 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDraft-and-Prune: Improving the Reliability of Auto-formalization for Logical Reasoning
Mar 18, 2026Auto-formalization (AF) translates natural-language reasoning problems into solver-executable programs, enabling symbolic solvers to perform sound logical deduction. In practice, however, AF pipelines are currently brittle: programs may fail to execute, or execute but encode incorrect semantics. While prior work largely mitigates syntactic failures via repairs based on solver feedback, reducing semantics failures remains a major bottleneck. We propose Draft-and-Prune (D&P), an inference-time framework that improves AF-based logical reasoning via diversity and verification. D&P first drafts multiple natural-language plans and conditions program generation on them. It further prunes executable but contradictory or ambiguous formalizations, and aggregates predictions from surviving paths via majority voting. Across four representative benchmarks (AR-LSAT, ProofWriter, PrOntoQA, LogicalDeduction), D&P substantially strengthens AF-based reasoning without extra supervision. On AR-LSAT, in the AF-only setting, D&P achieves 78.43% accuracy with GPT-4 and 78.00% accuracy with GPT-4o, significantly outperforming the strongest AF baselines MAD-LOGIC and CLOVER. D&P then attains near-ceiling performance on the other benchmarks, including 100% on PrOntoQA and LogicalDeduction.
Systematic Evaluation of Knowledge Graph Repair with Large Language Models
Jul 30, 2025We present a systematic approach for evaluating the quality of knowledge graph repairs with respect to constraint violations defined in shapes constraint language (SHACL). Current evaluation methods rely on \emph{ad hoc} datasets, which limits the rigorous analysis of repair systems in more general settings. Our method addresses this gap by systematically generating violations using a novel mechanism, termed violation-inducing operations (VIOs). We use the proposed evaluation framework to assess a range of repair systems which we build using large language models. We analyze the performance of these systems across different prompting strategies. Results indicate that concise prompts containing both the relevant violated SHACL constraints and key contextual information from the knowledge graph yield the best performance.
Pure Exploration for Constrained Best Mixed Arm Identification with a Fixed Budget
May 23, 2024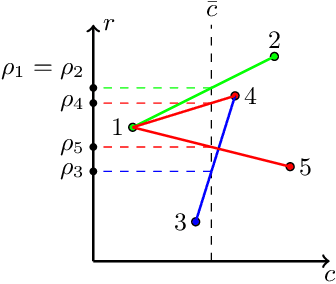
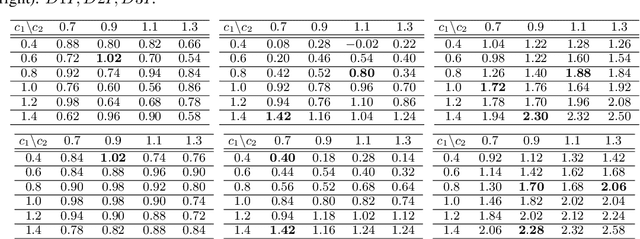
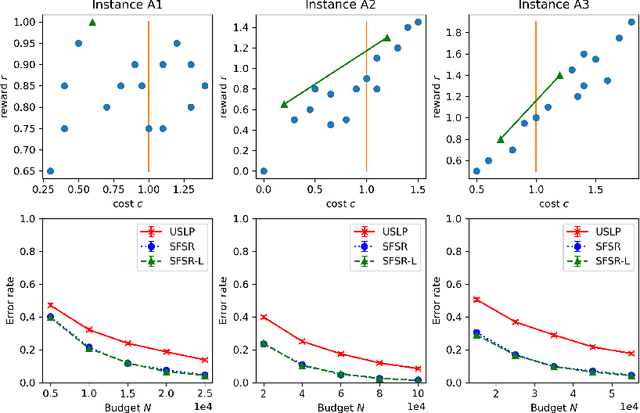
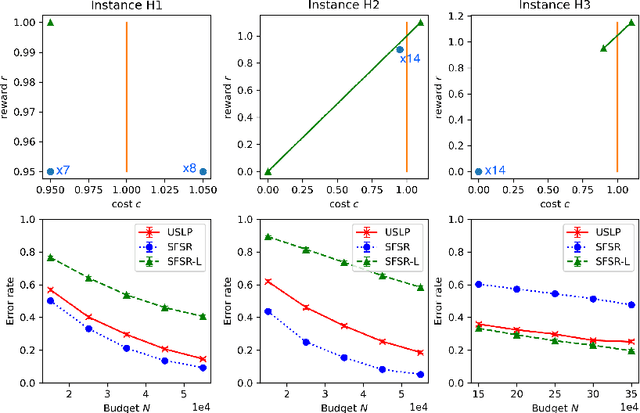
In this paper, we introduce the constrained best mixed arm identification (CBMAI) problem with a fixed budget. This is a pure exploration problem in a stochastic finite armed bandit model. Each arm is associated with a reward and multiple types of costs from unknown distributions. Unlike the unconstrained best arm identification problem, the optimal solution for the CBMAI problem may be a randomized mixture of multiple arms. The goal thus is to find the best mixed arm that maximizes the expected reward subject to constraints on the expected costs with a given learning budget $N$. We propose a novel, parameter-free algorithm, called the Score Function-based Successive Reject (SFSR) algorithm, that combines the classical successive reject framework with a novel score-function-based rejection criteria based on linear programming theory to identify the optimal support. We provide a theoretical upper bound on the mis-identification (of the the support of the best mixed arm) probability and show that it decays exponentially in the budget $N$ and some constants that characterize the hardness of the problem instance. We also develop an information theoretic lower bound on the error probability that shows that these constants appropriately characterize the problem difficulty. We validate this empirically on a number of average and hard instances.
Sparse but Strong: Crafting Adversarially Robust Graph Lottery Tickets
Dec 11, 2023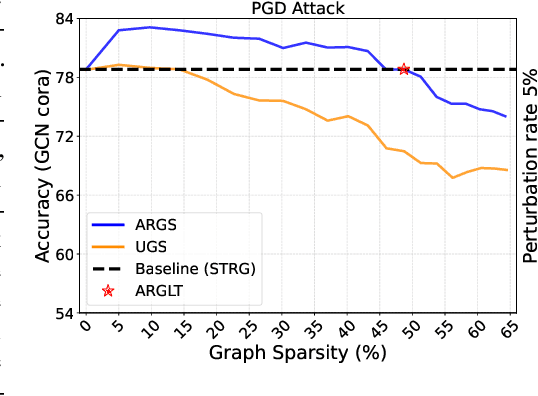

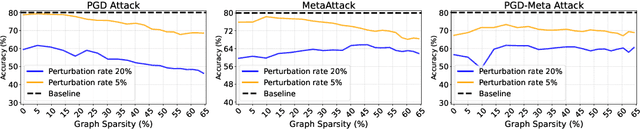

Graph Lottery Tickets (GLTs), comprising a sparse adjacency matrix and a sparse graph neural network (GNN), can significantly reduce the inference latency and compute footprint compared to their dense counterparts. Despite these benefits, their performance against adversarial structure perturbations remains to be fully explored. In this work, we first investigate the resilience of GLTs against different structure perturbation attacks and observe that they are highly vulnerable and show a large drop in classification accuracy. Based on this observation, we then present an adversarially robust graph sparsification (ARGS) framework that prunes the adjacency matrix and the GNN weights by optimizing a novel loss function capturing the graph homophily property and information associated with both the true labels of the train nodes and the pseudo labels of the test nodes. By iteratively applying ARGS to prune both the perturbed graph adjacency matrix and the GNN model weights, we can find adversarially robust graph lottery tickets that are highly sparse yet achieve competitive performance under different untargeted training-time structure attacks. Evaluations conducted on various benchmarks, considering different poisoning structure attacks, namely, PGD, MetaAttack, Meta-PGD, and PR-BCD demonstrate that the GLTs generated by ARGS can significantly improve the robustness, even when subjected to high levels of sparsity.
Regret Analysis of the Posterior Sampling-based Learning Algorithm for Episodic POMDPs
Oct 16, 2023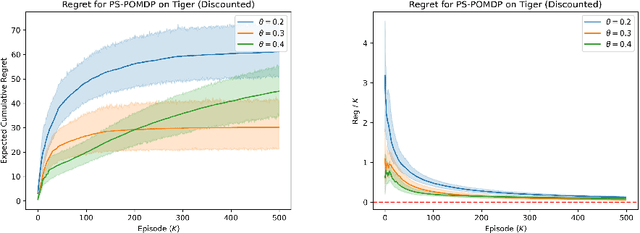


Compared to Markov Decision Processes (MDPs), learning in Partially Observable Markov Decision Processes (POMDPs) can be significantly harder due to the difficulty of interpreting observations. In this paper, we consider episodic learning problems in POMDPs with unknown transition and observation models. We consider the Posterior Sampling-based Reinforcement Learning (PSRL) algorithm for POMDPs and show that its Bayesian regret scales as the square root of the number of episodes. In general, the regret scales exponentially with the horizon length $H$, and we show that this is inevitable by providing a lower bound. However, under the condition that the POMDP is undercomplete and weakly revealing, we establish a polynomial Bayesian regret bound that improves the regret bound by a factor of $\Omega(H^2\sqrt{SA})$ over the recent result by arXiv:2204.08967.
Correct-by-Construction Design of Contextual Robotic Missions Using Contracts
Jun 13, 2023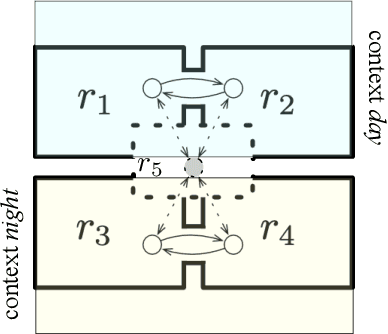
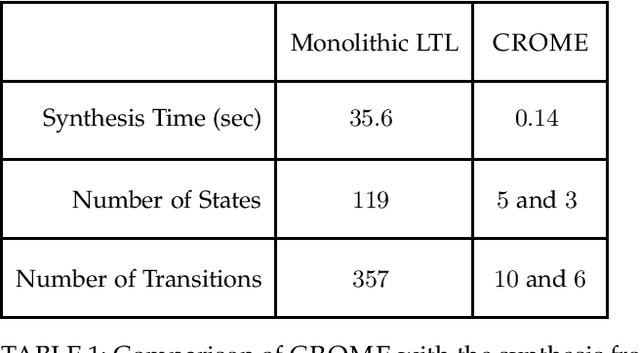
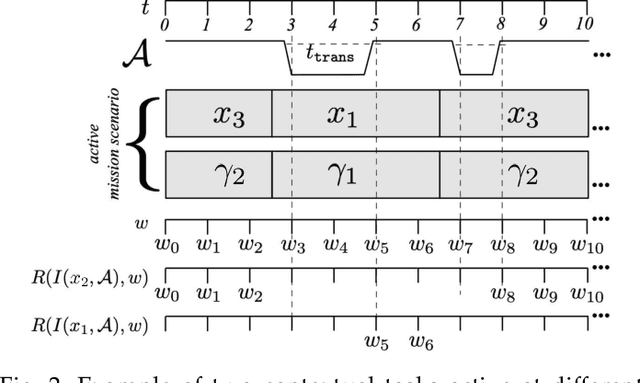
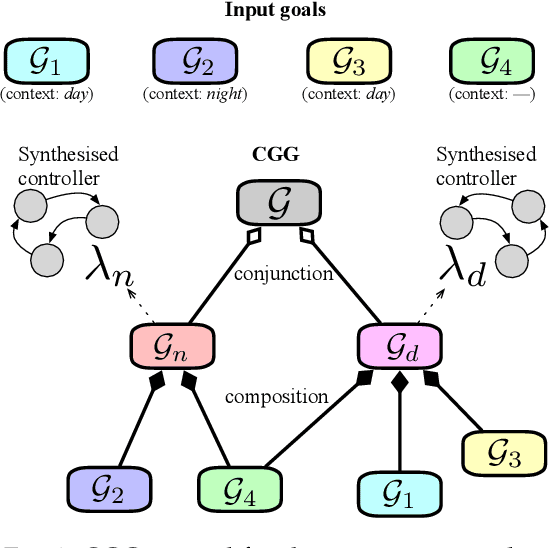
Effectively specifying and implementing robotic missions pose a set of challenges to software engineering for robotic systems, since they require formalizing and executing a robot's high-level tasks while considering various application scenarios and conditions, also known as contexts, in real-world operational environments. Writing correct mission specifications that explicitly account for multiple contexts can be a tedious and error-prone task. Moreover, as the number of context, hence the specification, becomes more complex, generating a correct-by-construction implementation, e.g., by using synthesis methods, can become intractable. A viable approach to address these issues is to decompose the mission specification into smaller sub-missions, with each sub-mission corresponding to a specific context. However, such a compositional approach would still pose challenges in ensuring the overall mission correctness. In this paper, we propose a new, compositional framework for the specification and implementation of contextual robotic missions using assume-guarantee contracts. The mission specification is captured in a hierarchical and modular way and each sub-mission is synthesized as a robot controller. We address the problem of dynamically switching between sub-mission controllers while ensuring correctness under certain conditions.
Optimal Control of Logically Constrained Partially Observable and Multi-Agent Markov Decision Processes
May 24, 2023Autonomous systems often have logical constraints arising, for example, from safety, operational, or regulatory requirements. Such constraints can be expressed using temporal logic specifications. The system state is often partially observable. Moreover, it could encompass a team of multiple agents with a common objective but disparate information structures and constraints. In this paper, we first introduce an optimal control theory for partially observable Markov decision processes (POMDPs) with finite linear temporal logic constraints. We provide a structured methodology for synthesizing policies that maximize a cumulative reward while ensuring that the probability of satisfying a temporal logic constraint is sufficiently high. Our approach comes with guarantees on approximate reward optimality and constraint satisfaction. We then build on this approach to design an optimal control framework for logically constrained multi-agent settings with information asymmetry. We illustrate the effectiveness of our approach by implementing it on several case studies.
Exact and Cost-Effective Automated Transformation of Neural Network Controllers to Decision Tree Controllers
Apr 11, 2023Over the past decade, neural network (NN)-based controllers have demonstrated remarkable efficacy in a variety of decision-making tasks. However, their black-box nature and the risk of unexpected behaviors and surprising results pose a challenge to their deployment in real-world systems with strong guarantees of correctness and safety. We address these limitations by investigating the transformation of NN-based controllers into equivalent soft decision tree (SDT)-based controllers and its impact on verifiability. Differently from previous approaches, we focus on discrete-output NN controllers including rectified linear unit (ReLU) activation functions as well as argmax operations. We then devise an exact but cost-effective transformation algorithm, in that it can automatically prune redundant branches. We evaluate our approach using two benchmarks from the OpenAI Gym environment. Our results indicate that the SDT transformation can benefit formal verification, showing runtime improvements of up to 21x and 2x for MountainCar-v0 and CartPole-v0, respectively.
Safe Posterior Sampling for Constrained MDPs with Bounded Constraint Violation
Jan 27, 2023Constrained Markov decision processes (CMDPs) model scenarios of sequential decision making with multiple objectives that are increasingly important in many applications. However, the model is often unknown and must be learned online while still ensuring the constraint is met, or at least the violation is bounded with time. Some recent papers have made progress on this very challenging problem but either need unsatisfactory assumptions such as knowledge of a safe policy, or have high cumulative regret. We propose the Safe PSRL (posterior sampling-based RL) algorithm that does not need such assumptions and yet performs very well, both in terms of theoretical regret bounds as well as empirically. The algorithm achieves an efficient tradeoff between exploration and exploitation by use of the posterior sampling principle, and provably suffers only bounded constraint violation by leveraging the idea of pessimism. Our approach is based on a primal-dual approach. We establish a sub-linear $\tilde{\mathcal{ O}}\left(H^{2.5} \sqrt{|\mathcal{S}|^2 |\mathcal{A}| K} \right)$ upper bound on the Bayesian reward objective regret along with a bounded, i.e., $\tilde{\mathcal{O}}\left(1\right)$ constraint violation regret over $K$ episodes for an $|\mathcal{S}|$-state, $|\mathcal{A}|$-action and horizon $H$ CMDP.
Contract-Based Specification Refinement and Repair for Mission Planning
Nov 21, 2022

We address the problem of modeling, refining, and repairing formal specifications for robotic missions using assume-guarantee contracts. We show how to model mission specifications at various levels of abstraction and implement them using a library of pre-implemented specifications. Suppose the specification cannot be met using components from the library. In that case, we compute a proxy for the best approximation to the specification that can be generated using elements from the library. Afterward, we propose a systematic way to either 1) search for and refine the `missing part' of the specification that the library cannot meet or 2) repair the current specification such that the existing library can refine it. Our methodology for searching and repairing mission requirements leverages the quotient, separation, composition, and merging operations between contracts.