 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimal Control of Logically Constrained Partially Observable and Multi-Agent Markov Decision Processes
May 24, 2023Autonomous systems often have logical constraints arising, for example, from safety, operational, or regulatory requirements. Such constraints can be expressed using temporal logic specifications. The system state is often partially observable. Moreover, it could encompass a team of multiple agents with a common objective but disparate information structures and constraints. In this paper, we first introduce an optimal control theory for partially observable Markov decision processes (POMDPs) with finite linear temporal logic constraints. We provide a structured methodology for synthesizing policies that maximize a cumulative reward while ensuring that the probability of satisfying a temporal logic constraint is sufficiently high. Our approach comes with guarantees on approximate reward optimality and constraint satisfaction. We then build on this approach to design an optimal control framework for logically constrained multi-agent settings with information asymmetry. We illustrate the effectiveness of our approach by implementing it on several case studies.
Adaptive Sampling for Estimating Distributions: A Bayesian Upper Confidence Bound Approach
Dec 08, 2020
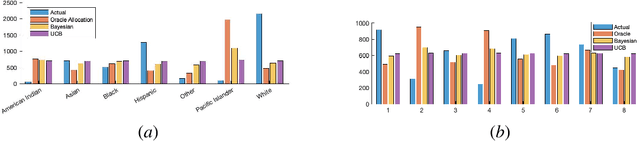

The problem of adaptive sampling for estimating probability mass functions (pmf) uniformly well is considered. Performance of the sampling strategy is measured in terms of the worst-case mean squared error. A Bayesian variant of the existing upper confidence bound (UCB) based approaches is proposed. It is shown analytically that the performance of this Bayesian variant is no worse than the existing approaches. The posterior distribution on the pmfs in the Bayesian setting allows for a tighter computation of upper confidence bounds which leads to significant performance gains in practice. Using this approach, adaptive sampling protocols are proposed for estimating SARS-CoV-2 seroprevalence in various groups such as location and ethnicity. The effectiveness of this strategy is discussed using data obtained from a seroprevalence survey in Los Angeles county.
Sequential Experiment Design for Hypothesis Verification
Dec 04, 2018


Hypothesis testing is an important problem with applications in target localization, clinical trials etc. Many active hypothesis testing strategies operate in two phases: an exploration phase and a verification phase. In the exploration phase, selection of experiments is such that a moderate level of confidence on the true hypothesis is achieved. Subsequent experiment design aims at improving the confidence level on this hypothesis to the desired level. In this paper, the focus is on the verification phase. A confidence measure is defined and active hypothesis testing is formulated as a confidence maximization problem in an infinite-horizon average-reward Partially Observable Markov Decision Process (POMDP) setting. The problem of maximizing confidence conditioned on a particular hypothesis is referred to as the hypothesis verification problem. The relationship between hypothesis testing and verification problems is established. The verification problem can be formulated as a Markov Decision Process (MDP). Optimal solutions for the verification MDP are characterized and a simple heuristic adaptive strategy for verification is proposed based on a zero-sum game interpretation of Kullback-Leibler divergences. It is demonstrated through numerical experiments that the heuristic performs better in some scenarios compared to existing methods in literature.
Policy Design for Active Sequential Hypothesis Testing using Deep Learning
Oct 11, 2018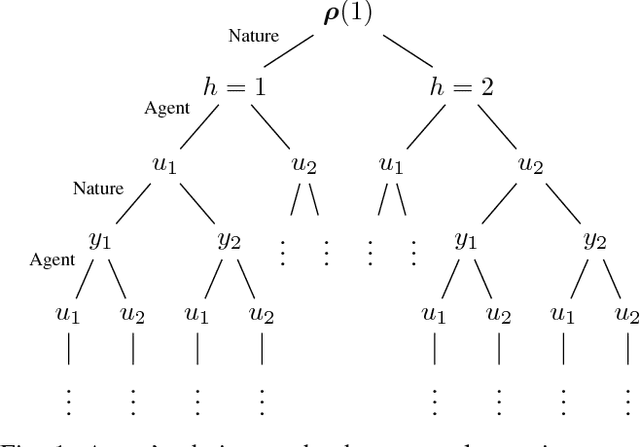
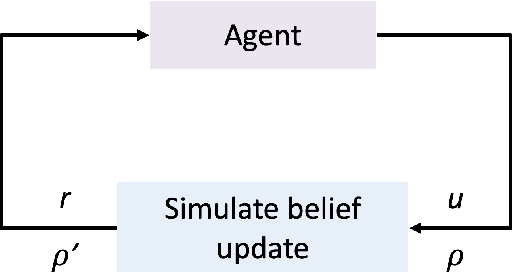
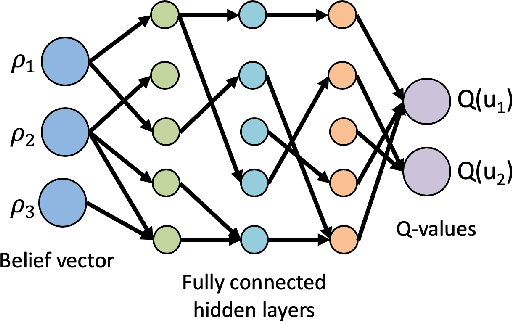
Information theory has been very successful in obtaining performance limits for various problems such as communication, compression and hypothesis testing. Likewise, stochastic control theory provides a characterization of optimal policies for Partially Observable Markov Decision Processes (POMDPs) using dynamic programming. However, finding optimal policies for these problems is computationally hard in general and thus, heuristic solutions are employed in practice. Deep learning can be used as a tool for designing better heuristics in such problems. In this paper, the problem of active sequential hypothesis testing is considered. The goal is to design a policy that can reliably infer the true hypothesis using as few samples as possible by adaptively selecting appropriate queries. This problem can be modeled as a POMDP and bounds on its value function exist in literature. However, optimal policies have not been identified and various heuristics are used. In this paper, two new heuristics are proposed: one based on deep reinforcement learning and another based on a KL-divergence zero-sum game. These heuristics are compared with state-of-the-art solutions and it is demonstrated using numerical experiments that the proposed heuristics can achieve significantly better performance than existing methods in some scenarios.