 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning from Rich Feedback with Distributional DAgger
Jun 03, 2026Reasoning models have advanced rapidly, but the dominant reinforcement learning from verifiable rewards (RLVR) recipe remains surprisingly narrow: sample many responses and reward each with a single bit indicating whether the final answer is correct. Yet many settings provide rich feedback, including execution traces, tool outputs, expert corrections, and model self-evaluations. We study how to use such feedback through a distributional variant of the classic imitation learning algorithm DAgger, where the learner has local access to an expert distribution on states visited by the current policy. This yields a simple forward cross-entropy objective that admits a blackbox expert and whose sequence-level gradient {conduct rich credit assignment by propagating} future expert-student disagreement back to earlier decisions. We show that prior RL with self-distillation objectives based on reverse KL or Jensen-Shannon fail to guarantee monotonic policy improvement: even when the expert has higher reward, their updates may increase probability on worse actions. In contrast, we show that forward cross-entropy admits monotonic policy improvement and enjoys guarantees on regret. We further show that our objective optimizes a lower bound on teacher-weighted likelihood of success, leading to improved Pass@N. Empirically, our approach, DistIL, improves over RLVR and RL with self-distillation baselines across a variety of domains: scientific reasoning, coding, and solving hard mathematical problems.
Balance Equation-based Distributionally Robust Offline Imitation Learning
Nov 11, 2025Imitation Learning (IL) has proven highly effective for robotic and control tasks where manually designing reward functions or explicit controllers is infeasible. However, standard IL methods implicitly assume that the environment dynamics remain fixed between training and deployment. In practice, this assumption rarely holds where modeling inaccuracies, real-world parameter variations, and adversarial perturbations can all induce shifts in transition dynamics, leading to severe performance degradation. We address this challenge through Balance Equation-based Distributionally Robust Offline Imitation Learning, a framework that learns robust policies solely from expert demonstrations collected under nominal dynamics, without requiring further environment interaction. We formulate the problem as a distributionally robust optimization over an uncertainty set of transition models, seeking a policy that minimizes the imitation loss under the worst-case transition distribution. Importantly, we show that this robust objective can be reformulated entirely in terms of the nominal data distribution, enabling tractable offline learning. Empirical evaluations on continuous-control benchmarks demonstrate that our approach achieves superior robustness and generalization compared to state-of-the-art offline IL baselines, particularly under perturbed or shifted environments.
Enhancing Cache-Augmented Generation (CAG) with Adaptive Contextual Compression for Scalable Knowledge Integration
May 13, 2025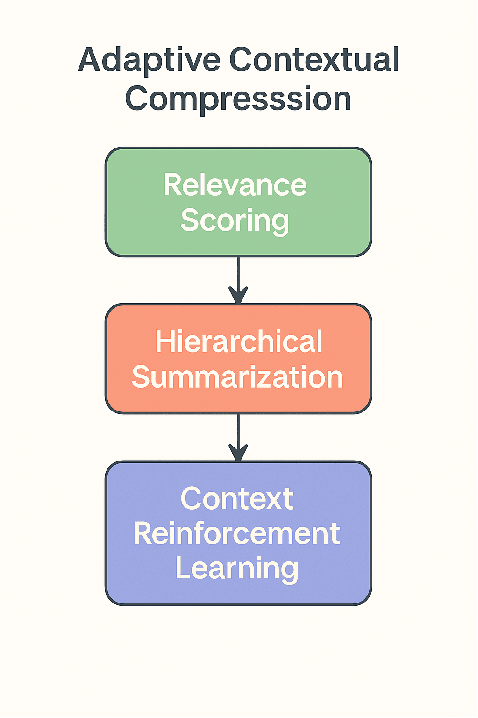

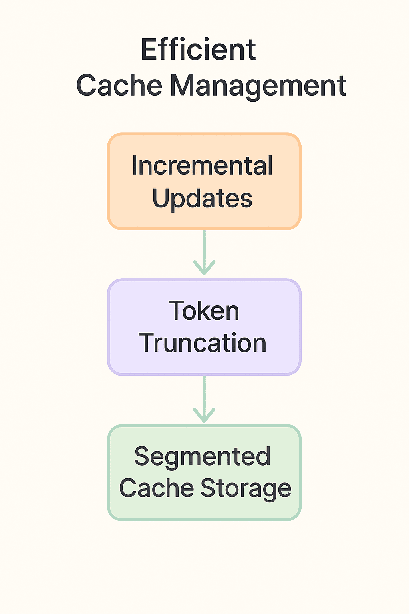

The rapid progress in large language models (LLMs) has paved the way for novel approaches in knowledge-intensive tasks. Among these, Cache-Augmented Generation (CAG) has emerged as a promising alternative to Retrieval-Augmented Generation (RAG). CAG minimizes retrieval latency and simplifies system design by preloading knowledge into the model's context. However, challenges persist in scaling CAG to accommodate large and dynamic knowledge bases effectively. This paper introduces Adaptive Contextual Compression (ACC), an innovative technique designed to dynamically compress and manage context inputs, enabling efficient utilization of the extended memory capabilities of modern LLMs. To further address the limitations of standalone CAG, we propose a Hybrid CAG-RAG Framework, which integrates selective retrieval to augment preloaded contexts in scenarios requiring additional information. Comprehensive evaluations on diverse datasets highlight the proposed methods' ability to enhance scalability, optimize efficiency, and improve multi-hop reasoning performance, offering practical solutions for real-world knowledge integration challenges.
Markov Balance Satisfaction Improves Performance in Strictly Batch Offline Imitation Learning
Aug 17, 2024



Imitation learning (IL) is notably effective for robotic tasks where directly programming behaviors or defining optimal control costs is challenging. In this work, we address a scenario where the imitator relies solely on observed behavior and cannot make environmental interactions during learning. It does not have additional supplementary datasets beyond the expert's dataset nor any information about the transition dynamics. Unlike state-of-the-art (SOTA) IL methods, this approach tackles the limitations of conventional IL by operating in a more constrained and realistic setting. Our method uses the Markov balance equation and introduces a novel conditional density estimation-based imitation learning framework. It employs conditional normalizing flows for transition dynamics estimation and aims at satisfying a balance equation for the environment. Through a series of numerical experiments on Classic Control and MuJoCo environments, we demonstrate consistently superior empirical performance compared to many SOTA IL algorithms.
Conditional Kernel Imitation Learning for Continuous State Environments
Aug 24, 2023

Imitation Learning (IL) is an important paradigm within the broader reinforcement learning (RL) methodology. Unlike most of RL, it does not assume availability of reward-feedback. Reward inference and shaping are known to be difficult and error-prone methods particularly when the demonstration data comes from human experts. Classical methods such as behavioral cloning and inverse reinforcement learning are highly sensitive to estimation errors, a problem that is particularly acute in continuous state space problems. Meanwhile, state-of-the-art IL algorithms convert behavioral policy learning problems into distribution-matching problems which often require additional online interaction data to be effective. In this paper, we consider the problem of imitation learning in continuous state space environments based solely on observed behavior, without access to transition dynamics information, reward structure, or, most importantly, any additional interactions with the environment. Our approach is based on the Markov balance equation and introduces a novel conditional kernel density estimation-based imitation learning framework. It involves estimating the environment's transition dynamics using conditional kernel density estimators and seeks to satisfy the probabilistic balance equations for the environment. We establish that our estimators satisfy basic asymptotic consistency requirements. Through a series of numerical experiments on continuous state benchmark environments, we show consistently superior empirical performance over many state-of-the-art IL algorithms.
Socially Intelligent Genetic Agents for the Emergence of Explicit Norms
Aug 07, 2022
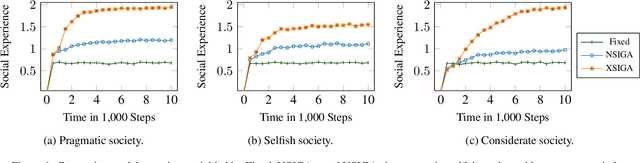
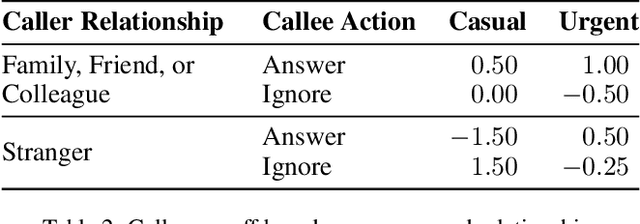

Norms help regulate a society. Norms may be explicit (represented in structured form) or implicit. We address the emergence of explicit norms by developing agents who provide and reason about explanations for norm violations in deciding sanctions and identifying alternative norms. These agents use a genetic algorithm to produce norms and reinforcement learning to learn the values of these norms. We find that applying explanations leads to norms that provide better cohesion and goal satisfaction for the agents. Our results are stable for societies with differing attitudes of generosity.