matches prior work when exact symmetries are present, and outperforms them when domains exhibit approximate symmetry. As an added byproduct of these techniques, we observe increased robustness to noise at test time.
GenARM: Reward Guided Generation with Autoregressive Reward Model for Test-time Alignment
Oct 10, 2024



Large Language Models (LLMs) exhibit impressive capabilities but require careful alignment with human preferences. Traditional training-time methods finetune LLMs using human preference datasets but incur significant training costs and require repeated training to handle diverse user preferences. Test-time alignment methods address this by using reward models (RMs) to guide frozen LLMs without retraining. However, existing test-time approaches rely on trajectory-level RMs which are designed to evaluate complete responses, making them unsuitable for autoregressive text generation that requires computing next-token rewards from partial responses. To address this, we introduce GenARM, a test-time alignment approach that leverages the Autoregressive Reward Model--a novel reward parametrization designed to predict next-token rewards for efficient and effective autoregressive generation. Theoretically, we demonstrate that this parametrization can provably guide frozen LLMs toward any distribution achievable by traditional RMs within the KL-regularized reinforcement learning framework. Experimental results show that GenARM significantly outperforms prior test-time alignment baselines and matches the performance of training-time methods. Additionally, GenARM enables efficient weak-to-strong guidance, aligning larger LLMs with smaller RMs without the high costs of training larger models. Furthermore, GenARM supports multi-objective alignment, allowing real-time trade-offs between preference dimensions and catering to diverse user preferences without retraining.
Partially Observable Contextual Bandits with Linear Payoffs
Sep 17, 2024The standard contextual bandit framework assumes fully observable and actionable contexts. In this work, we consider a new bandit setting with partially observable, correlated contexts and linear payoffs, motivated by the applications in finance where decision making is based on market information that typically displays temporal correlation and is not fully observed. We make the following contributions marrying ideas from statistical signal processing with bandits: (i) We propose an algorithmic pipeline named EMKF-Bandit, which integrates system identification, filtering, and classic contextual bandit algorithms into an iterative method alternating between latent parameter estimation and decision making. (ii) We analyze EMKF-Bandit when we select Thompson sampling as the bandit algorithm and show that it incurs a sub-linear regret under conditions on filtering. (iii) We conduct numerical simulations that demonstrate the benefits and practical applicability of the proposed pipeline.