 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNonparametric Sparse Online Learning of the Koopman Operator
Jan 27, 2025The Koopman operator provides a powerful framework for representing the dynamics of general nonlinear dynamical systems. Data-driven techniques to learn the Koopman operator typically assume that the chosen function space is closed under system dynamics. In this paper, we study the Koopman operator via its action on the reproducing kernel Hilbert space (RKHS), and explore the mis-specified scenario where the dynamics may escape the chosen function space. We relate the Koopman operator to the conditional mean embeddings (CME) operator and then present an operator stochastic approximation algorithm to learn the Koopman operator iteratively with control over the complexity of the representation. We provide both asymptotic and finite-time last-iterate guarantees of the online sparse learning algorithm with trajectory-based sampling with an analysis that is substantially more involved than that for finite-dimensional stochastic approximation. Numerical examples confirm the effectiveness of the proposed algorithm.
Markov Balance Satisfaction Improves Performance in Strictly Batch Offline Imitation Learning
Aug 17, 2024



Imitation learning (IL) is notably effective for robotic tasks where directly programming behaviors or defining optimal control costs is challenging. In this work, we address a scenario where the imitator relies solely on observed behavior and cannot make environmental interactions during learning. It does not have additional supplementary datasets beyond the expert's dataset nor any information about the transition dynamics. Unlike state-of-the-art (SOTA) IL methods, this approach tackles the limitations of conventional IL by operating in a more constrained and realistic setting. Our method uses the Markov balance equation and introduces a novel conditional density estimation-based imitation learning framework. It employs conditional normalizing flows for transition dynamics estimation and aims at satisfying a balance equation for the environment. Through a series of numerical experiments on Classic Control and MuJoCo environments, we demonstrate consistently superior empirical performance compared to many SOTA IL algorithms.
Conditional Kernel Imitation Learning for Continuous State Environments
Aug 24, 2023

Imitation Learning (IL) is an important paradigm within the broader reinforcement learning (RL) methodology. Unlike most of RL, it does not assume availability of reward-feedback. Reward inference and shaping are known to be difficult and error-prone methods particularly when the demonstration data comes from human experts. Classical methods such as behavioral cloning and inverse reinforcement learning are highly sensitive to estimation errors, a problem that is particularly acute in continuous state space problems. Meanwhile, state-of-the-art IL algorithms convert behavioral policy learning problems into distribution-matching problems which often require additional online interaction data to be effective. In this paper, we consider the problem of imitation learning in continuous state space environments based solely on observed behavior, without access to transition dynamics information, reward structure, or, most importantly, any additional interactions with the environment. Our approach is based on the Markov balance equation and introduces a novel conditional kernel density estimation-based imitation learning framework. It involves estimating the environment's transition dynamics using conditional kernel density estimators and seeks to satisfy the probabilistic balance equations for the environment. We establish that our estimators satisfy basic asymptotic consistency requirements. Through a series of numerical experiments on continuous state benchmark environments, we show consistently superior empirical performance over many state-of-the-art IL algorithms.
Exact and Cost-Effective Automated Transformation of Neural Network Controllers to Decision Tree Controllers
Apr 11, 2023Over the past decade, neural network (NN)-based controllers have demonstrated remarkable efficacy in a variety of decision-making tasks. However, their black-box nature and the risk of unexpected behaviors and surprising results pose a challenge to their deployment in real-world systems with strong guarantees of correctness and safety. We address these limitations by investigating the transformation of NN-based controllers into equivalent soft decision tree (SDT)-based controllers and its impact on verifiability. Differently from previous approaches, we focus on discrete-output NN controllers including rectified linear unit (ReLU) activation functions as well as argmax operations. We then devise an exact but cost-effective transformation algorithm, in that it can automatically prune redundant branches. We evaluate our approach using two benchmarks from the OpenAI Gym environment. Our results indicate that the SDT transformation can benefit formal verification, showing runtime improvements of up to 21x and 2x for MountainCar-v0 and CartPole-v0, respectively.
Designing Interpretable Approximations to Deep Reinforcement Learning with Soft Decision Trees
Oct 28, 2020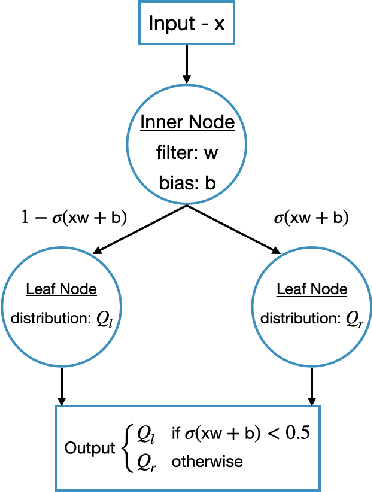
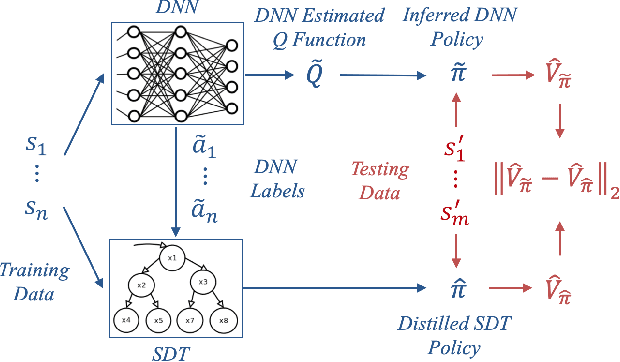
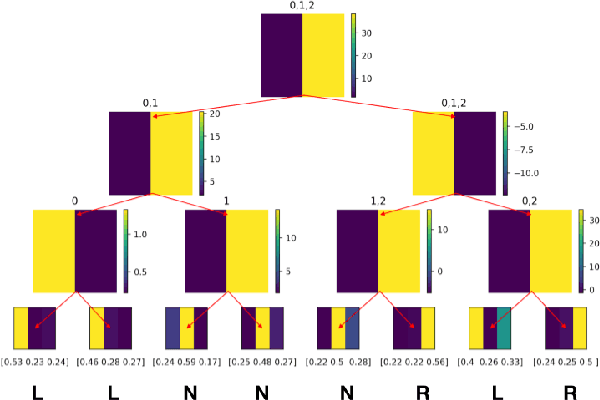
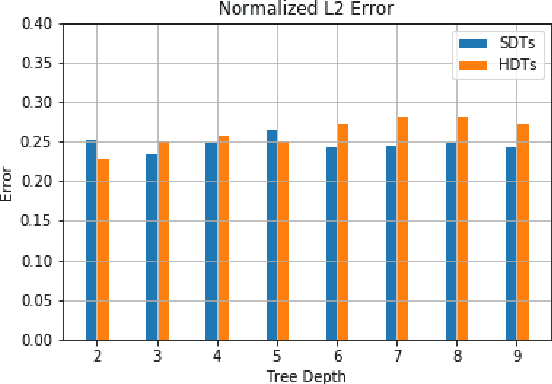
In an ever expanding set of research and application areas, deep neural networks (DNNs) set the bar for algorithm performance. However, depending upon additional constraints such as processing power and execution time limits, or requirements such as verifiable safety guarantees, it may not be feasible to actually use such high-performing DNNs in practice. Many techniques have been developed in recent years to compress or distill complex DNNs into smaller, faster or more understandable models and controllers. This work seeks to provide a quantitative framework with metrics to systematically evaluate the outcome of such conversion processes, and identify reduced models that not only preserve a desired performance level, but also, for example, succinctly explain the latent knowledge represented by a DNN. We illustrate the effectiveness of the proposed approach on the evaluation of decision tree variants in the context of benchmark reinforcement learning tasks.