 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBayesian Learning in Episodic Zero-Sum Games
Mar 21, 2026We study Bayesian learning in episodic, finite-horizon zero-sum Markov games with unknown transition and reward models. We investigate a posterior algorithm in which each player maintains a Bayesian posterior over the game model, independently samples a game model at the beginning of each episode, and computes an equilibrium policy for the sampled model. We analyze two settings: (i) Both players use the posterior sampling algorithm, and (ii) Only one player uses posterior sampling while the opponent follows an arbitrary learning algorithm. In each setting, we provide guarantees on the expected regret of the posterior sampling agent. Our notion of regret compares the expected total reward of the learning agent against the expected total reward under equilibrium policies of the true game. Our main theoretical result is an expected regret bound for the posterior sampling agent of order $O(HS\sqrt{ABHK\log(SABHK)})$ where $K$ is the number of episodes, $H$ is the episode length, $S$ is the number of states, and $A,B$ are the action space sizes of the two players. Experiments in a grid-world predator--prey domain illustrate the sublinear regret scaling and show that posterior sampling competes favorably with a fictitious-play baseline.
Sub-optimality bounds for certainty equivalent policies in partially observed systems
Feb 02, 2026In this paper, we present a generalization of the certainty equivalence principle of stochastic control. One interpretation of the classical certainty equivalence principle for linear systems with output feedback and quadratic costs is as follows: the optimal action at each time is obtained by evaluating the optimal state-feedback policy of the stochastic linear system at the minimum mean square error (MMSE) estimate of the state. Motivated by this interpretation, we consider certainty equivalent policies for general (non-linear) partially observed stochastic systems that allow for any state estimate rather than restricting to MMSE estimates. In such settings, the certainty equivalent policy is not optimal. For models where the cost and the dynamics are smooth in an appropriate sense, we derive upper bounds on the sub-optimality of certainty equivalent policies. We present several examples to illustrate the results.
Balance Equation-based Distributionally Robust Offline Imitation Learning
Nov 11, 2025Imitation Learning (IL) has proven highly effective for robotic and control tasks where manually designing reward functions or explicit controllers is infeasible. However, standard IL methods implicitly assume that the environment dynamics remain fixed between training and deployment. In practice, this assumption rarely holds where modeling inaccuracies, real-world parameter variations, and adversarial perturbations can all induce shifts in transition dynamics, leading to severe performance degradation. We address this challenge through Balance Equation-based Distributionally Robust Offline Imitation Learning, a framework that learns robust policies solely from expert demonstrations collected under nominal dynamics, without requiring further environment interaction. We formulate the problem as a distributionally robust optimization over an uncertainty set of transition models, seeking a policy that minimizes the imitation loss under the worst-case transition distribution. Importantly, we show that this robust objective can be reformulated entirely in terms of the nominal data distribution, enabling tractable offline learning. Empirical evaluations on continuous-control benchmarks demonstrate that our approach achieves superior robustness and generalization compared to state-of-the-art offline IL baselines, particularly under perturbed or shifted environments.
Markov Balance Satisfaction Improves Performance in Strictly Batch Offline Imitation Learning
Aug 17, 2024



Imitation learning (IL) is notably effective for robotic tasks where directly programming behaviors or defining optimal control costs is challenging. In this work, we address a scenario where the imitator relies solely on observed behavior and cannot make environmental interactions during learning. It does not have additional supplementary datasets beyond the expert's dataset nor any information about the transition dynamics. Unlike state-of-the-art (SOTA) IL methods, this approach tackles the limitations of conventional IL by operating in a more constrained and realistic setting. Our method uses the Markov balance equation and introduces a novel conditional density estimation-based imitation learning framework. It employs conditional normalizing flows for transition dynamics estimation and aims at satisfying a balance equation for the environment. Through a series of numerical experiments on Classic Control and MuJoCo environments, we demonstrate consistently superior empirical performance compared to many SOTA IL algorithms.
Pure Exploration for Constrained Best Mixed Arm Identification with a Fixed Budget
May 23, 2024
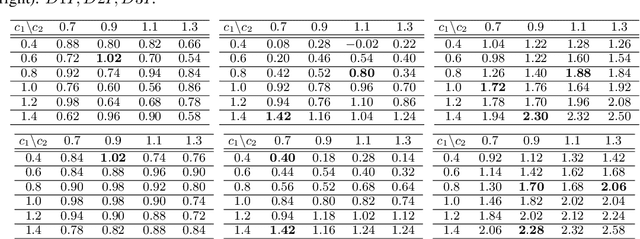
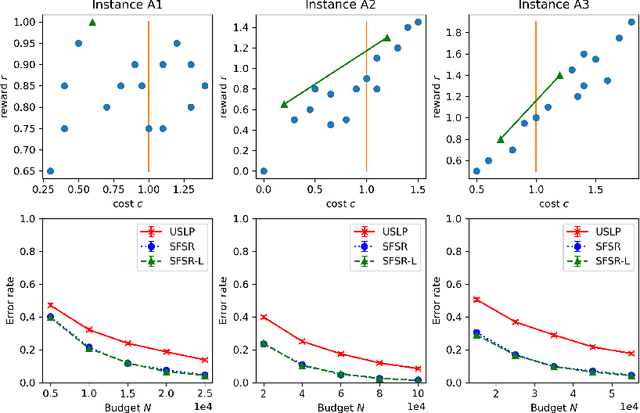
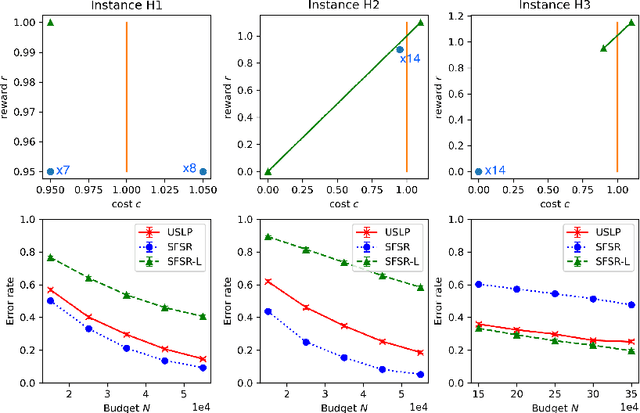
In this paper, we introduce the constrained best mixed arm identification (CBMAI) problem with a fixed budget. This is a pure exploration problem in a stochastic finite armed bandit model. Each arm is associated with a reward and multiple types of costs from unknown distributions. Unlike the unconstrained best arm identification problem, the optimal solution for the CBMAI problem may be a randomized mixture of multiple arms. The goal thus is to find the best mixed arm that maximizes the expected reward subject to constraints on the expected costs with a given learning budget $N$. We propose a novel, parameter-free algorithm, called the Score Function-based Successive Reject (SFSR) algorithm, that combines the classical successive reject framework with a novel score-function-based rejection criteria based on linear programming theory to identify the optimal support. We provide a theoretical upper bound on the mis-identification (of the the support of the best mixed arm) probability and show that it decays exponentially in the budget $N$ and some constants that characterize the hardness of the problem instance. We also develop an information theoretic lower bound on the error probability that shows that these constants appropriately characterize the problem difficulty. We validate this empirically on a number of average and hard instances.
Model approximation in MDPs with unbounded per-step cost
Feb 13, 2024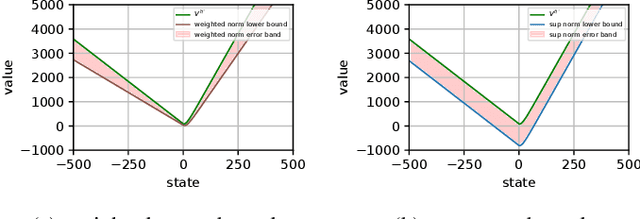
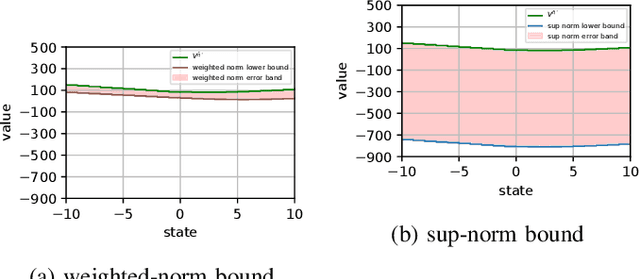

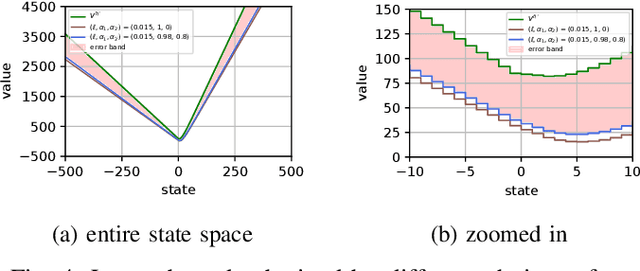
We consider the problem of designing a control policy for an infinite-horizon discounted cost Markov decision process $\mathcal{M}$ when we only have access to an approximate model $\hat{\mathcal{M}}$. How well does an optimal policy $\hat{\pi}^{\star}$ of the approximate model perform when used in the original model $\mathcal{M}$? We answer this question by bounding a weighted norm of the difference between the value function of $\hat{\pi}^\star $ when used in $\mathcal{M}$ and the optimal value function of $\mathcal{M}$. We then extend our results and obtain potentially tighter upper bounds by considering affine transformations of the per-step cost. We further provide upper bounds that explicitly depend on the weighted distance between cost functions and weighted distance between transition kernels of the original and approximate models. We present examples to illustrate our results.
Regret Analysis of the Posterior Sampling-based Learning Algorithm for Episodic POMDPs
Oct 16, 2023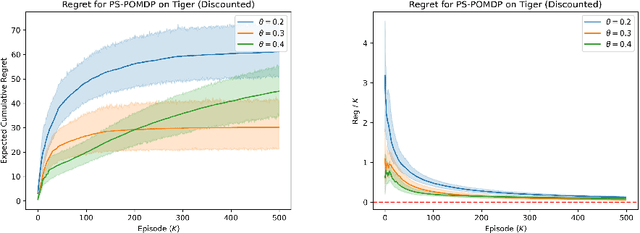


Compared to Markov Decision Processes (MDPs), learning in Partially Observable Markov Decision Processes (POMDPs) can be significantly harder due to the difficulty of interpreting observations. In this paper, we consider episodic learning problems in POMDPs with unknown transition and observation models. We consider the Posterior Sampling-based Reinforcement Learning (PSRL) algorithm for POMDPs and show that its Bayesian regret scales as the square root of the number of episodes. In general, the regret scales exponentially with the horizon length $H$, and we show that this is inevitable by providing a lower bound. However, under the condition that the POMDP is undercomplete and weakly revealing, we establish a polynomial Bayesian regret bound that improves the regret bound by a factor of $\Omega(H^2\sqrt{SA})$ over the recent result by arXiv:2204.08967.
Conditional Kernel Imitation Learning for Continuous State Environments
Aug 24, 2023

Imitation Learning (IL) is an important paradigm within the broader reinforcement learning (RL) methodology. Unlike most of RL, it does not assume availability of reward-feedback. Reward inference and shaping are known to be difficult and error-prone methods particularly when the demonstration data comes from human experts. Classical methods such as behavioral cloning and inverse reinforcement learning are highly sensitive to estimation errors, a problem that is particularly acute in continuous state space problems. Meanwhile, state-of-the-art IL algorithms convert behavioral policy learning problems into distribution-matching problems which often require additional online interaction data to be effective. In this paper, we consider the problem of imitation learning in continuous state space environments based solely on observed behavior, without access to transition dynamics information, reward structure, or, most importantly, any additional interactions with the environment. Our approach is based on the Markov balance equation and introduces a novel conditional kernel density estimation-based imitation learning framework. It involves estimating the environment's transition dynamics using conditional kernel density estimators and seeks to satisfy the probabilistic balance equations for the environment. We establish that our estimators satisfy basic asymptotic consistency requirements. Through a series of numerical experiments on continuous state benchmark environments, we show consistently superior empirical performance over many state-of-the-art IL algorithms.
Optimal Control of Logically Constrained Partially Observable and Multi-Agent Markov Decision Processes
May 24, 2023Autonomous systems often have logical constraints arising, for example, from safety, operational, or regulatory requirements. Such constraints can be expressed using temporal logic specifications. The system state is often partially observable. Moreover, it could encompass a team of multiple agents with a common objective but disparate information structures and constraints. In this paper, we first introduce an optimal control theory for partially observable Markov decision processes (POMDPs) with finite linear temporal logic constraints. We provide a structured methodology for synthesizing policies that maximize a cumulative reward while ensuring that the probability of satisfying a temporal logic constraint is sufficiently high. Our approach comes with guarantees on approximate reward optimality and constraint satisfaction. We then build on this approach to design an optimal control framework for logically constrained multi-agent settings with information asymmetry. We illustrate the effectiveness of our approach by implementing it on several case studies.
A Novel Point-based Algorithm for Multi-agent Control Using the Common Information Approach
Apr 10, 2023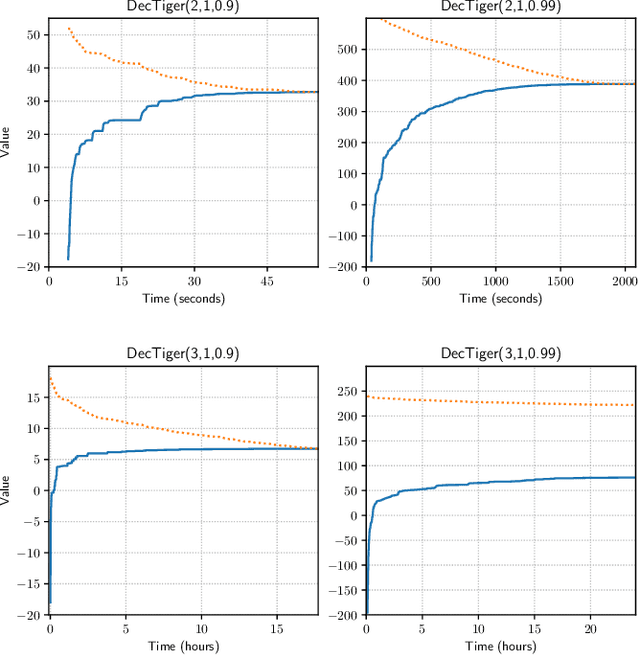
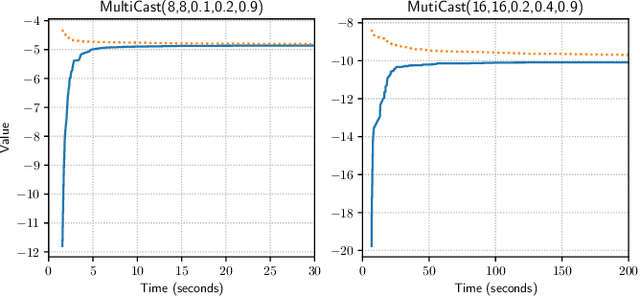
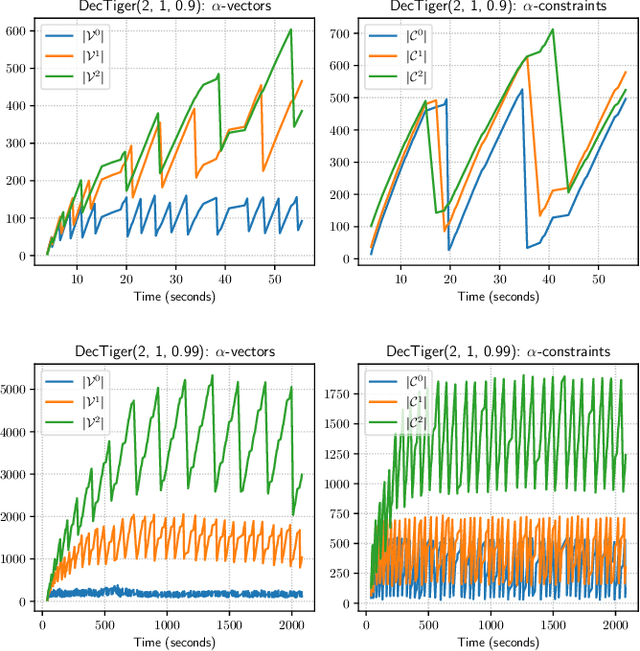
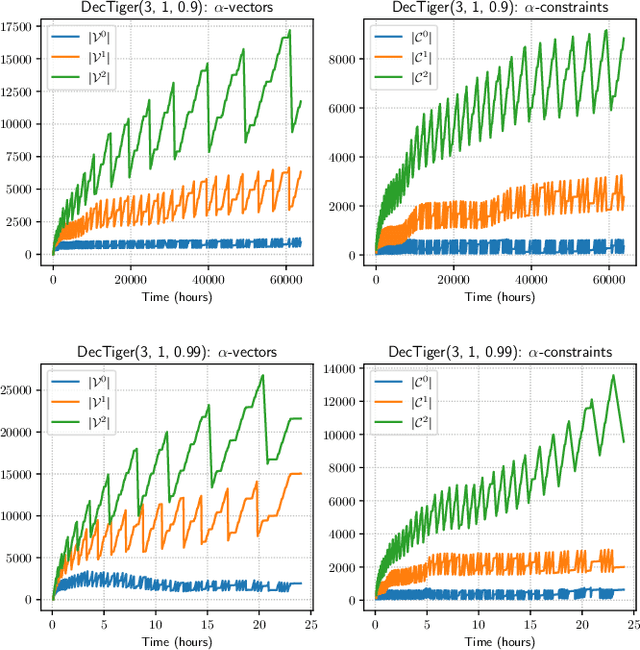
The Common Information (CI) approach provides a systematic way to transform a multi-agent stochastic control problem to a single-agent partially observed Markov decision problem (POMDP) called the coordinator's POMDP. However, such a POMDP can be hard to solve due to its extraordinarily large action space. We propose a new algorithm for multi-agent stochastic control problems, called coordinator's heuristic search value iteration (CHSVI), that combines the CI approach and point-based POMDP algorithms for large action spaces. We demonstrate the algorithm through optimally solving several benchmark problems.