 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDefenses Against Prompt Attacks Learn Surface Heuristics
Jan 12, 2026Large language models (LLMs) are increasingly deployed in security-sensitive applications, where they must follow system- or developer-specified instructions that define the intended task behavior, while completing benign user requests. When adversarial instructions appear in user queries or externally retrieved content, models may override intended logic. Recent defenses rely on supervised fine-tuning with benign and malicious labels. Although these methods achieve high attack rejection rates, we find that they rely on narrow correlations in defense data rather than harmful intent, leading to systematic rejection of safe inputs. We analyze three recurring shortcut behaviors induced by defense fine-tuning. \emph{Position bias} arises when benign content placed later in a prompt is rejected at much higher rates; across reasoning benchmarks, suffix-task rejection rises from below \textbf{10\%} to as high as \textbf{90\%}. \emph{Token trigger bias} occurs when strings common in attack data raise rejection probability even in benign contexts; inserting a single trigger token increases false refusals by up to \textbf{50\%}. \emph{Topic generalization bias} reflects poor generalization beyond the defense data distribution, with defended models suffering test-time accuracy drops of up to \textbf{40\%}. These findings suggest that current prompt-injection defenses frequently respond to attack-like surface patterns rather than the underlying intent. We introduce controlled diagnostic datasets and a systematic evaluation across two base models and multiple defense pipelines, highlighting limitations of supervised fine-tuning for reliable LLM security.
Let Me Grok for You: Accelerating Grokking via Embedding Transfer from a Weaker Model
Apr 17, 2025''Grokking'' is a phenomenon where a neural network first memorizes training data and generalizes poorly, but then suddenly transitions to near-perfect generalization after prolonged training. While intriguing, this delayed generalization phenomenon compromises predictability and efficiency. Ideally, models should generalize directly without delay. To this end, this paper proposes GrokTransfer, a simple and principled method for accelerating grokking in training neural networks, based on the key observation that data embedding plays a crucial role in determining whether generalization is delayed. GrokTransfer first trains a smaller, weaker model to reach a nontrivial (but far from optimal) test performance. Then, the learned input embedding from this weaker model is extracted and used to initialize the embedding in the target, stronger model. We rigorously prove that, on a synthetic XOR task where delayed generalization always occurs in normal training, GrokTransfer enables the target model to generalize directly without delay. Moreover, we demonstrate that, across empirical studies of different tasks, GrokTransfer effectively reshapes the training dynamics and eliminates delayed generalization, for both fully-connected neural networks and Transformers.
Secure On-Device Video OOD Detection Without Backpropagation
Mar 08, 2025Out-of-Distribution (OOD) detection is critical for ensuring the reliability of machine learning models in safety-critical applications such as autonomous driving and medical diagnosis. While deploying personalized OOD detection directly on edge devices is desirable, it remains challenging due to large model sizes and the computational infeasibility of on-device training. Federated learning partially addresses this but still requires gradient computation and backpropagation, exceeding the capabilities of many edge devices. To overcome these challenges, we propose SecDOOD, a secure cloud-device collaboration framework for efficient on-device OOD detection without requiring device-side backpropagation. SecDOOD utilizes cloud resources for model training while ensuring user data privacy by retaining sensitive information on-device. Central to SecDOOD is a HyperNetwork-based personalized parameter generation module, which adapts cloud-trained models to device-specific distributions by dynamically generating local weight adjustments, effectively combining central and local information without local fine-tuning. Additionally, our dynamic feature sampling and encryption strategy selectively encrypts only the most informative feature channels, largely reducing encryption overhead without compromising detection performance. Extensive experiments across multiple datasets and OOD scenarios demonstrate that SecDOOD achieves performance comparable to fully fine-tuned models, enabling secure, efficient, and personalized OOD detection on resource-limited edge devices. To enhance accessibility and reproducibility, our code is publicly available at https://github.com/Dystopians/SecDOOD.
Sparse but Strong: Crafting Adversarially Robust Graph Lottery Tickets
Dec 11, 2023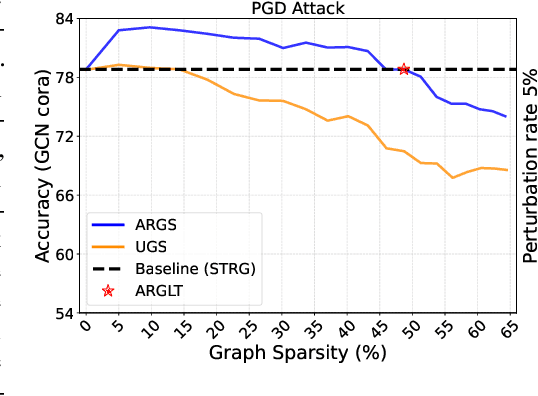

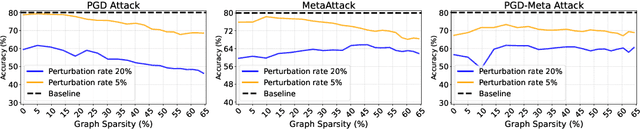

Graph Lottery Tickets (GLTs), comprising a sparse adjacency matrix and a sparse graph neural network (GNN), can significantly reduce the inference latency and compute footprint compared to their dense counterparts. Despite these benefits, their performance against adversarial structure perturbations remains to be fully explored. In this work, we first investigate the resilience of GLTs against different structure perturbation attacks and observe that they are highly vulnerable and show a large drop in classification accuracy. Based on this observation, we then present an adversarially robust graph sparsification (ARGS) framework that prunes the adjacency matrix and the GNN weights by optimizing a novel loss function capturing the graph homophily property and information associated with both the true labels of the train nodes and the pseudo labels of the test nodes. By iteratively applying ARGS to prune both the perturbed graph adjacency matrix and the GNN model weights, we can find adversarially robust graph lottery tickets that are highly sparse yet achieve competitive performance under different untargeted training-time structure attacks. Evaluations conducted on various benchmarks, considering different poisoning structure attacks, namely, PGD, MetaAttack, Meta-PGD, and PR-BCD demonstrate that the GLTs generated by ARGS can significantly improve the robustness, even when subjected to high levels of sparsity.